Урок №40. Инкремент, декремент и побочные эффекты
Обновл. 11 Сен 2021 |
На этом уроке мы рассмотрим, что такое инкремент и декремент в языке С++, а также разберемся с таким понятием, как «побочные эффекты».
Инкремент и декремент
Операции инкремента (увеличение на 1 ) и декремента (уменьшение на 1 ) переменных настолько используемые, что у них есть свои собственные операторы в языке C++. Кроме того, каждый из этих операторов имеет две версии применения: префикс и постфикс.
| Оператор | Символ | Пример | Операция |
| Префиксный инкремент (пре-инкремент) | ++ | ++x | Инкремент x, затем вычисление x |
| Префиксный декремент (пре-декремент) | −− | −−x | Декремент x, затем вычисление x |
| Постфиксный инкремент (пост-инкремент) | ++ | x++ | Вычисление x, затем инкремент x |
| Постфиксный декремент (пост-декремент) | −− | x−− | Вычисление x, затем декремент x |
С операторами инкремента/декремента версии префикс всё просто. Значение переменной х сначала увеличивается/уменьшается, а затем уже вычисляется. Например:
Вот еще один пример, показывающий разницу между версиями префикс и постфикс:
Результат выполнения программы:
5 5
6 4
6 4
6 4
7 3
В строке №7 переменные х и у увеличиваются/уменьшаются на единицу непосредственно перед обработкой компилятором, так что сразу выводятся их новые значения. А в строке №9 временные копии ( х = 6 и у = 4 ) отправляются в cout, а только после этого исходные х и у увеличиваются/уменьшаются на единицу. Именно поэтому изменения значений переменных после выполнения операторов версии постфикс не видно до следующей строки.
Версия префикс увеличивает/уменьшает значения переменных перед обработкой компилятором, версия постфикс — после обработки компилятором.
Правило: Используйте префиксный инкремент и префиксный декремент вместо постфиксного инкремента и постфиксного декремента. Версии префикс не только более производительны, но и ошибок с ними (по статистике) меньше.
Побочные эффекты
Функция или выражение имеет побочный эффект, если она/оно изменяет состояние чего-либо, делает ввод/вывод или вызывает другие функции, которые имеют побочные эффекты.
В большинстве случаев побочные эффекты являются полезными:
Также побочные эффекты могут приводить и к неожиданным результатам:
Вот еще один пример:
Есть и другие случаи, в которых C++ не определяет порядок обработки данных, поэтому в разных компиляторах могут быть разные результаты. Но даже в тех случаях, когда C++ и уточняет порядок обработки данных, некоторые компиляторы все равно вычисляют переменные с побочными эффектами некорректно. Этого всего можно избежать, если использовать переменные с побочными эффектами не более одного раза в одном стейтменте.
Правило: Не используйте переменную с побочным эффектом больше одного раза в одном стейтменте.
Поделиться в социальных сетях:
Урок №39. Арифметические операторы
Комментариев: 31
Постфикс круче!
Поэтому язык называется С++, а не ++С.
Попытка разобраться почему x = x++ вызывал «undefined behavior».
До с++17 компилятор VS выдавал такой код:
x = x (1) — вычисляем правый операнд, присваивание здесь НЕ выполняется, мы просто ставим на место справа от равно 1.
x = 1 — выполняем присваивание, значение «х» равно 1.
Собственно на этом всё, согласно стандарту мы выполнили присваивание, но остался «побочный эффект» у оператора справа x++. И то когда выполнять пост-инкремент было не определено. VS компилятор делал это после т.е следующей была команда:
x++ — и «х» равен 2, что и выводилось в консоль.
В с++17 определили порядок: вычисление правого операнда далее вычисление выражения(т.е «побочного эффекта») и только потом операция присваивания:
Теперь порядок выполнения операторов соответствует приоритету операций и сам инкремент выполняется правильно, через копию переменной. Как я понял так изначально было реализовано в компиляторе gcc, который выводил 1.
Почему ниже написанная программа выдаёт разный результат? У меня он такой:
Префиксы и постфиксы в PHP (и CSS)

Ещё давно я взял практику использовать префиксы и постфиксы в PHP и в CSS. Особенно это актуально, когда что-то выходит за рамки локальной видимости и находится в глобальном пространстве, взять те же модели в Yii.
