PHP парсер с авторизацией
Часто возникают задачи, требующие получения данных со страниц сайта, которые показываются только залогиненным пользователям. В этом случае нам нужно написать парсер с автоматической авторизацией.
Информация о том, авторизован пользователь или нет, часто хранится в Cookies. Составить правильный запрос и обработать файлы Cookies нам поможет библиотека cURL.
Предварительно нужно понять, как работает механизм авторизации на сайте, какие передаются переменные после отправки данных формы входа. Эти данные можно проанализировать с помощью инструментов разработчика в браузере.

В качестве примера разберём парсер баланса баллов в интернет-магазине Gearbest. В html коде формы входа видим название полей ввода логина и пароля, а также адрес страницы-обработчика: /m-users-a-act_sign.htm.
Далее попытаемся авторизоваться и отследить какие запросы отправляются на сервер. Введя правильные логин и пароль мне не удалось успеть увидеть нужные запросы, так как происходит несколько редиректов. А сам запрос авторизации отправляется по AJAX.
Поэтому решил посмотреть, что происходит при вводе неверных данных. В этом случае удалось отследить нужные запросы и структуру переменных.

На следующем шаге смотрим код страницы личного кабинета и прикидываем, как спарсить данные баланса бонусных баллов.

На основе полученной информации можно написать PHP парсер баланса баллов с авторизацией. Я решил дописать ряд функций для парсера из предыдущего примера. Для составления POST запросов используем функции библиотеки cURL.
Полученный в результате код парсера с авторизацией:
Для того, чтобы парсер смог авторизоваться, надо ввести свои данные в переменную $user_data.
Из значимых доработок парсера стоит отметить написание функции curl_login(), которая как раз формирует запрос на авторизацию с отправкой POST параметров на сервер. Также для всех функций были добавлены парметры работы с Cookies. Это нужно для того, чтобы информация о том, что парсер залогинен, передавалась от запроса к запросу.
Пример файла Cookies, сгенерированного cURL:
После авторизации с помощью функции get_gearbest_login(), мы далее сразу парсим страницу с листом желаний личного кабинета с помощью функции get_gearbest_point().
Далее выводим статус попытки авторизации и бонусный баланс.
Возможные варианты ответов от сервера gearbest.com при попытке авторизации:
Кстати, если вначале авторизоваться и спарсить баланс баллов, то дальше при парсинге цен на товары, статус авторизованного пользователя будет сохраняться.
Теперь мы знаем, как можно автоматически с помощью PHP и cURL залогиниться на сайте и получить данные со страниц для авторизованных пользователей. В следующих статьях из цикла про разработку парсеров мы рассмотрим примеры применения технологии AJAX для парсинга сайтов.
Применение cURL в PHP парсерах сайтов
В этой статье разберём одну из ключевых деталей любого парсера сайтов. Это составление запросов к серверу источнику информации и получение от него ответа.
Один из самых простых вариантов воспользоваться PHP функцией file_get_contents(), но часто этого бывает мало, так как многие сайты для того, чтобы отдать нужный контент требуют отправить запрос с определёнными заголовками или куками. Также нам бывает нужна информация о заголовках в ответе сервера.
Для более сложных случаев удобнее составлять запросы с помощью функции из модуля cURL. cURL — это модуль для PHP, обеспечивающий поддержку библиотеки функций libcurl. Эта библиотека позволяет формировать POST или PUT запросы к веб-серверам, скачивать файлы. Набор функций поддерживает различные протоколы обмена http, https, ftp и пр. Расширение cURL позволяет работать с поддержкой прокси-серверов, cookies и проводить аутентификацию пользователей. Получается хороший инструмент для имитации действий пользователя в браузере.
Для разработки парсеров я написал аналог функции file_get_contents() с помощью cURL.
С помощью функции curl_setopt() мы задаём нужные нам заголовки запроса. Например, через CURLOPT_USERAGENT настраивается User-Agent, можно менять тип браузера, из-под которого якобы делается запрос.
 Подробно изучить параметры и заголовки запросов можно с помощью панели для веб-разрабочиков прямо в браузере по вкладке «Сеть». Очень полезный инструмент для начинающих и опытных разработчиков парсеров.
Подробно изучить параметры и заголовки запросов можно с помощью панели для веб-разрабочиков прямо в браузере по вкладке «Сеть». Очень полезный инструмент для начинающих и опытных разработчиков парсеров.
Параметры заголовков cURL для парсера
Кроме User-Agent для имитации действий реального пользователя полезно задать CURLOPT_REFERER — это заголовок Referer, на некоторых сайтах веб-мастера проверяют его наличие, чтобы отфильтровать совсем тупых ботов.
CURLOPT_FOLLOWLOCATION — позволяет переходить по редиректам в автоматическом режиме, то же полезная настройка, чтобы не обрабатывать по отдельности разные 301-редиректы.
CURLOPT_URL — задаёт URL целевой страницы — источника данных.
