Перемычки на жестком диске
Часть 2
Но, опять же, прежде чем приступить к конфигурированию, расставляя перемычки, надо сначала четко себе представлять как это все функционирует!

Вы думаете нельзя сделать наоборот? Можно! 🙂 И это будет прекрасно работать, но в статье я периодически буду упоминать слово «стандарт» или «спецификация» и вот тут мы должны будем почтенно умолкнуть и согласиться, положившись на то, что люди из «INCITS» (InterNational Committee for Information Tecnology Standards) не просто так пишут документацию 🙂
Видите, как не просто нам добраться до перемычек на жестком диске! Тема достаточно запутанная и клинически осложняется тем фактом, что в свое время (еще до окончательной регламентации всех нюансов выше указанной организацией) производители «железа» умудрились понаделывать достаточно оборудования, которое оказывалось несовместимым между собой.

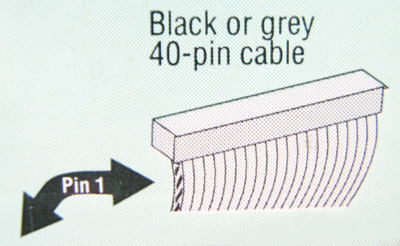
Как видите, первая «жила» (Pin) честно прописана на самом диске, с указанием стрелкой с какой стороны разъема ее надо подключать.
Сказанное выше справедливо и в отношении подключения к контроллеру на материнской плате. Вы спросите: Как можно неправильно подключить IDE (ATA) кабель, если он имеет «ключ» на своем разъеме?
Дело в том, что в период перехода от интерфейсного кабеля с 40-ка проводниками на 80-ти жильный (с дополнительным заземлением), первый из них не имел этого «ключа» и его можно было запросто воткнуть в контроллер не той стороной. Одно из фото выше как раз крупным планом показывает оба типа интерфейсного кабеля (80-ти жильный имеет один отсутствующий контакт в середине разъема).

Видите цифру «1» обведенную красным цветом? Вот это и есть этот самый первый контакт. Что получается в итоге? Зная (по маркировке) где находится первый пин на интерфейсном шлейфе и первый контакт на самой плате мы однозначно сможем правильно подключить все это хозяйство с первого раза 🙂
Еще одна подсказка состоит в том, что шлейф данных должен всегда (мимолетно вспомним о разных китайских производителях) устанавливаться первым (маркированным) пином в сторону разъема питания жесткого диска. Как-то запутанно звучит, правда? Лучше один раз увидеть на фото ниже:

Давайте посмотрим внимательнее на раздел, касающийся перемычек жесткого диска.


Давайте ненадолго остановимся и подумаем, для чего нужна вся эта чехарда с джамперами на жестком диске? Как Вы помните, ATA стандарт является по своей природе параллельным интерфейсом. Это значит, что каждый канал в любой момент времени может обрабатывать только один запрос к одному (от одного) устройства. Следующий запрос, даже к другому устройству, будет ожидать завершения выполнения текущего обращения. Разные IDE каналы при этом могут работать совершенно автономно.
Смотрим на фото выше еще раз. Что у нас там на очереди? «Master with non-ATA compatible slave» (ведущий с не совместимым ATA ведомым). Сложно сходу придумать, зачем такой режим может понадобиться. Возможно тогда, когда компьютер не распознает «slave» и мы, таким образом, отказываемся от его идентификации, но загрузка операционной системы становится возможной. Как видно из картинки, в этом случае нам надо задействовать две перемычки одновременно. Вторую можно взять с любого другого привода, ну или замкнуть два нужных штырька чем-то из подручных средств 🙂
Хотел показать Вам еще одно фото с информацией как расставить перемычки на винчестере от фирмы Fujitsu.


Извлечь джампер можно пальцами (при определенной сноровке) или с помощью тонкого пинцета. Просто вытаскиваете его и переставляете на два соседних контакта, согласно маркировке.
Вот как выглядит перемычка-джампер на стандартном DVD-ROM приводе:

В завершении статьи хотелось бы дать общие рекомендации относительно подключения разнородных устройств к одному IDE контроллеру. Понятно, что сначала Вы должны будете в определенном порядке выставить перемычки на жестких дисках или ATAPI устройствах (CD или DVD приводах).
Что касается эмпирических наблюдений (моих личных и не только), то рекомендация будет следующая: не стоит подключать два активно используемых узла к одному IDE каналу. В идеале каждое устройство (особенно это касается жестких дисков) стоит подключать к отдельному каналу передачи данных. Все современные чипсеты, конечно же, поддерживают возможность использования различных режимов передачи для разных накопителей, но, как показывает практика, злоупотреблять этим не стоит 🙂
Две комплектующие, существенно различающиеся по скорости, лучше все-таки разнести по разным каналам. Не рекомендуется подключать к одному контроллеру жесткий диск и ATAPI-устройство (например, CD-ROM). Нюанс в том, что ATAPI протокол передачи данных использует другую систему команд, а любые данного типа много медленнее жесткого диска, что может замедлить работу последнего.