Префиксы и постфиксы несут основную задачу – сделать сущность максимально уникальной, причём настолько, чтобы её можно было без проблем найти любым текстовым редактором. На сегодняшний день IDE поддерживают отличную вещь – «Find Usages» (поиск использований), но это не всегда помогает, и об этом я напишу чуть ниже.
Именование в стиле Венгерской нотации мне не пришлось по душе. Такой подход мне не нравился ещё со времён C++ / Delphi – я считал его избыточном и не всегда понятным. Мне понравилась реализация БЭМ, но в полной мере я её тоже не использую. Я постарался вычленить и объединить наиболее понравившиеся мне методы, о них и расскажу.
Все CSS классы я начинаю с префикса «cl_», идентификаторы с префикса «id_». Если класс или идентификатор относится к блоку, добавляю после префикса «b_», если к модулю – «m_». Какие-либо внутренние состояния или мини-блоки я также указываю с префиксами.
Таким образом, у меня всегда уникальные и структурно понятные названия. Да и найти такие названия куда проще, если надо, например, провести рефакторинг и посмотреть, где это может отразиться.
Кстати, такой код легче прогнать через сжатие и обфускацию. Причём, не надо никаких анализаторов – ищи регуляркой по префиксам и сжимай. Собственно, поэтому и используются разные префиксы для идентификаторов и классов. Я думаю, статья про сжатие и обфускацию будет интересна аудитории Хабра, постараюсь её оформить, как появится время.
PHP (Yii)
Как-то неправильно, что контроллеры, валидаторы и т.п. имеют дополнительные префиксы и постфиксы, а модели не имеют. Я решил, что ввиду «магии» Yii тяжело будет найти, где используется класс User, а простым поиском по тексту слово User будет встречаться везде, где только можно.
Использование таких наименований придаёт уникальности, и в случае чего я могу даже без IDE найти все использования того или иного класса. Также я всячески старюсь отойти от использования текстового представления классов и атрибутов, особенно считаю большим злом, когда ссылка на класс генерируется из объединения строк – это нельзя найти ни через «Find Usages», ни через поиск по тексту. Например:
Для именования relations в Yii я также использую специальный префикс – «R_» (сокращение от Relation). Таким образом, при взгляде сразу уже понятно, что это не атрибут модели, а именно связь с другой моделью. Хотя по концепции Yii это преподносится как одно и то же (атрибут модели), всё же я считаю, что это разные вещи. Помимо добавления префикса, я всегда добавляю также и название класса модели. Да, этот подход может и менее красив, зато сух и конкретен – при взгляде на код я сразу же понимаю, что от чего зависит, и откуда взялись данные.
Как можно заметить в коде выше (метод relations), я определяю классы для связанных моделей динамически, а не текстом. Но это возможно только для PHP > 5.5. Если же (а скорей всего так и есть) сервер не поддерживает такую версию PHP, можно расширить ActiveRecord и вместо CLASS использовать метод _CLASS_(). Потом после перехода на PHP > 5.5 можно будет без проблем заменить _CLASS_() на CLASS простым «Find And Replace».
«ЗА» или «ПРОТИВ»
В моём окружении есть сторонники как «ЗА», так и «ПРОТИВ» такого подхода к именованию.
Против такой схемы именования можно привести то, что эта информация является излишней, и (как бы) не стоит мусорить код префиксами и постфиксами. К тому же, необходимо научить других (и новых) сотрудников разбираться, как и что надо именовать (хотя лично я не вижу в этом проблемы).
Да, префиксы и постфиксы несколько замедляют написание кода, но код пишется один раз, а читается и рефакторится далеко не один. Как по мне, так значительно проще читать код, в котором можно сразу определить по префиксам и регистру, где атрибут модели, где метод, а где scope или relation. Префикс «R_» явно даёт понять, что это связь, а постфикс «Model», что это модель. Например, есть класс WebUser – это компонент (extends CWebUser), а есть класс User – и это уже модель.
Мне хочется услышать от аудитории Хабра именно конструктивного обсуждения такого подхода. Возможно, есть иные варианты решения проблем с неуникальными именами.
Инфиксные, префиксные и постфиксные выражения¶
Когда вы записываете арифметическое выражение вроде B * C, то его форма предоставляет вам достаточно информации для корректной интерпретации. В данном случае мы знаем, что переменная B умножается на переменную C, поскольку оператор умножения * находится в выражении между ними. Такой тип записи называется инфиксной, поскольку оператор расположен между (in between) двух операндов, с которыми он работает.
