Подробно об объектах и классах в PHP
Сегодня объекты используются очень активно, хотя это трудно было предположить после выхода PHP 5 в 2005 году. Тогда я ещё мало что знал о возможностях этого языка. Пятую версию PHP сравнивали с предыдущей, четвёртой, и главным преимуществом нового релиза стала новая, очень мощная объектная модель. И сегодня, десять лет спустя, около 90% всего PHP-кода содержит объекты, не изменившиеся со времени PHP 5.0. Это убедительно говорит о том, какую роль сыграло внедрение объектной модели, неоднократно улучшавшейся на протяжении последующих лет. В этом посте я хотел бы рассказать о том, как всё устроено «под капотом». Чтобы люди понимали суть процессов — почему сделано так, а не иначе — и лучше, полнее использовали возможности языка. Также я затрону тему использования памяти объектами, в том числе в сравнении с эквивалентными массивами (когда это возможно).
Я буду рассказывать на примере версии PHP 5.4, и описываемые мной вещи справедливы для 5.5 и 5.6, потому что устройство объектной модели там почти не претерпело изменений. Обратите внимание, что в версии 5.3 всё не так хорошо с точки зрения возможностей и общей производительности.
В PHP 7, который пока ещё активно разрабатывается, объектная модель переработана не сильно, были внесены лишь незначительные изменения. Просто потому что всё и так хорошо работает, а лучшее — враг хорошего. Были добавлены возможности, не затрагивающие ядро, но здесь об этом речи не пойдёт.
В качестве демонстрации начну с синтетических бенчмарков:
Здесь объявляется простой класс с тремя атрибутами, а затем в цикле создаётся 1000 объектов этого класса. Обратите внимание, как в этом примере используется память: при создании объекта класса Foo и переменной для его хранения выделяется 262 байт динамической памяти PHP.
Давайте заменим объект на эквивалентный массив:
Вот ещё один пример:
Теперь давайте разберём, как всё это устроено в недрах PHP, подкрепив теорией практические наблюдения.
Всё начинается с классов
Внутри PHP класс представляется с помощью структуры zend_class_entry:
Важно знать ещё об одном моменте, связанном с zend_class_entry — о PHP-комментариях. Они также известны как аннотации. Это строковые переменные (в языке С — буферы char* ), которые тоже надо разместить в памяти. Для языка С, не использующего Unicode, в отличие от PHP, правило очень простое: один символ = один байт. Чем больше у вас в классе аннотаций, тем больше памяти будет использовано после парсинга.
У zend_class_entry поле doc_comment содержит аннотации класса. У методов и атрибутов тоже есть такое поле.
Пользовательские и внутренние классы
Пользовательский класс — это класс, заданный с помощью PHP, а внутренний класс задаётся либо благодаря внедрению исходного кода в сам PHP, либо с помощью расширения. Самое большое различие между этими двумя видами классов заключается в том, что пользовательские классы оперируют памятью, выделяемой по запросу, а внутренние — «постоянной» памятью.
Это означает, что когда PHP заканчивает обработку текущего HTTP-запроса, он убирает из памяти и уничтожает все пользовательские классы, готовясь к обработке следующего запроса. Этот подход известен под названием «архитектура без разделения ресурсов» (the share nothing architecture). Так было заложено в PHP с самого начала, и изменять это пока не планируется.
Итак, каждый раз при формировании запроса и парсинге классов происходит выделение памяти для них. После использования класса уничтожается всё, что с ним связано. Так что обязательно используйте все объявленные классы, в противном случае будет теряться память. Применяйте автозагрузчики, они задерживают парсинг/объявление во время выполнения, когда PHP нужно задействовать класс. Несмотря на замедление выполнения, автозагрузчик позволяет грамотно использовать память, поскольку он не будет запущен, пока действительно не возникнет потребность в классе.
С внутренними классами всё иначе. Они размещаются в памяти постоянно, вне зависимости от того, использовали их или нет. То есть они уничтожаются только тогда, когда прекращается работа самого PHP — после завершения обработки всех запросов (подразумеваются веб SAPI, например, PHP-FPM). Поэтому внутренние классы более эффективны, чем пользовательские (в конце запроса уничтожаются только статические атрибуты, больше ничего).
Обратите внимание, что даже при кешировании опкодов, как OPCache, создание и уничтожение класса осуществляется при каждом запросе, как и в случае с пользовательскими классами. OPCache просто ускоряет оба этих процесса.