В случае использования двух оптических приводов, их лучше установить отдельно на один шлейф, подключаемый ко второму IDE контроллеру. Один устанавливается в режим «Master», другой – в «Slave». Причем пишущий привод желательно выставить с помощью перемычек, как ведущий.
Как правильно производить подключение, смотрите в видео ниже:
Что такое репликация данных
Репликация — одна из техник масштабирования баз данных.
Состоит эта техника в том, что данные с одного сервера базы данных постоянно копируются (реплицируются) на один или несколько других (называемые репликами). Для приложения появляется возможность использовать не один сервер для обработки всех запросов, а несколько. Таким образом появляется возможность распределить нагрузку с одного сервера на несколько.
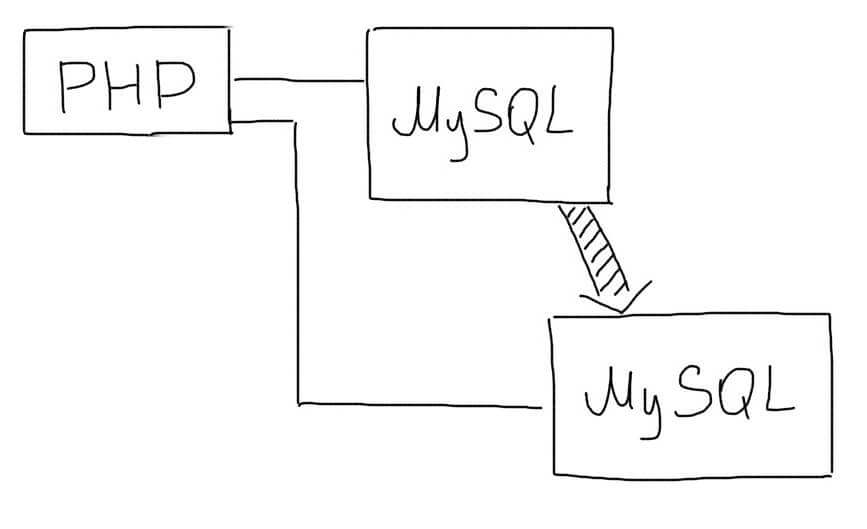
Существует два основных подхода при работе с репликацией данных:
Master-Slave репликация
В этом подходе выделяется один основной сервер базы данных, который называется Master. На нем происходят все изменения в данных (любые запросы INSERT/UPDATE/DELETE ).
Slave сервер постоянно копирует все изменения с Master. С приложения на Slave-сервер отправляются запросы чтения данных (запросы SELECT ). Таким образом Master-сервер отвечает за изменения данных, а Slave за чтение.
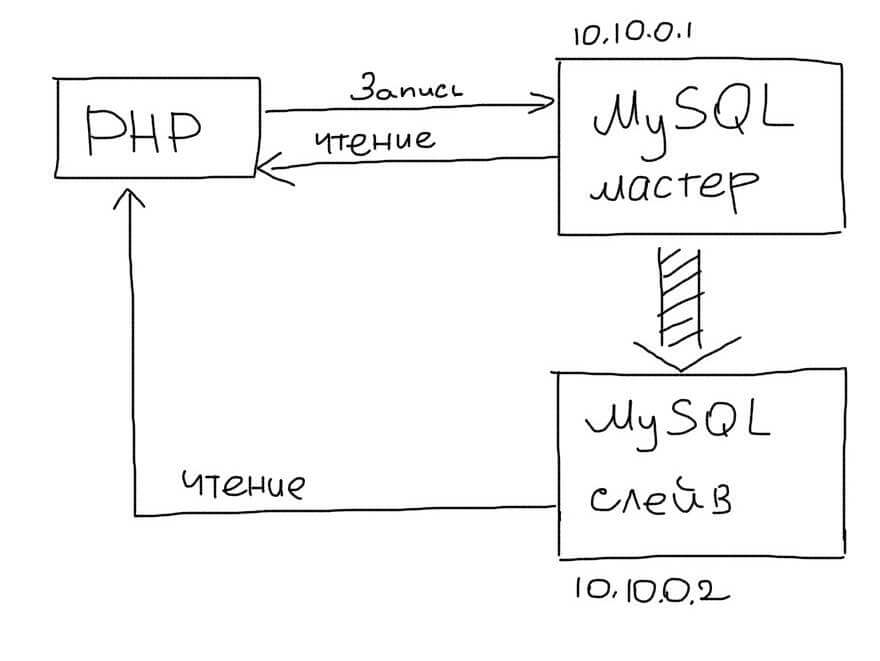
В приложении нужно использовать два соединения — одно для Master, второе — для Slave:
(Используем два соединения — для Master и Slave — для записи и чтения соответственно)
Несколько Slave серверов
Преимущество этого типа репликации в том, что мы можем использовать более одного Slave сервера. Обычно следует использовать не более 20 Slave серверов при работе с одним Master.