Рассмотрим другой инфиксный пример: A + B * C. Операторы + и * по-прежнему располагаются между операндами, но тут уже есть проблема. С какими именно операндами они будут работать? + работает с A и B или * принимает B и C? Выражение выглядит неоднозначно.
Фактически, вы можете читать и писать выражения такого типа долгое время, и они не будут вызывать у вас вопросов. Причина в том, что вы кое-что знаете о + и *. Каждый оператор имеет свой приоритет. Операторы с высоким приоритетом используются прежде операторов с низким. Единственной вещью, которая может изменить порядок приоритетов, являются скобки. Для арифметических операций умножение и деление стоят выше сложения и вычитания. Если появляются два оператора одинакового приоритета, то используются порядок слева направо, или их ассоциативность.
Давайте интерпретируем вызвавшее затруднение выражение A + B * C, используя приоритет операторов. B и C перемножаются первыми, затем к результату добавляется A. (A + B) * C заставит выполнить сложение A и B перед умножением. В выражении A + B + C по очерёдности (через ассоциативность) первым будет вычисляться самый левый +.
Хотя это очевидно для вас, помните: компьютер нуждается в точном знании того, как и в какой последовательности вычисляются операторы. Одним из способов записи выражения, гарантирующим, что не возникнет путаницы по отношению к порядку операций, является создание того, что называется выражением с полностью расставленными скобками. Такой тип выражения использует пару скобок для каждого оператора. Скобки диктуют порядок операций, так что здесь не возникает многозначности. Так же отпадает необходимость помнить правила расстановки приоритетов.
Выражение A + B * C + D может быть переписано как ((A + (B * C)) + D) с целью показать, что умножение происходит в первую очередь, а затем следует крайнее левое сложение. A + B + C + D перепишется в (((A + B) + C) + D), поскольку операции сложения ассоциируются слева направо.
Существует ещё два очень важных формата выражений, которые на первый взгляд могут показаться вам неочевидными. Рассмотрим инфиксную запись A + B. Что произойдёт, если мы поместим оператор перед двумя операндами? Результирующее выражение будет + A B. Также мы можем переместить оператор в конец, получив A B +. Всё это выглядит несколько странным.
A + B * C в префиксной нотации можно переписать как + A * B C. Оператор умножения ставится непосредственно перед операндами B и C, указывая на приоритет * над +. Затем следует оператор сложения перед A и результатом умножения.
В постфиксной записи выражение выглядит как A B C * +. Порядок операций вновь сохраняется, поскольку * находится непосредственно после B и C, обозначая, что он имеет приоритет выше следующего +. Хотя операторы перемещаются и теперь находятся до или после соответствующих операндов, порядок последних по отношению друг к другу остаётся в точности таким, как был.
| Инфиксная запись | Префиксная запись | Постфиксная запись |
|---|---|---|
| A + B | + A B | A B + |
| A + B * C | + A * B C | A B C * + |
А сейчас рассмотрим инфиксное выражение (A + B) * C. Напомним, что в этом случае запись требует наличия скобок для указания выполнить сложение перед умножением. Однако, когда A + B записывается в префиксной форме, то оператор сложения просто помещается перед операндами: + A B. Результат этой операции является первым операндом для умножения. Оператор умножения перемещается в начало всего выражения, давая нам * + A B C. Аналогично, в постфиксной записи A B + явно указывается, что первым происходит сложение. Умножение может быть выполнено для получившегося результата и оставшегося операнда C. Соответствующим постфиксным выражением будет A B + C *.
Рассмотрим эти три выражения ещё раз (см. таблицу 3). Происходит что-то очень важное. Куда ушли скобки? Почему они не нужны нам в префиксной и постфиксной записи? Ответ в том, что операторы больше не являются неоднозначными по отношению к своим операндам. Только инфиксная запись требует дополнительных символов. Порядок операций внутри префиксного и постфиксного выражений полностью определён позицией операторов и ничем иным. Во многом именно это делает инфиксную запись наименее желательной нотацией для использования.
| Инфиксное выражение | Префиксное выражение | Постфиксное выражение |
|---|---|---|
| (A + B) * C | * + A B C | A B + C * |
Таблица 4 демонстрирует некоторые дополнительные примеры инфиксных выражений и эквивалентных им префиксных и постфиксных записей. Убедитесь, что вы понимаете, почему они эквивалентны с точки зрения порядка выполнения операций.