Настройки curl_setopt ($ch, CURLOPT_SSL_VERIFYPEER, 0); — не проверять SSL сертификата и curl_setopt ($ch, CURLOPT_SSL_VERIFYHOST, 0); — не проверять Host SSL сертификата, удобно использовать при работе по протоколу HTTPS, когда вам не нужно проверять валидность SSL сертификат у сервера.
CURLOPT_COOKIEJAR и CURLOPT_COOKIEFILE — задают пути к файлам для записи и считывания параметров COOKIE, нужны, например, для авторизации на сайте или когда интернет-ресурс хранит какие-либо настройки в файлах куков.
Самые интересные на мой субъективный взгляд настройки для cURL я описал. Детальное описание всех применяемых настроек лучше почитать в более официальных справочниках PHP.
Дальше в функции curl_get_contents() идёт отправка запроса и получение ответа в переменную. По заголовкам ответа проверяем удалось ли достучаться до заданной страницы. Если код ответа 200 или 400, то возвращаем HTML ответ от сервера. При другом коде ответа сервера после некоторой паузы делаем повторный запрос. Это бывает полезно, когда хостинг сайта работает нестабильно и при частых запросах выдаёт 500-ю ошибку.
В следующих статьях по теме парсеров рассмотрим варианты скриптов с авторизацией и варианты работы с применением технологии AJAX, не переключайтесь.
Парсинг сайта с помощью CURL и phpQuery на PHP
 Сегодня я расскажу про то, как парсить сайт спомощью библиотеки php CURL и библиотеки phpQuery.
Сегодня я расскажу про то, как парсить сайт спомощью библиотеки php CURL и библиотеки phpQuery.
phpQuery — это аналог jQuery, только на PHP. Все методы, которые есть в jQuery, должны присутствовать и этой библиотеке. Это удобно тем, что можно легко перемещаться по DOM дереву html документа и с легкостью находить нужные элементы.
Первым делом нам нужно получить html содержимое нужной страницы сайта для парсинга. Можно сделать это несколькими способами. Первый, самый простой — это использовать функцию file_get_content, указав url страницы в качестве параметра:
Так же, в эту функцию есть возможность добавлять заголовки и т. д, с помощью использования потоковых контекстов:
Чтобы этот способ работал, опция allow_url_fopen в php.ini должна быть включена.
Так же получить содержимое web сайта можно с помощью сокетов (pfsockopen), но проще воспользоваться библиотекой php CURL, если она установлена на вашем сервере. Ниже я продемонстрирую, как получить содержимое страницы сайта с помощью библиотеки CURL.
Получение http страницы без параметров через CURL
Получение http страницы с get параметрами:
Получение web страницы по протоколу https:
Получение http страницы, которая загружается через редиректы (следование 302):
Отправка POST запроса с помощью CURL:
Включаем куки в CURL запросе (нужно при парсинге личных кабинетов):
Включить в запросе GZIP сжатие (нужно, если тело ответа приходит в виде непонятного набора текста, то есть сервер отправляет сжатый gzip’ом текст):
Вывести заголовки ответа от сервера. Часто нужно для отладки, если сервер не присылает правильного тела ответа или не присылает его вообще:
Хочу отметить, что самым важными параметрами при парсинге являются:
Стоит отметить, что все эти параметры (кроме первого) следует добавлять при необходимости. Поэксперементируйте с этими параметрами, если у вас не будет получаться без них. Так же не забывайте про параметр «CURLOPT_HEADER», он вам поможет при поиске проблемы.
Итак, что делать, если http страница получена через CURL, или каким-либо другим способом? Самое время воспользоваться phpQuery для парсинга полученного результата. Скачать библиотеку можно здесь.
Как мы видим phpQuery — это полный аналог jQuery.
Чтобы ознакомиться с полным наборов функций phpQuery, нужно зайти как ни странно, в документацию jQuery. Главная фишка phpQuery, как и jQuery — это использование css селекторов, это упрощает процедуру парсинга нужных элементов страницы в разы. Посмотреть методы и селекторы jQuery можно здесь.
Конечно, есть другие способы парсинга полученной с помощью php curl страницы, но парсинг при помощи phpQuery для меня наиболее удобен и эффективен.
Пишем парсер контента на PHP
Чтобы написать хороший и работоспособный скрипт для парсинга контента нужно потратить немало времени. А подходить к сайту-донору, в большинстве случаев, стоит индивидуально, так как есть масса нюансов, которые могут усложнить решение нашей задачи. Сегодня мы рассмотрим и реализуем скрипт парсера при помощи CURL, а для примера получим категории и товары одного из популярных магазинов.
Если вы попали на эту статью из поиска, то перед вами, наверняка, стоит конкретная задача и вы еще не задумывались над тем, для чего ещё вам может пригодится парсер. Поэтому, перед тем как вдаваться в теорию и непосредственно в код, предлагаю прочесть предыдущею статью – парсер новостей, где был рассмотрен один из простых вариантов, да и я буду периодически ссылаться на неё.
Работать мы будем с CURL, но для начала давайте разберёмся, что эта аббревиатура обозначает. CURL – это программа командной строки, позволяющая нам общаться с серверами используя для этого различные протоколы, в нашем случаи HTTP и HTTPS. Для работы с CURL в PHP есть библиотека libcurl, функции которой мы и будем использовать для отправки запросов и получения ответов от сервера.