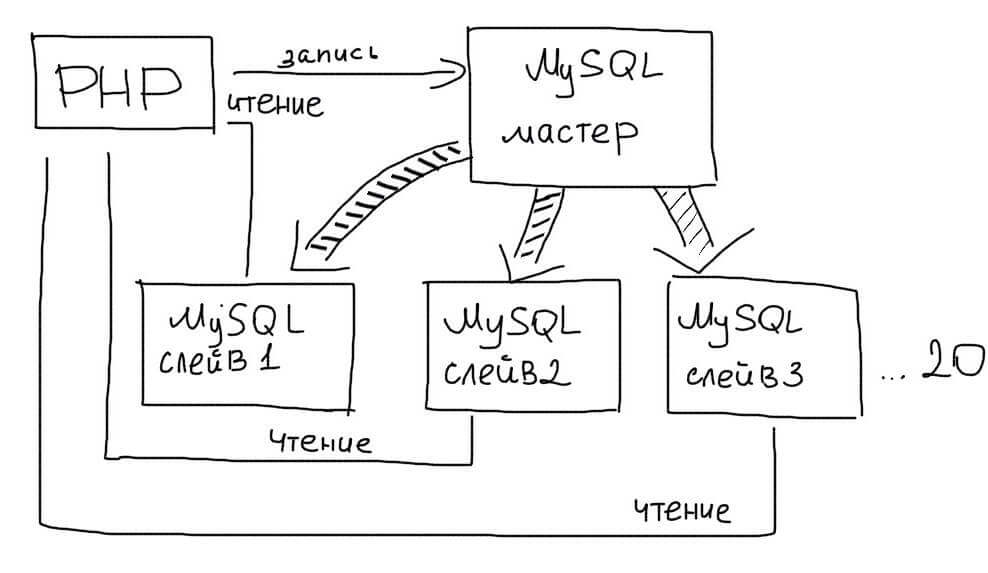
Тогда приложение выбирает случайным образом один из Slave серверов для обработки запросов:
Задержка репликации
Асинхронность репликации означает, что данные на Slave могут появиться с небольшой задержкой. Поэтому, в последовательных операциях необходимо использовать чтение с Master, чтобы получить актуальные данные:
(При обращении к изменяемым данным, необходимо использовать Master-соединение)
Выход из строя
При выходе из строя Slave, достаточно просто переключить все приложение на работу с Master. После этого восстановить репликацию на Slave и снова его запустить.
Если выходит из строя Master, нужно переключить все операции (и чтения и записи) на Slave. Таким образом он станет новым Master. После восстановления старого Master, настроить на нем реплику, и он станет новым Slave.
Резервирование
Намного чаще репликацию Master-Slave используют не для масштабирования, а для резервирования. В этом случае, Master сервер обрабатывает все запросы от приложения. Slave сервер работает в пассивном режиме. Но в случае выхода из строя Master, все операции переключаются на Slave.
Master-Master репликация
В этой схеме, любой из серверов может использоваться как для чтения так и для записи:
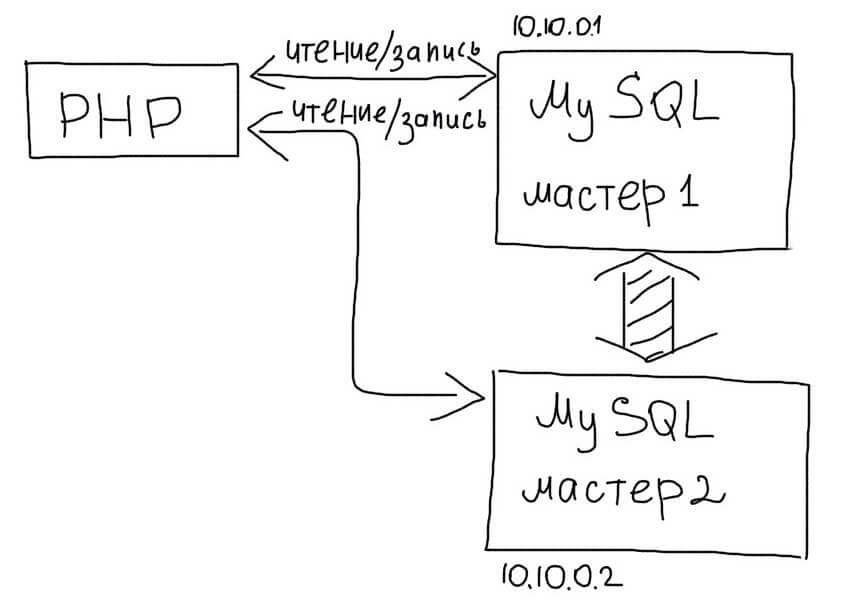
При использовании такого типа репликации достаточно выбирать случайное соединение из доступных Master серверов:
(Выбор случайного Master для обработки соединений)
Выход из строя
Вероятные поломки делают Master-Master репликацию непривлекательной. Выход из строя одного из серверов практически всегда приводит к потере каких-то данных. Последующее восстановление также сильно затрудняется необходимостью ручного анализа данных, которые успели либо не успели скопироваться.
Используйте Master-Master репликацию только в крайнем случае. Вместо нее лучше пользоваться техникой “ручной” репликации, описанной ниже.
Асинхронность репликации
В MySQL репликация работает в асинхронном режиме. Это значит, что приложение не знает, как быстро данные появятся на Slave.