| Инфиксное выражение | Префиксное выражение | Постфиксное выражение |
|---|---|---|
| A + B * C + D | + + A * B C D | A B C * + D + |
| (A + B) * (C + D) | * + A B + C D | A B + C D + * |
| A * B + C * D | + * A B * C D | A B * C D * + |
| A + B + C + D | + + + A B C D | A B + C + D + |
Преобразование инфиксного выражения в префиксное и постфиксное¶
До сих пор мы использовали специальные методы для преобразования между инфиксными выражениями и эквивалентными им префиксной и постфикской записями. Как вы можете ожидать, существуют алгоритмические способы выполнения таких преобразований, позволяющие корректно трансформировать любое выражение любой сложности.
Первой из рассматриваемых нами техник будет использование идеи полной расстановки скобок в выражении, рассмотренной нами ранее. Напомним, что A + B * C можно записать как (A + (B * C)), чтобы явно показать приоритет умножения перед сложением. Однако, при более близком рассмотрении вы увидите, что каждая пара скобок также отмечает начало и конец пары операндов с соответствующим оператором по середине.
Взгляните на правую скобку в подвыражении (B * C) выше. Если мы передвинем символ умножения с его позиции и удалим соответствующую левую скобку, получив B C *, то произойдёт конвертирование подвыражение в постфиксную нотацию. Если оператор сложения тоже передвинуть к соответствующей правой скобке и удалить связанную с ним левую скобку, то результатом станет полностью постфиксное выражение (см. рисунок 6).
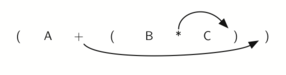
Рисунок 6: Перемещение операторов вправо для постфиксной записи
Если мы сделаем тоже самое, но вместо передвижения символа на позицию к правой скобке, сдвинем его к левой, то получим префиксную нотацию (см. рисунок 7). Позиция пары скобок на самом деле является ключом к окончательной позиции заключённого между ними оператора.
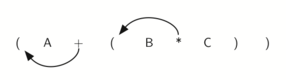
Рисунок 7: Перемещение операторов влево для префиксной записи.
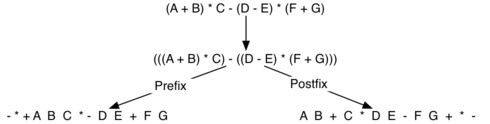
Рисунок 8: Преобразование сложного выражения к префиксной и постфиксной записи.
Обобщённое преобразование из инфиксного в постфиксный вид¶
Нам необходимо разработать алгоритм преобразования любого инфиксного выражения в постфиксное. Для этого посмотрим ближе на сам процесс конвертирования.
Рассмотрим ещё раз выражение A + B * C. Как было показано выше, его постфиксным эквивалентом является A B C * +. Мы уже отмечали, что операнды A, B и C остаются на своих местах, а местоположение меняют только операторы. Ещё раз взглянем на операторы в инфиксном выражении. Первым при проходе слева направо нам попадётся +. Однако, в постфиксном выражении + находится в конце, так как следующий оператор, *, имеет приоритет над сложением. Порядок операторов в первоначальном выражении обратен результирующему постфиксному выражению.
В процессе обработки выражения операторы должны где-то храниться, пока не найден их соответствующий правый операнд. Также порядок этих сохраняемых операторов может быть обратным (из-за их приоритета), как в данном примере со сложением и умножением. Поскольку оператор сложения, появляющийся перед оператором умножения, имеет более низкий приоритет, то он должен появиться после использования последнего. Из-за такого обратного порядка имеет смысл рассмотреть использование стека для хранения операторов до тех пор, пока они не понадобятся.
Что насчёт (A + B) * C? Напомним его постфиксный эквивалент: A B + C *. Повторимся, что обрабатывая это инфиксное выражение слева направо, первым мы встретим +. В этом случае, когда мы увидим *, + уже будет помещён в результирующее выражение, поскольку имеет преимущество над * в силу использования скобок. Теперь можно приступить к рассмотрению работы алгоритма преобразования. Когда мы видим левую скобку, то сохраняем её как знак, что должен будет появиться другой оператор с высоким приоритетом. Он будет ожидать, пока не появится соответствующая правая скобка, чтобы отметить его местоположение (вспомните технику полной расстановки скобок). После появления правой скобки оператор выталкивается из стека.
