λ-исчисление. Часть первая: история и теория
Идею, короткий план и ссылки на основные источники для этой статьи мне подал хабраюзер z6Dabrata, за что ему огромнейшее спасибо.
UPD: в текст внесены некоторые изменения с целью сделать его более понятным. Смысловая составляющая осталась прежней.
Вступление
Возможно, у этой системы найдутся приложения не только
в роли логического исчисления. (Алонзо Чёрч, 1932)
Вообще говоря, лямбда-исчисление не относится к предметам, которые «должен знать каждый уважающий себя программист». Это такая теоретическая штука, изучение которой необходимо, когда вы собираетесь заняться исследованием систем типов или хотите создать свой функциональный язык программирования. Тем не менее, если у вас есть желание разобраться в том, что лежит в основе Haskell, ML и им подобных, «сдвинуть точку сборки» на написание кода или просто расширить свой кругозор, то прошу под кат.
Начнём мы с традиционного (но краткого) экскурса в историю. В 30-х годах прошлого века перед математиками встала так называемая проблема разрешения (Entscheidungsproblem), сформулированная Давидом Гильбертом. Суть её в том, что вот есть у нас некий формальный язык, на котором можно написать какое-либо утверждение. Существует ли алгоритм, за конечное число шагов определяющий его истинность или ложность? Ответ был найден двумя великими учёными того времени Алонзо Чёрчем и Аланом Тьюрингом. Они показали (первый — с помощью изобретённого им λ-исчисления, а второй — теории машины Тьюринга), что для арифметики такого алгоритма не существует в принципе, т.е. Entscheidungsproblem в общем случае неразрешима.
Так лямбда-исчисление впервые громко заявило о себе, но ещё пару десятков лет продолжало быть достоянием математической логики. Пока в середине 60-х Питер Ландин не отметил, что сложный язык программирования проще изучать, сформулировав его ядро в виде небольшого базового исчисления, выражающего самые существенные механизмы языка и дополненного набором удобных производных форм, поведение которых можно выразить путем перевода на язык базового исчисления. В качестве такой основы Ландин использовал лямбда-исчисление Чёрча. И всё заверте…
λ-исчисление: основные понятия
Синтаксис
В основе лямбда-исчисления лежит понятие, известное ныне каждому программисту, — анонимная функция. В нём нет встроенных констант, элементарных операторов, чисел, арифметических операций, условных выражений, циклов и т. п. — только функции, только хардкор. Потому что лямбда-исчисление — это не язык программирования, а формальный аппарат, способный определить в своих терминах любую языковую конструкцию или алгоритм. В этом смысле оно созвучно машине Тьюринга, только соответствует функциональной парадигме, а не императивной.
Мы с вами рассмотрим его наиболее простую форму: чистое нетипизированное лямбда-исчисление, и вот что конкретно будет в нашем распоряжении.
Процесс вычисления
Рассмотрим следующий терм-применение:
Существует несколько стратегий выбора редекса для очередного шага вычисления. Рассматривать их мы будем на примере следующего терма:
который для простоты можно переписать как
(напомним, что id — это функция тождества вида λx.x )
В этом терме содержится три редекса: 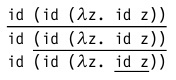
Недостатком стратегии вызова по значению является то, что она может зациклиться и не найти существующее нормальное значение терма. Рассмотрим для примера выражение
(λx.λy. x) z ((λx.x x)(λx.x x))
Этот терм имеет нормальную форму z несмотря на то, что его второй аргумент такой формой не обладает. На её-то вычислении и зависнет стратегия вызова по значению, в то время как стратегия вызова по имени начнёт с самого внешнего терма и там определит, что второй аргумент не нужен в принципе. Вывод: если у редекса есть нормальная форма, то «ленивая» стратегия её обязательно найдёт.
На этом закончим вводную в лямбда-исчисление. В следующей статье мы займёмся тем, ради чего всё и затевалось: программированием на λ-исчислении.
Лямбда-исчисление

А сегодня немного теории. Я не считаю, что лямбда-исчисление является необходимым знанием для любого программиста. Однако, если вам нравится докапываться до истоков, чтобы понять на чем основаны многие языки программирования, вы любознательны и стремитесь познать все в этом мире или просто хотите сдать экзамен по функциональном программированию (как, например, я), то этот пост для вас.