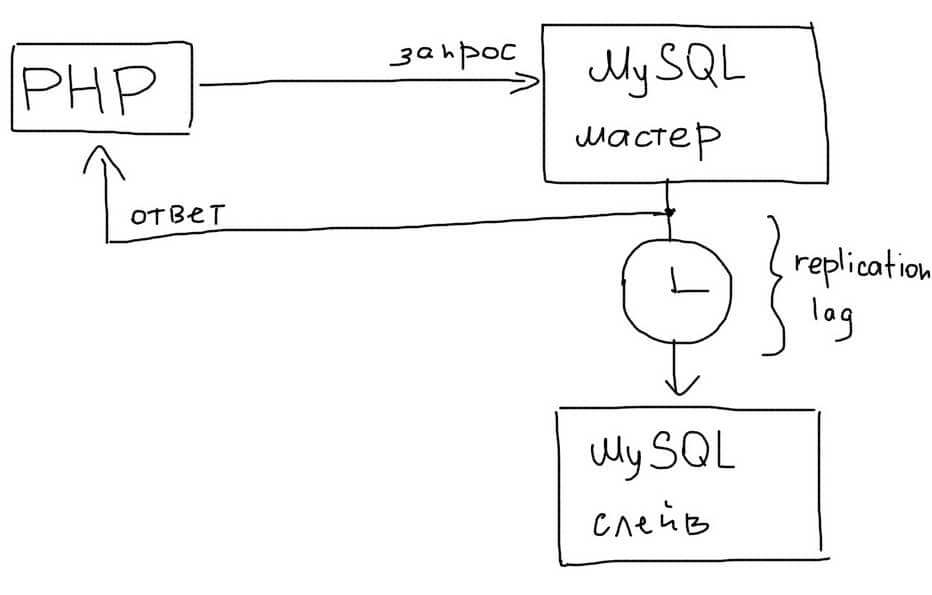
Задержка в репликации (replication lag) может быть как очень маленькой, так и очень большой. Обычно рост задержки говорит о том, что сервера не справляются с текущей нагрузкой и их необходимо масштабировать дальше, например техниками горизонтального и вертикального шардинга.
Синхронный режим
Синхронный режим репликации позволит гарантировать копирование данных на Slave.
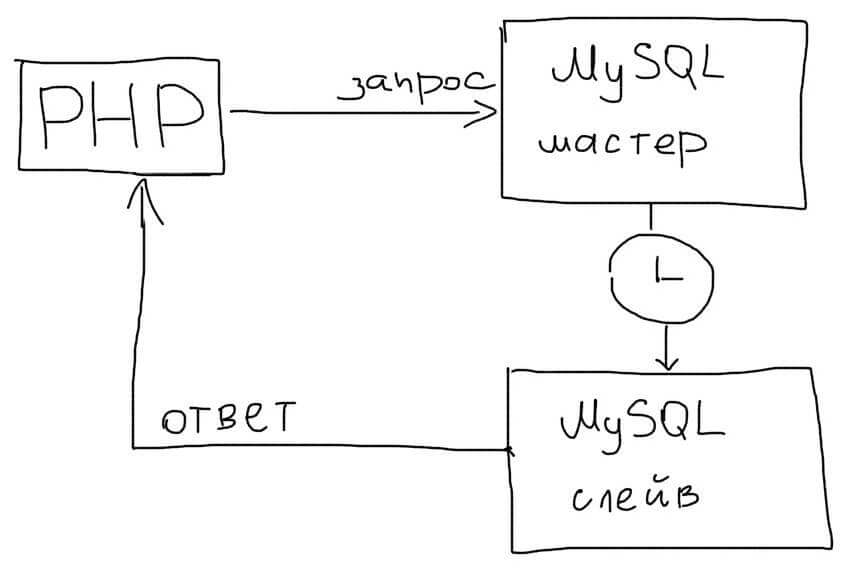
Это упростит работу в приложении, т.к. все операции чтения можно будет всегда отправлять на Slave. Однако это может значительно уменьшить скорость работы MySQL. Синхронный режим не следует использовать в Web приложениях.
“Ручная” репликация
Следует помнить, что репликация — это не технология, а методика. Встроенные механизмы репликации могут принести ненужные усложнения либо не иметь какой-то нужной функции. Некоторые технологии вообще не имеют встроенной репликации.