Как вы заметили, если активировать много PHP-расширений, каждое из которых объявляет много классов, но при этом использовать лишь небольшое их количество, то теряется память. Помните, что PHP-расширения объявляют классы во время запуска PHP, даже если в последующих запросах эти классы использоваться не будут. Поэтому не рекомендуется держать расширения активными, если они не применяются в данный момент, иначе вы будете терять память. Особенно если эти расширения объявляют много классов — хотя они могут забить память и чем-нибудь другим.
Классы, интерфейсы или трейты — без разницы
Не слишком хорошо, что здесь используется 912 байт всего лишь для декларирования интерфейса BarException.
Привязка класса
Многие разработчики не вспоминают о привязке класса, пока не начинают задавать вопросом, а как же всё устроено на самом деле. Привязку класса можно описать как «процесс, в ходе которого сам класс и все связанные с ним данные подготавливаются для полноценного использования разработчиком». Этот процесс очень прост и не требует много ресурсов, если речь идёт о каком-то одном классе, не дополняющем другой, не использующем трейты и не внедряющим интерфейс. Процесс привязки для таких классов полностью протекает во время компиляции, а в ходе выполнения ресурсы на это уже не тратятся. Обратите внимание, что речь шла привязке класса, задекларированного пользователем. Для внутренних классов тот же самый процесс выполняется, когда классы зарегистрированы ядром или расширениями PHP, как раз перед запуском пользовательских скриптов — и делается это лишь один раз за всё время работы PHP.
Всё сильно усложняется, если речь заходит о внедрении интерфейсов или наследовании классов. Тогда в ходе привязки класса у родительских и дочерних объектов (будь то классы или интерфейсы) копируется абсолютно все.
Тут добавить нечего, простой случай.
Для каждой из таблиц функций (методов) используется do_inherit_method :
Что касается наследования, то здесь, в принципе, всё то же самое, что и при внедрении интерфейса. Только вовлечено ещё больше «участников». Но хочу отметить, что если PHP уже знает о классе, то привязка осуществляется во время компилирования, а если не знает — то во время выполнения. Так что лучше объявлять так:
Кстати, рутинная процедура привязки класса может привести к очень странному поведению:
В первом варианте привязка класса В отложена на время выполнения, потому что когда компилятор доходит до объявления этого класса, он ещё ничего не знает о классе А. Когда начинается выполнение, то привязка класса А происходит без вопросов, потому что он уже скомпилирован, будучи одиночным классом. Во втором случае всё иначе. Привязка класса С отложена на время выполнения, потому что компилятор ещё ничего не знает о В, пытаясь скомпилировать его. Но когда во время выполнения начинается привязка класса С, то он ищет В, который не существует, поскольку не скомпилирован по причине того, что В является дополнением. Вылетает сообщение “Class B doesn’t exist”.
Объекты
Итак, теперь мы знаем, что:
Теперь поговорим об объектах. В первой главе показано, что создание «классического» объекта («классического» пользовательского класса) потребовало очень мало памяти, около 200 байт. Всё дело в классе. Дальнейшая компиляция класса тоже потребляет память, но это к лучшему, потому что для создания одиночного объекта требуется меньше байт. По сути, объект представляет собой крохотный набор из крохотных структур.
Управление методами объекта
Вы могли заметить интересную вещь, посмотрите на первые строки:
Во время компиляции функции/метода происходит немедленный перевод в нижний регистр. Вышеприведённая функция BAR() превращается в bar() компилятором при добавлении метода таблице классов и функций.
В приведённом примере первый вызов статический: компилятор вычислил key для строковой “bar”, а когда приходит время вызова метода, ему нужно делать меньше работы. Второй вызов уже динамический, компилятор ничего не знает о “$b”, не может вычислить key для вызова метода. Затем, во время выполнения, нам придётся перевести строковую в нижний регистр и вычислить её хеш ( zend_hash_func() ), что не лучшим образом сказывается на производительности.
Управление атрибутами объекта
Вот что происходит:

Так что, создавая объект, мы «всего лишь» создаём структуру zend_object весом 32 байта:
Далее движок создаёт вектор признаков нашего объекта:
Вероятно, у вас возникли два вопроса:
Пока вы не пишете в объект, его потребление памяти не меняется. После записи он занимает уже больше места (пока не будет уничтожен), поскольку содержит все записанные в него атрибуты.