Как можно увидеть из скриншота все категории находятся в ненумерованном списке, а подкатегории:

Внутри отельного элемента списка в таком же ненумерованном. Структура несложная, осталось только её получить. Товары мы возьмем из раздела «Все телефоны»:

На странице получается 24 товара, у каждого мы вытянем: картинку, название, ссылку на товар, характеристики и цену.
Пишем скрипт парсера
Если вы уже прочли предыдущею статью, то из неё можно было подчеркнуть, что процесс и скрипт парсинга сайта состоит из двух частей:
Основной метод, который у нас будет – это getPage() и у него всего один обязательный параметр URL страницы, которой мы будем парсить. Что ещё будет уметь наш замечательный метод, и какие значения мы будем обрабатывать в нем:
Конечно, обрабатываемых значений много и не всё мы будем использовать для нашей сегодняшней задачи, но разобрать их стоит, так как при парсинге больше одной страницы многое выше описанное пригодится. И так добавим их в наш скрипт:
Как видите, у всех параметров есть значения по умолчанию. Двигаемся дальше и следующей строчкой напишем кусок кода, который будет очищать файл с куками при запросе:
Так мы обезопасим себя от ситуации, когда по какой-либо причине не создался файл.
Для работы с CURL нам необходимо вначале инициализировать сеанс, а по завершению работы его закрыть, также при работе важно учесть возможные ошибки, которые наверняка появятся, а при успешном получении ответа вернуть результат, сделаем мы это таким образам:
После того, как мы инициализировали соединения через функцию curl_setopt(), установим несколько параметров для текущего сеанса:
Кстати очень удобный сервис, позволяющий отладить обращения к серверу. Так как, например, для того что бы узнать свой IP или заголовки отправляемые через CURL, нам бы пришлось бы писать костыль.
Если вывести на экран, то у вас должна быть похожая картина:

Если произойдет ошибка, то результат будет выглядеть так:

При успешном запросе мы получаем заполненную ячейку массива data с контентом и информацией о запросе, при ошибке заполняется ячейка error. Из первого скриншота вы могли заметить первую неприятность, о которой я выше писал контент сохранился не в переменную, а отрисовался на странице. Чтобы решить это, нам нужно добавить ещё один параметр сеанса CURLOPT_RETURNTRANSFER.
Обращаясь к страницам, мы можем обнаружить, что они осуществляют редирект на другие, чтобы получить конечный результат добавляем:
Теперь можно увидеть более приятную картину:

Для того, чтобы получить заголовки ответа, нам потребуется добавить следующий код:
Мы отключили вывод тела документа и включили вывод шапки в результате:

Для работы со ссылками с SSL сертификатом, добавляем:
Предлагаю проверить, а для этого я попробую вытянуть куки со своего сайта:

Всё получилось, двигаемся дальше и нам осталось добавить в параметры сеанса: прокси, заголовки и возможность отправки запросов POST:
Парсим категории и товары с сайта
Теперь, при помощи нашего класса Parser, мы можем сделать запрос и получить страницу с контентом. Давайте и поступим:
Следующим шагом разбираем пришедший ответ и сохраняем название и ссылку категории в результирующий массив:
Чуть более подробно работу с phpQuery я разобрал в первой статье по парсингу контента. Если вкратце, то мы пробегаемся по DOM дереву и вытягиваем нужные нам данные, их я решил протримить, чтобы убрать лишние пробелы. А теперь выведем категории на экран:

В результате мы получили все ссылки на категории. Для получения товаров используем тот же принцип:
Получаем страницу, тут я увеличил время соединения, так как 5 секунд не хватило, и разбираем её, парся необходимый контент:
Теперь проверим, что у нас получилось, и выведем на экран:

HackWare.ru
Этичный хакинг и тестирование на проникновение, информационная безопасность
Парсинг сайтов: азы, продвинутые техники, сложные случаи
Что такое парсинг
Парсинг (parsing) – это буквально с английского «разбор», «анализ». Под парсингом обычно имеют ввиду нахождение, вычленение определённой информации.
Парсинг сайтов может использоваться при создании сервиса, а также при тестировании на проникновение. Для пентестера веб-сайтов, навык парсинга сайтов является базовыми, т.е. аудитор безопасности (хакер) должен это уметь.
Умение правильно выделить информацию зависит от мастерства владения регулярными выражениями и командой grep (очень рекомендую это освоить – потрясающее испытание для мозга!). В этой же статье будут рассмотрены проблемные моменты получения данных, поскольку все сайты разные и вас могут ждать необычные ситуации, которые при первом взгляде могут поставить в тупик.
В качестве примера парсинга сайтов, вот одна единственная команда, которая получает заголовки последних десяти статей, опубликованных на HackWare.ru:

Подобным образом можно автоматизировать получение и извлечение любой информации с любого сайта.
Особенности парсинга веб-сайтов
Одной из особенностей парсинга веб-сайтов является то, что как правило мы работаем с исходным кодом страницы, т.е. HTML кодом, а не тем текстом, который показывается пользователю. Т.е. при создании регулярного выражения grep нужно основываться на исходном коде, а не на результатах рендеринга. Хотя имеются инструменты и для работы с текстом, получающимся в результате рендеринга веб-страницы – об этом также будет рассказано ниже.
В этом разделе основной упор сделан на парсинг из командной строки Linux, поскольку это самая обычная (и привычная) среда работы для тестера на проникновение веб-приложений. Будут показаны примеры использования разных инструментов, доступных из консоли Linux. Тем не менее, описанные здесь приёмы можно использовать в других операционных системах (например, cURL доступна и в Windows), а также в качестве библиотеки для использования в разных языках программирования.
Подразумевается, что вы понимаете принципы работы командной строки Linux. Если это не так, то рекомендуется ознакомиться с циклом:
Получение содержимого сайта в командной строке
Самым простым способом получения содержимого веб-страницы, а точнее говоря, её HTML кода, является команда вида:
В качестве ХОСТа может быть адрес сайта (URL) или IP. На самом деле, curl поддерживает много разных протоколов – но здесь мы говорим именно о сайтах.
Хорошей практикой является заключать URL (ссылки на сайты и на страницы) в одинарные или двойные кавычки, поскольку эти адреса могут содержать специальные символы, имеющие особое значение для Bash. К таким символам относятся амперсант (&), решётка (#) и другие.
Чтобы в командной строке присвоить полученные данные переменной, можно использовать следующую конструкцию:
Также полученное содержимое веб-страницы зачастую передаётся по трубе для обработке в других командах:
Реальные примеры даны чуть ниже.
Отключение статистики при использовании cURL
Когда вы будете передавать полученное содержимое по трубе (|), то вы увидите, что команда curl показывает статистику о скорости, времени, количестве переданных данных:

Чтобы отключить вывод статистики, используйте опцию -s, например:
Автоматически следовать редиректам с cURL
Вы можете дать указание cURL следовать редиректам, т.е. открывать страницу, на которую делает редирект (перенаправление) та страница, которую мы в данный момент пытаемся открыть.
Например, если я попытаюсь открыть сайт следующим образом (обратите внимание на HTTP вместо HTTPS):
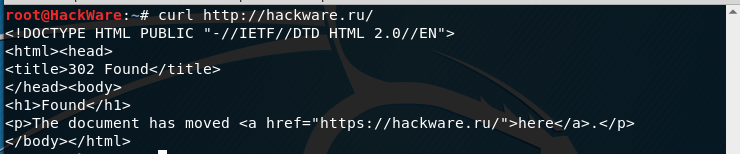
Чтобы curl переходила по перенаправлением используется опция -L:
Подмена User Agent при использовании cURL
Удалённый сервер видит, какая программа пытается к нему подключиться: это веб-браузер, или поисковый робот, или кто-то ещё. По умолчанию cURL передаёт в качестве User-Agent что-то вроде «curl/7.58.0». Т.е. сервер видит, что подключается не веб-браузер, а консольная утилита.
Некоторые веб-сайты не хотят ничего показывать консольным утилитам, например, если при обычном запросе вида:
Вам не показывается содержимое веб-сайта (может выподиться сообщение о запрете доступа или о плохом боте), но при открытии в браузере вы можете видеть страницу, то используя опцию -A мы можем указать любой пользовательский агент, например:
Получение в cURL страниц со сжатием
Иногда при использовании cURL появляется предупреждение:
Его можно увидеть, например при попытке получить страницу с kali.org,
Причина в том, что веб-страница передаётся с использованием компрессии (сжатия), чтобы увидеть данные достаточно использовать опцию —compressed:
В результате будет выведен обычный HTML код запрашиваемой страницы.
Неправильная кодировка при использовании cURL
В настоящее время на большинстве сайтов используется кодировка UTF-8, с которой cURL прекрасно работает.
Но, например, при открытии некоторых сайтов:
Вместо кириллицы мы увидим крякозяблы:
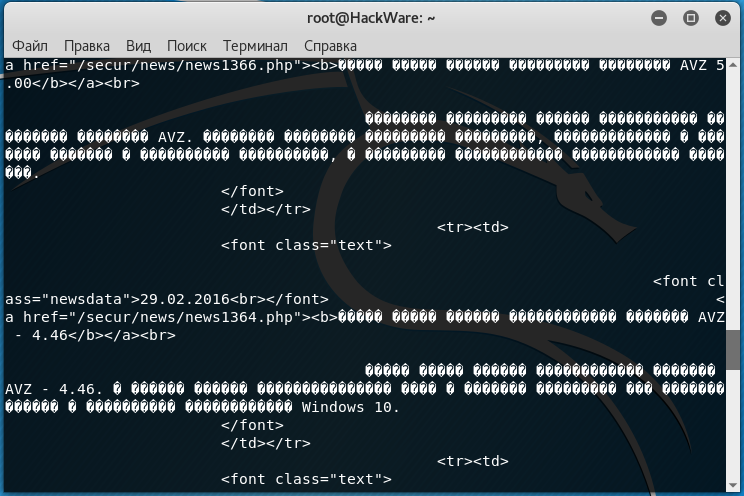
Кодировку можно преобразовать «на лету» с помощью команды iconv. Но нужно знать, какая кодировка используется на сайте. Для этого обычно достаточно заглянуть в исходный код веб-страницы и найти там строку, содержащую слово charset, например:
Эта строка означает, что используется кодировка windows-1251.
Для преобразования из кодировки windows-1251 в кодировку UTF-8 с помощью iconv команда выглядит так:
Совместим её с командой curl:
После этого вместо крякозяблов вы увидите русские буквы.
Изменение реферера с cURL
Реферер (Referrer URL) – это информация о странице, с которой пользователь пришёл на данную страницу, т.е. это та страница, на которой имеется ссылка, по которой кликнул пользователь, чтобы попасть на текущую страницу. Иногда веб-сайты не показывают информацию, если пользователь не содержит в качестве реферера правильную информацию (либо показывают различную информацию, в зависимости от типа реферера (поисковая система, другая страница этого же сайта, другой сайт)). Вы можете манипулировать значением реферера используя опцию -e. После которой в кавычках укажите желаемое значение. Реальный пример будет чуть ниже.
Вход на страницу с базовой аутентификацией при помощи cURL
Иногда веб-сайты требуют имя пользователя и пароль для просмотра их содержимого. С помощью опции -u вы можете передать эти учётные данные из cURL на веб-сервер как показано ниже.
По умолчанию curl использует базовую аутентификацию. Мы можем задать иные методы аутентификации используя —ntlm | —digest.
cURL и аутентификация в веб-формах (передача данных методом GET и POST)
Аутентификация в веб-формах – это тот случай, когда мы вводим логин и пароль в форму на сайте. Именно такая аутентификация используется при входе в почту, на форумы и т. д.
Использование curl для получения страницы после HTTP аутентификации очень сильно различается в зависимости от конкретного сайта и его движка. Обычно, схема действий следующая:
1) С помощью Burp Suite или Wireshark узнать, как именно происходит передача данных. Необходимо знать: адрес страницы, на которую происходит передача данных, метод передачи (GET или POST), передаваемая строка.