В таких случаях, следует использовать самостоятельную реализацию репликации. В самом простом случае, приложение будет дублировать все запросы сразу на несколько серверов базы данных:
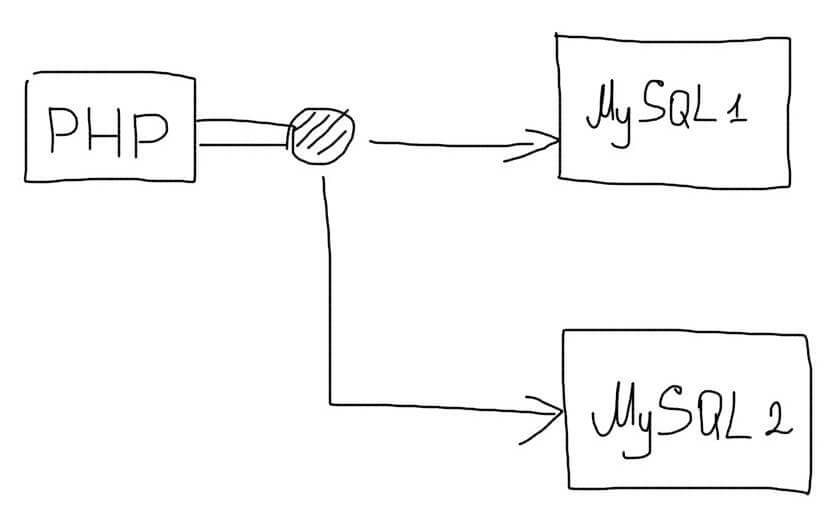
При записи данных, все запросы будут отправляться на несколько серверов. Зато операции чтения можно будет отправлять на любой сервер. Нагрузка при этом будет распределяться по всем доступным серверам:
(Все операции изменения данных происходят на нескольких серверах, а чтения — на одном случайном)
Это позволит использовать преимущества репликации даже если сама технология ее не поддерживает.
Выход из строя
При поломке одного из серверов в такой схеме необходимо сделать следующее:
Самое важное
Репликация используется в большей мере для резервирования баз данных и в меньшей для масштабирования. Master-Slave репликация удобна для распределения запросов чтения по нескольким серверам. Подход ручной репликации позволит использовать преимущества репликации для технологий, которые ее не поддерживают. Зачастую репликация используется вместе с шардингом при решении вопросов масштабирования.
Мастер и слейв что это
В данном материале разбирается типизация DNS серверов по их назначению, рассматриваются основной функционал серверов каждого типа и его значение для надежной и эффективной работы системы доменных имен.
В данном материале разбирается типизация DNS серверов по их назначению, рассматриваются основной функционал серверов каждого типа и его значение для надежной и эффективной работы системы доменных имен. Прежде чем приступить к чтению данного материала, необходимо ознакомиться с материалом «Как работает система доменных имен».
Сразу оговоримся, что в данном материале речь не идет о серверах, как о программах, которые реализуют функцию сервера доменных имен, например named или сервер доменных имен Windows Server 2000. Мы будем рассматривать серверы, как процессы, которые должны выполнять определенные функции по обслуживанию DNS запросов.
В документах RFC-1034 и RFC-1035 выделяют несколько типов DNS-серверов. В соответствии с типами откликов на запрос к системе доменных имен серверы можно разделить на авторитативные (authoritative) и неавторитативные (non authoritative).
Авторитативный отклик (authoritative response) возвращают серверы, которые являются ответственными за зону, в которой описана информация, необходимая resolver-у (клиент DNS).
Неавторитативный отклик (non authoritative response) возвращают серверы, которые не отвечают за зону, содержащую необходимую resolver информацию.
Это значит, что если наш сервер доменных имен поддерживает домен kuku.ru, и наш resolver настроен таким образом, что посылает рекурсивные запросы к системе доменных имен через наш сервер доменных имен, и при этом мы хотим получить доступ к сайту www.kuku.ru, то мы получим от нашего сервера доменных имен авторитативный отклик, т.к. именно наш сервер отвечает на все запросы к зоне kuku.ru.
Если же мы захотим получить информацию о домене lenta.ru, то в этом случае мы получим неавторитативный отклик с нашего сервера, т.к. он не отвечает за зону lenta.ru и, соответсвенно, либо будет проводить нерекурсивный опрос серверов доменных имен, либо выдаст нам соответствие из своего кэша, т.к. существует большая вероятность того, что кто-то из наших коллег уже обращался с таким запросом к нему.
Авторитативный отклик могут, в свою очередь, вернуть либо master-сервер зоны (primary server), либо slave-сервер (secondary server) зоны. В русскоязычной литературе их называют основным и дублирующим серверами (или первичным и вторичным, соответственно).
Master-сервер (primary, первичный) доменных имен является ответственным (authoritative) за информацию о зоне в том смысле, что читает описание зоны с локального диска компьютера, на котором он функционирует и отвечает в соответствии с этим описанием на запросы resolver-ов. Описание зоны master-сервера является первичным, т.к. его создает вручную администратор зоны. Соответственно, вносить изменения в описание зоны может только администратор данного сервера. Все остальные серверы только копируют информацию с master-сервера. Вообще говоря, такое определение несколько устарело, и позже будет ясно почему. Но при настройках реальных серверов мы будем использовать именно это определение.
Для зоны можно определить только один master-сервер, т.к. первоисточник может и должен быть только один.
Slave-сервер (secondary, вторичный, дублирующий) также является ответственным (authoritative) за зону. Его основное назначение заключается в том, чтобы подстраховать работу основного сервера доменных имен (master server), ответственного за зону, на случай его выхода из строя, а также для того, чтобы разгрузить основной сервер, приняв часть запросов на себя. Так, например, из 13 серверов, которые обслуживают корневую зону, 12 являются slave-серверами.