Объекты, ведущие себя как ссылки благодаря хранилищу объектов
Объекты не являются ссылками. Это демонстрируется на маленьком скрипте:
Все сейчас скажут, что «в PHP 5 объекты являются ссылками», об этом упоминает даже официальный мануал. Технически это совершенно неверно. Тем не менее, объекты могут вести себя так же, как и ссылки. Например, когда вы передаёте переменную, являющуюся объектом функции, эта функция может модифицировать тот же объект.
object(MyClass)#1 (0) < >/* #1 is the object handle (number), it is unique */
Когда мы вызываем метод, движок изменяет область видимости:
Вот так можно получать доступ к приватным членам объектов, не принадлежащим вам, но являющимся дочерними по отношению к вашей текущей области видимости:
Эта особенность стала причиной большого количества баг-репортов от разработчиков. Но так устроена объектная модель в PHP — на самом деле, мы задаём область видимости на основе не объекта, а класса. В случае с нашим классом “Foo”, вы можете работать с любым приватным Foo любого другого Foo, как показано выше.
О деструкторе
Деструкторы опасны, не полагайтесь на них, поскольку PHP их не вызывает даже в случае фатальной ошибки:
А что насчёт порядка вызова деструкторов в том случае, если они всё-таки вызываются? Ответ хорошо виден в коде:
Здесь продемонстрированы три стадии вызова деструктора:
PHP не вызывает деструкторы в случае возникновения какой-либо фатальной ошибки. Дело в том, что в этом случае Zend работает нестабильно, а вызов деструкторов приводит к выполнению пользовательского кода, который может получить доступ к ошибочным указателям и, в результате, к падению PHP. Уж лучше сохранять стабильность системы — поэтому вызов деструкторов и блокируется. Возможно, в PHP 7 что-то и поменяется.
Суммируя вышесказанное: не доверяйте деструкторам критически важный код, например, управление механизмом блокировки (lock mechanism), поскольку PHP может и не вызвать деструктор или вызвать его в неконтролируемой последовательности. Если всё-таки важный код обрабатывается деструктором, то как минимум самостоятельно контролируйте жизненный цикл объектов. PHP вызовет деструктор, когда refcount вашего объекта упадёт до нуля, а это значит, что объект больше не используется и его можно безопасно уничтожить.
Новый PHP, часть 2: Scalar types

В нашей предыдущей статье мы говорили о преимуществах системы типов PHP 7, и в частности, о новой поддержке типизированных возвращаемых значений. Что само по себе является не только большим подспорьем в поддержке кода, но делает для PHP большой шаг вперед.
Также как и типы возвращаемых значений, скаляры увеличивают ясность кода, дают возможность поймать больше ошибок на раннем этапе. Что, в свою очередь, повышает надежность кода.
Изменения коснулись некоторых методов, отдающих строку или число. Даже сделав такой простой шаг, мы уже получили некоторые преимущества.
Явное указание типов также открывает двери к более мощным инструментам. Программы — либо сам PHP, либо инструменты для анализа от третьих лиц — могут изучать исходный код, находя возможные ошибки или возможности оптимизации на основании полученной информации.
Например, мы можем проверить, что следующий код является некорректным и всегда будет падать, даже без его запуска:
Этот процесс называется «статический анализ», и он является невероятно мощным способом оценки программ с целью поиска и исправления ошибок. Этому немного мешает стандартная слабая типизация PHP. Передача целого числа в функцию, которая ожидает строку, или строку в функцию, ожидающую целое, все это продолжает работать и PHP молча конвертирует примитивы между собой, также как и всегда. Что делает статический анализ, нами или с помощью утилит, менее полезным.
Введение режима строгой типизации является краеугольным камнем новой системы типов PHP 7.
Авто-преобразование имеет смысл, в тех случаях, когда практически все входные данные передаются как строки (из базы данных или http-запросы), но в то же время оно ограничивает полезность проверки типов. Как раз для этого в PHP 7 предлагается strict_types режим. Его использование является несколько тонким и неочевидным, но при должном понимании разработчик получает невероятно мощный инструмент.
Чтобы включить режим строгой типизации, добавьте объявление в начало файла, вот так:
Другими словами, методы и функции будут затронуты строгой типизацией только, если они вызваны в соответствующе задекларированном файле. Код в любой другой части проекта не будет задет. Желание разработчиков библиотек следовать принципу строгой типизации не будет влиять именно на ваш код, только на их.