Что это такое
Но речь сегодня не о SQL, а о функциональных языках. Именно для них лямбда-исчисление является основой. Функциональные языки далеко не столь популярны, как, например, объектно-ориентированные, но тем не менее прочно занимают свою нишу. Кроме того, многие идеи из функционального программирования и лямда-исчисления постепенно прокрадываются в другие языки, под видом новых фич.
Если вы изучали формальные языки, то знаете о таком понятии как Машина Тьюринга. Эта вычислительная абстракция определяет класс вычислимых функций. Этот класс столь важен, так как по тезису Черча он эквивалентен понятию алгоритма. Другими словами, любую программу, которую можно запрограммировать на вычислительном устройстве, можно воспроизвести и на машине Тьюринга. А для нас главное то, что лямбда-исчисление по мощности эквивалентно машине Тьюринга и определяет этот же класс функций. Причем создателем лямбда-исчисления является тот самый Алонзо Черч!
Основные понятия
В нотации лямбда-исчисления есть всего три типа выражений:
Сразу пара примеров:
Соглашения
Несколько соглашений для понимания, в каком порядке правильно читать выражения:
Области видимости переменных
Определим контекст переменной, в котором она может быть использована. Абстракция ` lambda x.E ` связывает переменную ` x `. В результате мы получаем следующие понятия:
Вычисление лямбда-выражений
Вычисление выражений заключается в последовательном применении подстановок. Подстановкой ` E’ ` вместо ` x ` в ` E \ ` (запись: ` [E’//x]E ` ) называется выполнение двух шагов:
Функции нескольких переменных
Как результат мы получили функцию от одного аргумента, которая возвращает еще одну функцию от одного аргумента. Такое преобразование называется каррирование (в честь Хаскелла Карри назвали и язык программирования, и эту операцию), а функция, возвращающая другую, называется функцией высшего порядка.
Порядок вычислений
Бывают ситуации, когда произвести вычисление можно несколькими способами. Например, в выражении ` (lambda y. (lambda x. x) y) E ` сначала можно подставлять ` y ` вместо ` x ` во внутреннее выражение, либо ` E ` вместо ` y ` во внешнее. Теорема Черча-Рассера говорит о том, что в не зависимости от последовательности операций, если вычисление завершится, результат будет одинаков. Тем не менее, эти два подхода принципиально отличаются. Рассмотрим их подробнее:
Кодирование типов
В чистом лямбда-исчислении есть только функции. Однако, программирование трудно представить без различных типов данных. Идея заключается в том, чтобы закодировать поведение конкретных типов в виде функций.
Аналогично, с помощью лямбда-исчисления можно выразить любые конструкции языков программирования, такие как циклы, ветвления, списки и тд.
Заключение
Лямбда-исчисление
Лямбда-исчисление (англ. lambda calculus) — формальная система, придуманная в 1930-х годах Алонзо Чёрчем. Лямбда-функция является, по сути, анонимной функцией. Эта концепция показала себя удобной и сейчас активно используется во многих языках программирования.
Содержание
Лямбда-исчисление [ править ]
| Определение: |
| Лямбда-выражением (англ. [math]\lambda[/math] -term) называется выражение, удовлетворяющее следующей грамматике: |
Пробел во втором правиле является терминалом грамматики. Иногда его обозначают как @, чтобы он не сливался с другими символами в выражении.
В первом случае функция является просто переменной. Во втором происходит аппликация (применение) одной функции к другой. Это аналогично вычислению функции-левого операнда на аргументе-правом операнде. В третьем — абстракция по переменной. В данном случае происходит создание функции одного аргумента с заданными именем аргумента и телом функции.
[math] x\\ (x\ z)\\ (\lambda x.(x\ z))\\ (\lambda z.(\lambda w.((\lambda y.((\lambda x.(x\ z))\ y))\ w)))\\ [/math]
Приоритет операций [ править ]
Свободные и связанные переменные [ править ]
Связанными переменными называются все переменные, по которым выше в дереве разбора были абстракции. Все остальные переменные называются свободными.
Связанные переменные — это аргументы функции. То есть для функции они являются локальными.