Поскольку мы сканируем инфиксное выражение слева направо, то для хранения операторов будем использовать стек. Это предоставит нам обратный порядок, который был отмечен в первом примере. На вершине стека всегда будет последний сохранённый оператор. Когда бы мы не прочитали новый оператор, мы должны сравнить его по приоритету с операторами в стеке (если таковые имеются).
Рисунок 9 демонстрирует алгоритм преобразования, работающий над выражением A * B + C * D. Заметьте, что первый оператор * удаляется до того, как мы встречаем оператор +. Также + остаётся в стеке, когда появляется второй *, поскольку умножение имеет приоритет перед сложением. В конце инфиксного выражения из стека дважды происходит выталкивание, удаляя оба оператора и помещая + как последний элемент в результирующее постфиксное выражение.
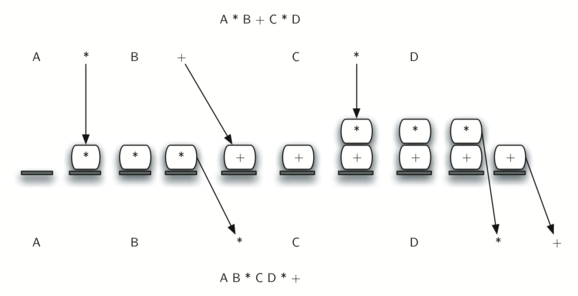
Рисунок 9: Преобразование A * B + C * D в постфиксную запись
Чтобы закодировать алгоритм на Python, мы будем использовать словарь под именем prec для хранения значений приоритета операторов. Он связывает каждый оператор с целым числом, которые можно сравнивать с числами других операторов, как уровень приоритетности (для этого мы произвольно выбрали целые числа 3, 2 и 1). Левая скобка получит самое низкое значение. Таким образом, любой сравниваемый с ней оператор будет иметь приоритет выше и располагаться над ней. Строка 15 определяет, что операнды могут быть любыми символами в верхнем регистре или цифрами. Полная функция преобразования показана в ActiveCode 8.
2.9. Переменные в параметрах
Содержание
1. Краткий обзор
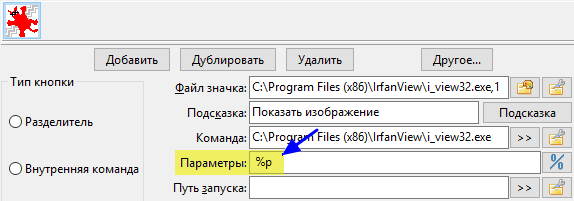
Переменные будут помогать нам в создании кнопок панели инструментов или настройке файловых ассоциаций.
В основном мы будем использовать их, когда необходимо передать команде в качестве параметра выделенный файл(ы), каталог, в котором мы находимся, и другие подобных вещи, связанные с содержимым файловых панелей.
Когда пользователь нажмёт эту кнопку, он запустит IrfanView, а переменную %p Double Commander заменит выбранным в активной панели файлом.
Вот что понимается под переменными, описанными на этой странице.
2. Основные переменные
Это основные переменные, которые могут использоваться и которые связаны с текущим выбором.
По умолчанию все значения переменных автоматически берутся в двойные кавычки. Если вам не нужно такое поведение, смотрите секцию Использование кавычек.
В качестве примера для каждой переменной мы используем файл C:\Users\UserName\Desktop\comment.png.
| Основные переменные | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Переменная | Что обозначает | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Полное имя файла, путь+имя файла Пример: %p = «C:\Users\UserName\Desktop\comment.png» | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Только путь, без разделителя каталогов в конце Пример: %d = «C:\Users\UserName\Desktop» | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
3. Основные суффиксы переменныхК упомянутым выше переменным из одной буквы мы можем добавить ещё одну букву, что позволит уточнить значение используемой переменной. Для каждого примера предполагаем следующее:
4. Нумерованный суффиксЕсли у нас много выделенных файлов, мы можем добавить суффикс к ранее упомянутым переменным, чтобы уточнить, какой из них хотим использовать. Для каждой строки таблицы предполагаем, что в активной панели открыт каталог «C:\temp\» и мы выделили двадцать шесть файлов с именем «FileA.txt», «FileB.txt» и т.д. до «FileZ.txt».
6. Путь панелиРанее мы разбирали переменные, связанные с выделенными файлами и папками. Но мы также можем использовать переменную %D для выбора каталога конкретной панели. Для выбора панели к этой переменной мы можем добавить букву из упомянутых выше основных суффиксов. Для каждого примера предполагаем следующее:
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||