При слабой типизации это означает, что в Бостоне адрес будет интерпретироваться не как zip-код 02113, а как целое число 02113, что по основанию 10 будет: 1099, вот его-то PHP и переведет в почтовый индекс «1099». Поверьте мне, жители Бостона ненавидят это. Такую ошибку в итоге можно отловить где-то в базе или при валидации, когда код принудительно заставит ввести именно шестизначное число, но в тот момент вы и понятия не будете иметь откуда пришло 1099. Может быть позднее, часов через 8 отладки, будет понятно.
Вместо этого, мы переключим EntityRespository.php в strict-режим и сразу же поймаем несоответствие типов. Если запустить код, то получим вполне конкретные ошибки, которые скажут нам точные строки, где их искать. А хорошие утилиты (либо IDE) могут поймать их еще до запуска!
Когда же мы должны использовать строгую типизацию? Мой ответ прост: как можно чаще. Скалярная типизация, типы возвращаемых значений и strict-mode предлагают огромные преимущества для дебаггинга и поддержки кода. Все они должны использоваться максимально, и как результат, будет более надежный, поддерживаемый и безглючный код.
Будем надеяться, что переход на PHP 7 будет намного быстрее, чем как это было с PHP 5. Это действительно стоит того. Одной из главных причин как раз и является расширенная система типов, дающая нам возможность сделать код более самодокументированны и более понятным друг другу и нашим инструментам. В результате получится намного меньше «хммм, я даже и не знаю что с этим делать» моментов, чем когда-либо прежде.
Пишем фотоальбом на PHP
В предыдущих уроках мы с вами писали систему авторизации на PHP и скрипт для загрузки файлов на сервер. В этом уроке мы с вами объединим эти умения в единую систему и создадим фотоальбом.
Это будет веб-приложение, в котором после авторизации можно загружать новые фото, а все остальные пользователи смогут видеть список фоток, а также просматривать каждую фотографию отдельно.
Мы будем расширять уже созданную нами ранее систему авторизации, её исходный код до начала изменений вы можете скачать тут.
Создадим также файл upload.php из прошлого урока и папку upload. Должно получиться вот так.
Загружать картинки может только авторизованный пользователь
Теперь давайте сделаем так, чтобы upload.php мог использовать только авторизованный пользователь.
Для этого в начале скрипта добавим проверку того, что пользователь авторизован:
Этим мы просто не допустим загрузку файла на сервер. Помимо этого в upload.php нужно неавторизованному пользователю вообще не показывать форму для загрузки файлов. Проще простого, добавляем ещё одно условие:
Отлично, теперь загружать файлы можно только после логина.
Список фотографий
Давайте теперь сделаем страничку с выводом списка фотографий. Для этого мы изменим файл index.php.
Для начала давайте загрузим с помощью upload.php несколько фоток. Я взял картинки с котиками, назвал их 1.jpg, 2.jpg, 3.jpg и загрузил их через формочку. После этого они появились в папке uploads.
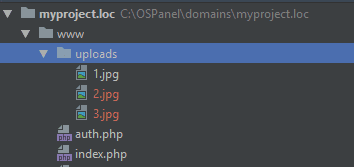
Так как наши фоточки сохраняются в папку uploads, то из неё и будем формировать наш список.
В домашнем задании к одному из прошлых уроков вы должны были познакомиться с функцией scandir(). Она возвращает список файлов в директории в виде массива.
Давайте запишем в файл index.php следующий код:
Теперь запустим скрипт в браузере и увидим следующее:

. и .. – это текущая директория и родительская директория соответственно. А вот всё остальное – это наши файлы.
Давайте сформируем список ссылок на наши картинки. Пройдёмся по массиву с именами файлов и приклеим перед их именами текст http://myproject.loc/uploads/, а ещё нам нужно проигнорировать папки . и ...

Остаётся только вывести превьюшки!
Полюбуемся на результат.

Остаётся только добавить ссылки, чтобы при клике на картинки открывалась исходная фоточка.
Вот и всё! Полный исходный код текущего состояния доступен здесь. А изменения, которые были произведены в данном уроке, можно наглядно рассмотреть вот здесь.