α-эквивалетность [ править ]
и замкнуто относительно следующих правил:
[math] P=_\alpha P’ \Rightarrow \forall x \in V: \lambda x.P=_\alpha \lambda x.P’\\ P=_\alpha P’ \Rightarrow \forall Z \in \Lambda : P Z =_\alpha P’Z\\ P=_\alpha P’ \Rightarrow \forall Z \in \Lambda : Z P =_\alpha Z P’\\ P=_\alpha P’ \Rightarrow P’=_\alpha P\\ P=_\alpha P’ \ \& \ P’=_\alpha P» \Rightarrow P=_\alpha P»\\[/math]
β-редукция [ править ]
и замкнуто относительно следующих правил
[math]P\to _\beta P’ \Rightarrow \forall x\in V:\lambda x.P\to _\beta \lambda x.P’\\ P\to _\beta P’ \Rightarrow \forall Z\in \Lambda : P\ Z\to _\beta P’\ Z\\ P\to _\beta P’ \Rightarrow \forall Z\in \Lambda : Z\ P\to _\beta Z\ P'[/math]
Каррирование [ править ]
Нотация Де Брауна [ править ]
Грамматику нотации можно задать как:
Примеры выражений в этой нотации:
Переменная называется свободной, если ей соответствует число, которое больше количества абстракций на пути до неё в дереве разбора.
Определение [ править ]
Введём на основе лямбда-исчисления аналог натуральных чисел, основанный на идее, что натуральное число — это или ноль, или увеличенное на единицу натуральное число.
+1 [ править ]
Сложение [ править ]
Сложение двух чисел похоже на прибавление единицы. Но только надо прибавить не единицу, а второе число.
[math]n[/math] раз применить [math]s[/math] к применённому [math]m[/math] раз [math]s[/math] к [math]z[/math]
[math](\operatorname
[math](\operatorname
Умножение [ править ]
[math](\operatorname
Возведение в степень [ править ]
It’s a kind of magic
[math](\operatorname
Логические значения [ править ]
Стандартные функции булевой логики:
Ещё одной важной функцией является функция проверки, является ли число нулём:
Пара [ править ]
Вычитание [ править ]
В отличие от всех предыдущих функций, вычитание для натуральных чисел определено только в случае, если уменьшаемое больше вычитаемого. Положим в противном случае результат равным нулю. Пусть уже есть функция, которая вычитает из числа единицу. Тогда на её основе легко сделать, собственно, вычитание.
Если вы ничего не поняли, не огорчайтесь. Вычитание придумал Клини, когда ему вырывали зуб мудрости. А сейчас наркоз уже не тот.
Сравнение [ править ]
Комбинатор неподвижной точки [ править ]
Попробуем выразить в лямбда-исчислении какую-нибудь функцию, использующую рекурсию. Например, факториал.
Лямбда исчисление обладаем замечательным свойством: у каждой функции есть неподвижная точка!
Рассмотрим следующую функцию.
[math]\operatorname
[math]Y\ = \ \lambda f.(\lambda x.f(x\ x))\ (\lambda x.f(x\ x))[/math]
Деление [ править ]
Воспользовавшись идеей о том, что можно делать рекурсивные функции, сделаем функцию, которая будет искать частное двух чисел.
[math]\operatorname
И остатка от деления
[math]\operatorname
Проверка на простоту [ править ]
[math]\operatorname
Следующее простое число. [math]\operatorname
[math]\operatorname
[math]\operatorname
Списки [ править ]
Для работы со списками чисел нам понадобятся следующие функции:
[math]\operatorname
[math]\operatorname
Выводы [ править ]
На основе этого всего уже можно реализовать эмулятор машины тьюринга: с помощью пар, списков чисел можно хранить состояния. С помощью рекурсии можно обрабатывать переходы. Входная строка будет даваться, например, закодированной аналогично списку: пара из длины и числа, характеризующего список степенями простых. Я бы продолжил это писать, но уже на операции [math]\operatorname
[1, 2][/math] я не дождался окончания выполнения. Скорость лямбда-исчисления как вычислителя печальна.Лямбда-исчисление
В этой главе мы узнаем о лямбда-исчислении. Лямбда-исчисление описывает понятие алгоритма. Ещё до появления компьютеров в 30-е годы двадцатого века математиков интересовал вопрос о возможности создания алгоритма, который мог бы на основе заданных аксиом дать ответ о том верно или нет некоторое логическое высказывание. Например у нас есть базовые утверждения и логические связки такие как “и”, “или”, “для любого из”, “существует один из”, с помощью которых мы можем строить из базовых высказываний составные. Некоторые из них окажутся ложными, а другие истинными. Нам интересно узнать какие. Но для решения этой задачи прежде всего необходимо было понять а что же такое алгоритм?
Ответ на этот вопрос дали Алонсо Чёрч (Alonso Church) и Алан Тьюринг (Alan Turing). Чёрч разработал лямбда-исчисление, а Тьюринг теорию машин Тьюринга. Оказалось, что задача автоматического определения истинности формул в общем случае не имеет решения.