2) Когда информация собрана, то curl запускается дважды – в первый раз для аутентификации и получения кукиз, второй раз – с использованием полученных кукиз происходит обращение к странице, на которой содержаться нужные сведения.
Используя веб-браузер, для нас получение и использование кукиз происходит незаметно. При переходе на другую страницу или даже закрытии браузера, кукиз не стираются – они хранятся на компьютере и используются при заходе на сайт, для которого предназначены. Но curl по умолчанию кукиз не хранит. И поэтому после успешной аутентификации на сайте с помощью curl, если мы не позаботившись о кукиз вновь запустим curl, мы не сможем получить данные.
Для сохранения кукиз используется опция —cookie-jar, после которой нужно указать имя файла. Для передачи данных методом POST используется опция —data. Пример (пароль заменён на неверный):
Далее для получения информации со страницы, доступ на которую имеют только зарегестрированные пользователи, нужно использовать опцию -b, после которой нужно указать путь до файла с ранее сохранёнными кукиз:
Эта схема может не работать в некоторых случаях, поскольку веб-приложение может требовать указание кукиз при использовании первой команды (встречалось такое поведение на некоторых роутерах), также может понадобиться указать верного реферера, либо другие данные, чтобы аутентификация прошла успешно.
Извлечение информации из заголовков при использовании cURL
Иногда необходимо извлечь информацию из заголовка, либо просто узнать, куда делается перенаправление.
Заголовки – это некоторая техническая информация, которой обмениваются клиент (веб-браузер или программа curl) с веб-приложением (веб-сервером). Обычно нам не видна эта информация, она включает в себя такие данные как кукиз, перенаправления (редиректы), данные о User Agent, кодировка, наличие сжатия, информация о рукопожатии при использовании HTTPS, версия HTTP и т.д.
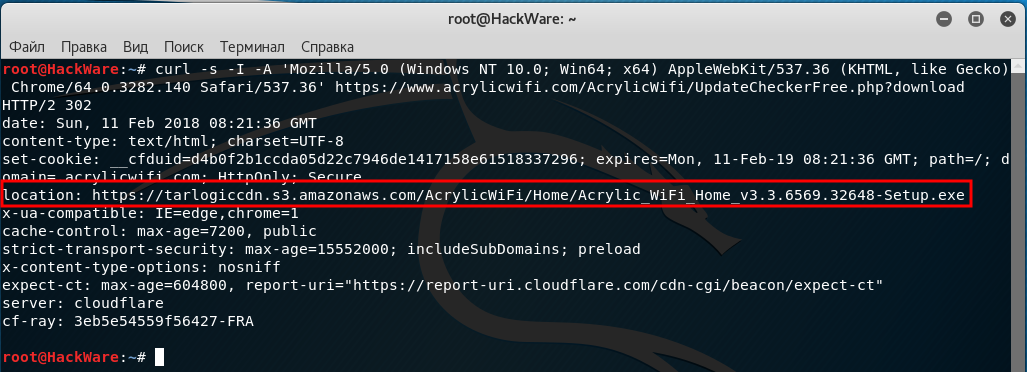
В моей практике есть реальный пример необходимости парсить заголовки. Есть программа Acrylic Wi-Fi Home, её особенностью является то, что на сайте нигде нет информации о текущей версии программы. Но номер версии содержится в скачиваемом файле, который имеет имя вида Acrylic_WiFi_Home_v3.3.6569.32648-Setup.exe. При этом имя файла также отсутствует в исходном HTML коде, поскольку при нажатии на кнопку «Скачать» идёт автоматический редирект на сторонний сайт. При подготовке парсера для softocracy, я столкнулся с ситуацией, что мне необходимо получить имя файла, причём желательно не скачивая его.
В этой команде имеются уже знакомые нам опции -s (подавление вывода) и -A (для указания своего пользовательского агента).
Новой опцией является -I, которая означает показывать только заголовки. Т.е. не будет показываться HTML код, поскольку он нам не нужен.
На этом скриншоте видно, в какой именно момент отправляется информация о новой ссылке для перехода:
Аналоогичный пример для хорошо известной в определённых кругах программы Maltego (когда-то на сайте отсутствовала информация о версии и пришлось писать парсер заголовков):
Обратите внимание, что в этой команде не использовалась опция -I, поскольку она вызывает ошибку:
Суть ошибки в том, что можно выбрать только один метод запроса HTTP, а используются сразу два: POST и HEAD.
Кстати, опция -d (её псевдоним упоминался выше (—data), когда мы говорили про HTML аутентификацию через формы на веб-сайтах), передаёт данные методом POST, т.е. будто бы нажали на кнопку «Отправить» на веб-странице.