Администратор slave-сервера не прописывает данные описания зоны. Он только обеспечивает настройку своего сервера таким образом, чтобы его сервер копировал описание зоны с master-сервера, поддерживая его (описание зоны) в актуальном согласованном с master-сервером состоянии.
Обычно, время согласования описания зоны между slave-сервером и master-сервером задается администратором master-сервера в описании зоны. Slave-сервер в момент своего запуска копирует это описание и затем руководствуется им при обновлении информации о зоне. Slave-сервера периодически через заданный интервал времени опрашивают master-сервер на предмет изменения описания зоны. Если изменения имеют место быть, то описание зоны копируется на slave-сервер.
Существует оговоренная практика резервирования серверов, которая описана в рекомендациях по ведению зон. Она заключается в том, что для домена второго уровня необходимо иметь как минимум два сервера, ответственных за зону, т.е. дающих авторитативные отклики на запросы. Один master-сервер и один slave-сервер. При этом эти серверы должны иметь независимые подключения к Интернет, чтобы обеспечить бесперебойное обслуживание запросов к зоне в случае потери связи с одним из сегментов сети, в котором находится один из серверов.

Рис.1. Схема подключения master и slave серверов зоны
Из рисунка 1 видно, что корпоративная локальная сеть и сеть регистратора имеют независимые подключения к Интернет, через разных канальных провайдеров. В частности резервирование серверов в ru-center (www.nic.ru) обеспечивает такую схему подключения, т.е. master-сервер может быть размещен на площадке корпоративной локальной сети, а slave на площадке ru-center.
Размещение обоих серверов на площадке регистратора, например, ru-center, также обеспечивает независимое подключение серверов, т.к. обычно регистратор имеет несколько точек подключения к Интернет.
Как уже было сказано, slave-сервер копирует описание зоны c master-сервера. В настоящее время существует два механизма копирования зоны: полное копирование (AXFR) и инкрементальное (incremental) копирование зоны (IXFR).
В современных RFC, которые расширяют толкование механизмов взаимодействия между участниками обмена данными в рамках DNS, типизацию серверов и их разделение на master-серверы и slave-серверы дают относительно процедур копирования зоны.
Так slave-сервером называют сервер, который использует механизм передачи зоны для получения копии зоны, а master-сервером называют сервер, с которого осуществляется копирование зоны. При этом зону можно скопировать с любого сервера, который является авторитативным. Т.е. зону можно скопировать и со slave-сервера, который относительно самой процедуры копирования зоны будет считаться master-сервером. Для того чтобы выделить сервер, который не копирует зоны ни с какого другого сервера, вводят понятие Primary Master. Этот сервер для зоны только один, и он находится в корне процедуры копирования описания зоны.
Типизация серверов относительно процедуры обмена описаниями зон связана с возможностями, которые не описаны в RFC-1034 и RFC-1035, и, соответственно, не поддерживались в ранних версиях программ-серверов доменных имен. Это механизм объявлений об изменениях в описании зоны (RFC-1996), динамическое обновление описания зоны (RFC-2136) и инкрементальное обновление описания зоны (RFC-1995).
Для большинства администраторов корпоративных доменов все эти новшества, возможно, любопытны, но в реальной жизни не слишком полезны, т.к. вся их мощь проявляется только при работе с динамичными описаниями зон, информация в которых подвержена постоянным изменениям. Тем не менее, не сказать о них нельзя, т.к. при работе современными версиями программ-серверов обязательно возникнут вопросы типа «а чтобы это значило».
Сначала о том, что такое уведомления об изменениях описания зоны (DNS NOTIFY). Идея достаточно проста и проистекает из проблемы распространения изменений, внесенных в описание зоны при ее редактировании. Дело в том, что slave-серверы при традиционной работе опрашивают master-сервер (в данном контексте primary master) на предмет изменения в описании зоны через определенные промежутки времени, которые задаются в описании зоны. Возможна ситуация, когда изменения были внесены в зону сразу после ее копирования slave-сервером. В этом случае новая информация появится на всех slave-серверах только при следующем обновлении зоны.
Ситуация усугубляется еще и тем, что остальные не авторитативные серверы держат записи соответствия между именем домена и IP_адресом в своем кэше в течение времени TTL (Time To Live), которое также определяется в описании зоны. Обычно задержка между внесением изменений и стабильной работой с новым описанием зоны в российском сегменте Интернет составляет примерно 2 часа. Вот пример отчета программы nslookup для rambler.ru:
>set type=soa
>rambler.ru
Server: ns.rambler.ru
Address: 217.73.192.49
rambler.ru
origin = ns.rambler.ru
mail addr = bindmaster.rambler-co.ru
serial = 2002090601
refresh = 10800 (3H)
retry = 1800 (30M)
expire = 10800 (3H)
minimum ttl = 3600 (1H)
rambler.ru nameserver = ns.rambler.ru
rambler.ru nameserver = ns.park.rambler.ru
ns.rambler.ru internet address = 217.73.192.49
ns.park.rambler.ru internet address = 217.73.193.23
>
> relarn.ru
Server: ns.relarn.ru
Address: 194.226.65.3
relarn.ru
origin = ns.relarn.ru
mail addr = noc-dns.relarn.ru
serial = 650127367
refresh = 86400 (1D)
retry = 3600 (1H)
expire = 604800 (1W)
minimum ttl = 86400 (1D)
relarn.ru nameserver = ns.relarn.ru
relarn.ru nameserver = ns.ussr.EU.net
relarn.ru nameserver = ns.spb.su
relarn.ru nameserver = ns2.ripn.net
ns.relarn.ru internet address = 194.226.65.3
ns.ussr.EU.net internet address = 193.124.22.65
ns.spb.su internet address = 193.124.83.69
ns2.ripn.net internet address = 194.226.96.30
>
О том, что обозначают другие позиции этих отчетов, мы поговорим тогда, когда будем обсуждать описание зоны (запись SOA), а пока только заметим, что внесение изменений в описание зоны не приводит к появлению возможности мгновенного их использования.