В основе лямбда-исчисление лежит понятие функции. Мы можем составлять сложные функции из простейших, а также подставлять в функции аргументы, которые могут быть как константами так и другими функциями. Как только мы составили выражение мы можем передать его вычислителю. Он подставляет аргументы в функции и возвращает такое выражение, в котором невозможно далее проводить подстановки аргументов. Этот процесс проведения подстановок считается вычислением алгоритма.
В рамках теории машин Тьюринга алгоритм описывается по-другому. Машина Тьюринга имеет внутреннее состояние, Состояние содержит некоторое значение, которое изменяется по ходу работы машины. Машина живёт не сама по себе, она читает ленту символов. Лента символов – это большая цепочка букв. На каждую букву машина реагирует серией действий. Она может изменить значение состояния, обновить букву в ленте или перейти к следующему или предыдущему символу. Есть состояния, которые обозначают конец работы, они называются терминальными. Как только машина дойдёт до терминального состояния мы считаем, что вычисление алгоритма закончилось. После этого мы можем считать результат из состояний машины.
Функциональные языки программирования основаны на лямбда-исчислении. Поэтому мы будем говорить именно об этом описании алгоритма.
Лямбда исчисление без типов
Составление термов
Можно считать, что лямбда исчисление это такой маленький язык программирования. В нём есть множество символов, которые считаются переменными, они что-то обозначают и неделимы. В лямбда-исчислении программный код называется термом. Для написания программного кода у нас есть всего три правила:
$$(((Fun\ Arg1)\ Arg2)\ Arg3)$$
Точка сменилась на стрелку, а лямбда потеряла одну ножку. Теперь определим композицию. Композиция принимает две функции одного аргумента и направляет выход второй функции на вход первой:
Лямбда-исчисление на JavaScript
Привет! В этой статье я хочу в очередной раз взглянуть на лямбда-исчисление. Теоретическую сторону вопроса на хабре обсуждали уже множество раз, поэтому взглянем на то, как лямбда-исчисление может выглядеть на практике, например, на языке JavaScript (чтобы примеры можно было выполнять прямо в браузере).
Итак, основная идея: всё есть функция. Поэтому мы ограничим себя очень узким кругом возможностей языка: любое выражение будет либо анонимной функцией с одним аргументом ( x => expr ), либо вызовом функции ( f (x) ). То есть весь код будет выглядеть похожим образом:
Поскольку результатом работы функций будут другие функции, нам понадобится способ интерпретировать результат. Это единственное место, в котором пригодятся нетривиальные возможности JavaScript.
Базовые вещи
Начнём, как это принято, с условного ветвления. Введём две константы:
Это функции «двух аргументов», True возвращает первый аргумент, False возвращает второй аргумент. То есть, справедливы следующие утверждения:
Данные константы представляют логические истину и ложь, и позволяют написать функцию If :
Следующим делом введём первую «структуру данных» — пару. Определение выглядит следующим образом:
Оно выглядит немного страннее, но в нём есть смысл. Пара в данном случае есть функция, инкапсулирующая внутри себя 2 значения и способная передать их своему параметру при вызове. Подобным образом можно описать кортеж любой длины:
Вообще говоря, с подобным арсеналом мы уже могли бы определить Byte как кортеж из 8 логических значений, Int как кортеж из 4 Byte и реализовать на них машинную арифметику, но дело это рутинное и удовольствия никакого не принесёт. Есть более красивый способ описать натуральные числа — арифметика Чёрча.
Арифметика
Арифметика Чёрча описывает множество натуральных чисел с нулём как функции от двух аргументов:
Первый аргумент — это функция, второй аргумент — это что-то, к чему функция применяется n раз. Для их построения, по сути, нужны только ноль и функция +1 :
Succ накидывает слева ещё один вызов s на уже имеющуюся цепочку вызовов, тем самым возвращая нам следующее по порядку натуральное число. Если данная функция кажется сложной, есть альтернативный вариант. Результат его работы будет абсолютно таким же, но накидывание s здесь происходит справа:
Тут стоит ещё описать способ преобразования чисел Чёрча во всем нам знакомый int — это в точности применение функции x => x + 1 к нулю n раз:
Аналогично определяются операции сложения, умножения и т.д.:
Таки образом можно продолжать реализовывать стрелочную нотацию, но смысла в этом нет: к этому моменту принцип работы с числами должен быть понятен.