Определение кодировки текста в PHP — обзор существующих решений плюс еще один велосипед
Столкнулся с задачей — автоопределение кодировки страницы/текста/чего угодно. Задача не нова, и велосипедов понапридумано уже много. В статье небольшой обзор найденного в сети — плюс предложение своего, как мне кажется, достойного решения.
Если кратко — он не работает.
Давайте смотреть:
Как видим, на выходе — полная каша. Что мы делаем, когда непонятно почему так себя ведет функция? Правильно, гуглим. Нашел замечательный ответ.
Чтобы окончательно развеять все надежды на использование mb_detect_encoding(), надо залезть в исходники расширения mbstring. Итак, закатали рукава, поехали:
Постить полный текст метода не буду, чтобы не засорять статью лишними исходниками. Кому это интересно посмотрят сами. Нас истересует строка под номером 593, где собственно и происходит проверка того, подходит ли символ под кодировку:
Вот основные фильтры для однобайтовой кириллицы:
Windows-1251 (оригинальные комментарии сохранены)
ISO-8859-5 (тут вообще все весело)
Как видим, ISO-8859-5 всегда возвращает TRUE (чтобы вернуть FALSE, нужно выставить filter->flag = 1).
Когда посмотрели фильтры, все встало на свои места. CP1251 от KOI8-R не отличить никак. ISO-8859-5 вообще если есть в списке кодировок — будет всегда детектиться как верная.
В общем, fail. Оно и понятно — только по кодам символов нельзя в общем случае узнать кодировку, так как эти коды пересекаются в разных кодировках.
2. Что выдает гугл
А гугл выдает всякие убожества. Даже не буду постить сюда исходники, сами посмотрите, если захотите (уберите пробел после http://, не знаю я как показать текст не ссылкой):
http:// deer.org.ua/2009/10/06/1/
http:// php.su/forum/topic.php?forum=1&topic=1346
3. Поиск по хабру
2) на мой взгляд, очень интересное решение: habrahabr.ru/blogs/php/27378/#comment_1399654
Минусы и плюсы в комменте по ссылке. Лично я считаю, что только для детекта кодировки это решение избыточно — слишком мощно получается. Определение кодировки в нем — как побочный эффект ).
4. Собственно, мое решение
Идея возникла во время просмотра второй ссылки из прошлого раздела. Идея следующая: берем большой русский текст, замеряем частоты разных букв, по этим частотам детектим кодировку. Забегая вперед, сразу скажу — будут проблемы с большими и маленькими буквами. Поэтому выкладываю примеры частот букв (назовем это — «спектр») как с учетом регистра, так и без (во втором случае к маленькой букве добавлял еще большую с такой же частотой, а большие все удалял). В этих «спектрах» вырезаны все буквы, имеющие частоты меньше 0,001 и пробел. Вот, что у меня получилось после обработки «Войны и Мира»:
Спектры в разных кодировках (ключи массива — коды соответствующих символов в соответствующей кодировке):
Далее. Берем текст неизвестной кодировки, для каждой проверяемой кодировки находим частоту текущего символа и прибавляем к «рейтингу» этой кодировки. Кодировка с бОльшим рейтингом и есть, скорее всего, кодировка текста.
Результаты
У-упс! Полная каша. А потому что большие буквы в CP1251 обычно соответствуют маленьким в KOI8-R. А маленькие буквы используются в свою очередь намного чаще, чем большие. Вот и определяем строку капсом в CP1251 как KOI8-R.
Пробуем делать без учета регистра («спектры» case insensitive)
Как видим, верная кодировка стабильно лидирует и с регистрозависимыми «спектрами» (если строка содержит небольшое количество заглавных букв), и с регистронезависимыми. Во втором случае, с регистронезависимыми, лидирует не так уверенно, конечно, но вполне стабильно даже на маленьких строках. Можно поиграться еще с весами букв — сделать их нелинейными относительно частоты, например.
5. Заключение
В топике не расмотрена работа с UTF-8 — тут никакий принципиальной разницы нету, разве что получение кодов символов и разбиение строки на символы будет несколько длиннее/сложнее.
Эти идеи можно распространить не только на кириллические кодировки, конечно — вопрос только в «спектрах» соответствующих языков/кодировок.
P.S. Если будет очень нужно/интересно — потом выложу второй частью полностью работающую библиотеку на GitHub. Хотя я считаю, что данных в посте вполне достаточно для быстрого написания такой библиотеки и самому под свои нужды — «спектр» для русского языка выложен, его можно без труда перенести на все нужные кодировки.