Таким образом, механизм уведомления об изменениях в описании зоны необходим для ускорения введения в жизнь сделанных изменений.
Принцип работы DNS NOTIFY следующий:
На рисунке пояснется работы приведенной выше схемы:

Рис.2. Схема работы DNS NOTIFY
На рисунке 2 primary master является для обоих slave-серверов master-сервером c точки зрения процедуры передачи зоны. Но в принципе, для одного из серверов он может быть и не определен в качестве master-сервера. В этом случае появляется дополнительное звено в дереве зависимости обмена данными зоны. В этом случае изменения будут передаваться от сервера к серверу так, как это показано на рисунке 3:

Рис.3. Схема работы DNS NOTIFY при двухзвенном оповещении об изменении описания зоны.
Теперь поясним механизм динамического обновления описания зоны (Dynamic Updates или DNS UPDATE). Изначально описание зоны было, да и до сих пор в большинстве случаев остается, статическим. Это значит, что есть на Primary master файл описания зоны, в который администратор вручную или при помощи скриптов изменения содержания файла вносит изменения. Для того чтобы они стали актуальными, т.е. их увидели resolver-ы, необходима перезагрузка сервера. Идея динамического обновления описания зоны состоит в том, чтобы, во-первых, вносить изменения в описание зоны без перезагрузки сервера, а, во-вторых, делать это удаленно, т.е. администратору не нужно получать доступ к файлам описания зон ни для ручного редактирования, ни для скриптов. Тем самым класс клиентов в модели «клиент-сервер» в рамках DNS обмена расширяется на группу клиентов администрирования.
Когда актуально динамическое обновление зоны? Чаще всего необходимость динамического обновления связывают с работой по протоколу DHCP (Dynamic Host Configuration Protocol, RFC-1541). DHCP Позволяет динамически назначать компьютерам IP-адреса, маски, IP-адреса шлюзов, доменные имена и т.п., т.е. передавать хостам данные без которых невозможна работа в сетях TCP/IP.
DHCP существенно облегчает работу сетевого администратора, которому не нужно настраивать каждый компьютер, подключенный к сети, вручную. Динамическое именование влечет за собой постоянное изменение информации в описании зоны.
Динамическое обновление позволяет авторизованным клиентам посылать запросы на динамическое обновление описания зоны серверам, которые являются авторитативными для соответствующей зоны. Обратите внимание, что запросы могут направляться как master-серверам, т.к. slave-серверам.
Если сервер не является Primary master-сервером зоны, то он отправляет (ретранслирует) запрос на обновление своему master-серверу. Таким образом запрос на обнавление достигает Primary master-сервера зоны.
Как только Primary master-сервер совершит обновление описания зоны, он может по механизму DNS NOTIFY оповестить об этом slave-серверы, которые, в свою очередь, обновят свои описания зоны.
В рамках динамического обновления можно удалять и добавлять отдельные записи описания ресурсов в описания зоны, наборы записей описания ресурсов, выделенных по определенному признаку, скажем записи определенного типа, или записи связанные с определенным доменом. Возможно редактирование описания зоны по условию.
Для того, чтобы успешно выполнялись обмены со slave-серверами, при каждом изменении зоны изменяется и номер ее версии. Это позволяет slave-серверам поддерживать свои описания зоны в актуальном, согласованном с Primary master-сервером состоянии.
При этом стоит отметить, что собственно сами изменения описания зоны не столь и велики, т.к., например, при DHCP при каждом изменении добавляется/удаляется одна-две записи описания ресурсов. Каждое такое изменение будет порождать обмен описанием зоны.
При традиционном обмене описанием зоны (AXFR) Между master-сервером и slave-сервером передается полное описание зоны.
Мы более подробно остановимся на этом вопросе в разделе, посвященном настройкам BIND и файлам описания зон.
В контексте рассмотрения обмена описаниями зоны между master-серверами и slave-серверами следует упомянуть о «невидимых» серверах (stealth, см. RFC-1996). Суть такого сервера в том, что он не упоминается в описании зоны. Таким образом, его никто не видит, т.к. в рамках DNS-обмена данными информацию о нем получить нельзя ни путем простых запросов, ни путем копирования описания зоны.