Следующий шаг — вычитание. Следуя только что появившейся традиции, его реализация будет вот такой:
но остаётся проблемой реализация функции Pred. К счастью, Клини придумал её за нас.
Для полноты картины приведу реализации операций сравнения:
Списки
Списки кодируются практически так же, как и натуральные числа — это тоже функции двух аргументов.
Если вы знакомы с функциональными операциями на списках, то, вероятно, уже заметили, что эта структура описывает правую свёртку. Поэтому и реализуется она тривиально:
Теперь реализуем стандартные операции для персистентных списков — добавление в начало, получение «головы» и «хвоста» списка.
Пустые скобки в конце описания Head — это голова пустого списка. В корректной программе данное значение никогда не должно быть использовано, поэтому я и выбрал синтаксически наименьшую величину. Вообще говоря, внутри этих скобок можно писать всё, что угодно. Позднее в статье будет ещё одно место, где я буду использовать пустые скобки по абсолютно той же причине.
Функция получения хвоста списка практически полностью повторяет функцию получения предыдущего натурального числа. По той же причине хвост пустого списка будет пустым списком.
Как пример использования, приведу реализацию функции map и ещё некоторых других:
Map заменяет каждый элемент списка результатом вызова функции f на нём.
Length и IsEmpty говорят сами за себя. toList и toIntList будут полезны для тестирования и для вывода списков в консоль.
Рекурсия
К этому моменту работа исключительно с функциями стала подозрительно похожей на «нормальное» программирование. Пришло время всё испортить. Поскольку мы ограничили себя лишь объявлением и вызовом функций, у нас полностью отсутствует любой синтаксический сахар, а значит, многие простые вещи нам придётся записывать сложным образом.
Видите ошибку? Если f не останавливается на пустом списке, то и OnNonEmpty не остановится, хотя должна. Дело в том, что JavaScript предоставляет нам аппликативный порядок вычислений, то есть все аргументы функции вычисляются до её вызова, никакой ленивости. А оператор If должен вычислять лишь одну ветку в зависимости от условия. Поэтому функцию нужно переписать, и красивее она от этого не станет.
Вторая проблема — рекурсия. Внутри функции мы можем обращаться только к её формальным аргументам. Это значит, что функция не может ссылаться сама на себя по имени.
«Главное свойство» комбинатора даёт прекрасный «побочный эффект»: возможность реализации рекурсии. Например, запись:
После этого можно реализовать наш первый полезный алгоритм — алгоритм Евклида. Забавно, но он вышел ничуть не сложнее поиска остатка от деления.
Последовательности
Последняя структура данных, которой я коснусь, это «бесконечные списки», или последовательности. Функциональное программирование славится возможностью работать с подобными объектами, и я просто не могу обойти их стороной.
Объявляются последовательности следующим образом:
Хвост последовательности в конструкторе — это функция вычисления новой последовательности, а не готовый результат. Такой подход обеспечивает возможность генерировать хвост бесконечной длины.
Для возможности тестирования напишем функцию получения первых n элементов:
Если хотите поупражняться — реализуйте SeqTake без рекурсии. Это возможно, я гарантирую.
Теперь стоит привести пример какой-нибудь последовательности. Пусть это будут натуральные числа — всё-таки приходится работать только с тем, что уже реализовано:
Осталось совсем немного, последние 2 функции, и они самые громоздкие из тех, что есть в данном тексте. Первая — функция фильтрации последовательности. Она находит в передаваемой последовательности все элементы, удовлетворяющие переданному предикату:
В случае, если головной элемент не выполняет предикат, SeqFilter возвращает отфильтрованный хвост. В противном случае это будет последовательность из текущей головы и всё того же отфильтрованного хвоста.
Вторая — последовательность простых чисел. Очередной вариант Решета Эратосфена в моём исполнении:
Эту функцию можно назвать кульминацией статьи. Принцип её работы проще будет понять на псевдокоде:
Не знаю, как вас, а меня всё ещё удивляет, что подобные вещи возможно написать с помощью лишь чистых функций!
Заключение
В итоге у меня получилось такое вот странное введение в LISP на примере языка JavaScript. Надеюсь я смог показать, что абстрактные математические идеи на самом деле очень близки к реальности программирования. И после подобного взгляда лямбда-исчисление перестанет выглядеть чем-то чересчур академичным.
Ну и, конечно, вот ссылка на Github со всем кодом из статьи.