В последней команде используется новая для нас опция -v, которая увеличивает вербальность, т.е. количество показываемой информации. Но особенностью опции -v является то, что она дополнительные сведения (заголовки и прочее) выводит не в стандартный вывод (stdout), а в стандартный вывод ошибок (stderr). Хотя в консоли всё это выглядит одинаково, но команда grep перестаёт анализировать заголовки (как это происходит в случае с -I, которая выводит заголовки в стандартный вывод). В этом можно убедиться используя предыдущую команду без 2>&1:
Строка с Location никогда не будет найдена, хотя на экране она явно присутствует.
Конструкция 2>&1 перенаправляет стандартный вывод ошибок в стандартный вывод, в результате внешне ничего не меняется, но теперь grep может обрабатывать эти строки.
Более сложная команда для предыдущего обработчика форм (попробуйте в ней разобраться самостоятельно):
Парсинг сайта, на котором текст создаётся с помощью JavaScript
Если контент веб-страницы формируется методами JavaScript, то можно найти необходимый файл с кодом JavaScript и парсить его. Но иногда код слишком сложный или даже обфусцированный. В этом случае поможет PhantomJS.
Особенностью PhantomJS ялвяется то, что это настоящий инструмент командной строки, т.е. может работать на безголовых машинах. Но при этом он может получать содержимое веб-страницы так, как будто бы вы её открыли в обычном веб-браузере, в том числе после работы JavaScript.
Можно получать веб-страницы как изображение, так и просто текст, выводимый пользователю.
К примеру, мне нужно распарсить страницу https://support.microsoft.com/en-us/help/12387/windows-10-update-history и взять с неё номер версии последней официальной сборки Windows. Для этого я создаю файл lovems.js следующего содержания:
Для его запуска использую PhantomJS:
В консоль будет выведено в текстовом виде содержимое веб-страницы, которое показывается пользователям, открывшим страницу в обычном веб-браузере.
Чтобы отфильтровать нужные мне сведения о последней сборке:
Будет выведено что-то вроде 15063.877.
Смотрите также пример использования PhantomJS когда нужно отправлять POST запрос перед получением страницы: «Как с помощью PhantomJS отправить POST запрос».
Парсинг в командной строке RSS, XML, JSON и других сложных форматов
RSS, XML, JSON и т.п. – это текстовые файлы, в которых данные структурированы определённым образом. Для разбора этих файлов можно, конечно, использовать средства Bash, но можно сильно упростить себе задачу, если задействовать PHP.
В PHP есть ряд готовых классов (функций), которые могут упростить задачу. Например SimpleXML для обработки RSS, XML. JSON для JavaScript Object Notation.
Если в системе установлен PHP, то необязательно использовать веб-сервер, чтобы запустить PHP скрипт. Это можно сделать прямо из командной строки. Например, имеется задача из файла по адресу https://hackware.ru/?feed=rss2 извлечь имена всех статей. Для этого создадим файл parseXML.php со следующим содержимым:
Запустить файл можно так:

Кстати, cURL можно было бы использовать прямо из PHP скрипта. Поэтому можно парсить в PHP не прибегая к услугам Bash. В качестве примера, создайте файл parseXML2.php со следующем содержимым:
И запустите его следующим образом из командной строки:
Этот же самый файл parseXML2.php можно поместить в директорию веб-сервера и открыть в браузере.
Заключение
Здесь рассмотрены ситуации, с которыми вы можете столкнуться при парсинге веб-сайтов. Изученный материал поможет лучше понимать, что происходит в тот момент, когда вы подключаетесь к веб-сайту. Поскольку пентестер часто использует не веб-браузеры для работы с веб-сайтами: различные сканеры и инструменты, то знание о реферерах, User Agent, кукиз, заголовках, кодировках, аутентификации поможет быстрее разобраться с проблемой, если она возникнет.
Для часто встречающихся задач (сбор email адресов, ссылок) уже существует достаточно много инструментов – и часто можно взять готовое решение, а не изобретать велосипед. Но с помощью curl и других утилит командной строки вы сможете максимально гибко настроить получение данных с любого сайта.