Тем не менее, существуют еще файлы статической настройки (конфигурации) серверов доменных имен, где такой сервер может быть прописан. Его можно прописать в качестве master-сервера для slave или сконфигурировать таким образом, что он будет работать в качестве slave для конкретной зоны.
Для чего нужен такой невидимый сервер. Например, для того, чтобы вносить обновления в зону, находясь под защитой firewall. В этом случае Primary master можно сделать невидимым, а все остальные, в том числе и заявленные при регистрации домена, slave-серверами зоны. Это позволяет нейтрализовать атаки на зону, т.к. обновление всегда будет производиться с «невидимого» Primary master:

Рис.4. Схема организации DNS-серверов с невидимым primary master сервером
Серверы данного вида используют для организации централизованного кеширования соответствий доменных имен и IP-адресов. Идея организации кэширующего сервера состоит в том, чтобы на искать соответствие доменного имени и IP-адреса в сети, а накапливать их в своем локальном кэше и обслуживать от туда запросы relover-ов.
Кэш-сервер не поддерживает описаний зон и, соответственно, не посылает resolver-ам авторитативных откликов:
> www.w3.org
Server: [144.206.192.60]
Address: 144.206.192.60
Non-authoritative answer:
Name: www.w3.org
Addresses: 18.29.1.35, 18.7.14.127, 18.29.1.34
Выше приведен типичный отклик кэширующего сервера на запрос nslookup об адресе www.w3.org. Если бы сервер был авторитативным, то строчки «Non-authoritative answer» в отклике мы бы не увидели.
Список этих серверов можно получить достаточно просто. Ниже приведен отчет программы nslookup:
Non-authoritative answer:
(root)
origin = A.ROOT-SERVERS.NET
mail addr = NSTLD.VERISIGN-GRS.COM
serial = 2002091100
refresh = 1800 (30M)
retry = 900 (15M)
expire = 604800 (1W)
minimum ttl = 86400 (1D)
Authoritative answers can be found from:
(root) nameserver = A.ROOT-SERVERS.NET
(root) nameserver = B.ROOT-SERVERS.NET
(root) nameserver = C.ROOT-SERVERS.NET
(root) nameserver = D.ROOT-SERVERS.NET
(root) nameserver = E.ROOT-SERVERS.NET
(root) nameserver = F.ROOT-SERVERS.NET
(root) nameserver = G.ROOT-SERVERS.NET
(root) nameserver = H.ROOT-SERVERS.NET
(root) nameserver = I.ROOT-SERVERS.NET
(root) nameserver = J.ROOT-SERVERS.NET
(root) nameserver = K.ROOT-SERVERS.NET
(root) nameserver = L.ROOT-SERVERS.NET
(root) nameserver = M.ROOT-SERVERS.NET
A.ROOT-SERVERS.NET internet address = 198.41.0.4
B.ROOT-SERVERS.NET internet address = 128.9.0.107
C.ROOT-SERVERS.NET internet address = 192.33.4.12
D.ROOT-SERVERS.NET internet address = 128.8.10.90
E.ROOT-SERVERS.NET internet address = 192.203.230.10
F.ROOT-SERVERS.NET internet address = 192.5.5.241
G.ROOT-SERVERS.NET internet address = 192.112.36.4
H.ROOT-SERVERS.NET internet address = 128.63.2.53
I.ROOT-SERVERS.NET internet address = 192.36.148.17
J.ROOT-SERVERS.NET internet address = 198.41.0.10
K.ROOT-SERVERS.NET internet address = 193.0.14.129
L.ROOT-SERVERS.NET internet address = 198.32.64.12
M.ROOT-SERVERS.NET internet address = 202.12.27.33
>
Согласно этому отчету Primary master сервером для корневой зоны является сервер A.ROOT-SERVERS.NET. Именно он отвечает за все изменения в описании зоны. Остальные серверы относительно корневой зоны являются slave-серверами. Slave-серверы обновляют свои описания зоны каждые 30 минут. Если в течении недели Primary master будет неработоспособен, то по идее вся система доменных имен потеряет связность. В RFC-2870, где описаны требования к работе root серверов, содержатся общие слова о том, как не допустить такого развития событий, но там нет конкретного плана действий.
Средние цифры таковы:
Исходящий трафик: 600 Kbps
Входящий трафик: 2.2 Kbps
Число пакетов за сутки: 26M
Распределение запросов по типам:
Поиск IP-адреса(A) 77%
Поиск сервера доменных имен (NS) 15%
Поиск почтового шлюза(MX) 5%
Статистика обслуживания запросов, которая названа ужасающей(Scary statistics):
— Только 26% правильных(valid) запросов к корневой зоне.
— 66% запросов к несуществующим доменам верхнего уровня (non existent TLDs)
По поводу последней цифры автор BIND Paul Vixie предположил, что это обращения к группам Windows NT, и при отсутствие негативного кэширования в Windows эти запросы повторяются до 10 раз за секунду.
Приведенные цифры должны дать представление о степени нагрузки на root серверы и цену тиражировании программного обеспечения, содержащего неточности приреализации протоколов.
К слову сказать, в 2002 году на встрече IEGP также обсуждались проблемы DNS, а точнее масштаб ошибок при делегировании и описании зон.