UPDATED
В комментариях проскочила замечательная функция, ссылку на которую я опубликовал под графом «убожество». Может быть погорячился со словами, но уж как опубликовал, так опубликовал — редактировать такие вещи не привык. Чтобы не быть голословным, давайте разберемся, работает ли она на 100%, как об этом говорит предполагаемый автор.
1) будут ли ошибки при «нормальной» работе этой функции? Предположим, что контент у нас на 100% валидный.
ответ: да, будут.
2) определит ли она что-нибудь кроме UTF-8 и не-UTF-8?
ответ: нет, не определит.
PHP Code Style Conventions
В данной статье рассматривается подход к написанию и оформлению PHP кода. Нижеизложенные моменты были сформированы путем анализа существующих подходов компаний и личного опыта.
Правила именования файлов и папок
Все названия для папок и файлов должны быть осмысленными и говорящими (не требующие дополнительного разъяснения).
Папки
Если папка хранит в себе классы, которые относятся к пространству имен (namespace), то папка именуется в соответствии с названием пространства имен (namespace).
Файлы
Если файл является файлом класса, то именуется в соответствии с названием класса.
Правила именования пространств имен, классов, методов и переменных
Все названия должны быть осмысленными и говорящими (не требующие дополнительного разъяснения).
Пространства имен
Названия пространств имен должны быть в нижнем регистре и состоять из одного слова. В случае необходимости именовать пространств имен более одного слова производится дробление на составные части, являющиеся вложенными пространствами имен.
Классы
Методы
К названиям методов применяются следующие правила:
Переменные
К названиям переменных применяются следующие правила:
Название переменной должно передавать намерения программиста
Название переменной должно сообщить, почему эта переменная существует, что она делает и как используется
Название переменной не должно быть коротким
Если переменная хранит признак, то он должен быть включен в название ( unpaidProject )
Переменные и свойства объекта должны являться существительными и называться так, чтобы они правильно читались при использовании, а не при инициализации
Плохо:
Хорошо:
Запрещены отрицательные логические названия
Плохо:
Хорошо:
Правила оформления кода
В первую очередь ставится пространство имен (namespace), которое используется (если есть). Далее пишется конструкции использования классов ( use ). В случае использования нескольких
классов одного пространства имен происходит группировка с помощью конструкции <. >. Далее идет объявление класса.
Фигурные скобки ставятся на той же строке и разделяются пробелом.
Каждая переменная должна быть объявлена на новой строке.
Условия и служебные вызовы методов разделяются переносом строки, переменные и работа с ними переносами строк не разделяются.
Внутри условий и циклов дополнительный перенос на новую строку не ставится.
Содержимое класса разделяется сверху одной пустой строкой.
Перед возвращаемым значением( return ) обязательно ставится перенос строки, если метод не состоит из единственной строки.
Если условие является большим, то обязательно выделить его в одно или несколько смысловых выражений и использовать его (их) в условии.
Плохо:
Хорошо:
Комментирование кода
В общем случае комментарии запрещены (НЕ «всегда»). Любой участок кода, который необходимо выделить или прокомментировать, надо выносить в отдельный метод.
Комментарии должны быть расположены перед объявлением классов, переменных и методов и быть оформлены в соответствии с PHPDoc. Комментарий перед классом должен содержать описание бизнес-логики и отражать его назначение с приведением примеров использования.
Готовые алгоритмы, взятые из внешнего источника, должны быть помечены ссылкой на источник.
Правила написания кода
Везде, где имеет смысл, должнно быть прописано declare(strict_types=1);
Нельзя изменять переменные, которые передаются в метод на вход (исключение — если эта переменная объект).
Строки обрамляются одинарными кавычками. Двойные кавычки используются только, если:
Вместо лишней конкатенации используем подстановку переменных в двойных кавычках
Метод должен явно отличать нормальные ситуации от исключительных.
По умолчанию тексты исключений не должны показываться пользователю. Они предназначены для логирования и отладки. Текст исключения можно показать пользователю, если оно явно для этого предназначено.
В условном операторе должно проверяться исключительно boolean значение. В сравнении не boolean переменных используется строгое сравнение с приведением типа ( === ), автоматическое приведение и нестрогое сравнение не используются.
При использовании в условном выражении одновременно операторов И и ИЛИ обязательно выделять приоритет скобками.