Spatial Transformer Networks в MATLAB
В данной статье будут подниматься темы построения пользовательских слоёв нейронных сетей, использование автоматического дифференцирования и работы со стандартными слоями глубокого обучения нейронных сетей в MATLAB на основе классификатора с использованием пространственной трансформационной сети.
Spatial Transformer Network (STN) — один из примеров дифференцируемых LEGO-модулей, на основе которых можно строить и улучшать свою нейросеть. STN, применяя обучаемое аффинное преобразование с последующей интерполяцией, лишает изображения пространственной инвариантности. Грубо говоря, задача STN состоит в том, чтобы так повернуть или уменьшить/увеличить исходное изображение, чтобы основная сеть-классификатор смогла проще определить нужный объект. Блок STN может быть помещен в сверточную нейронную сеть (CNN), работая в ней по большей части самостоятельно, обучаясь на градиентах, приходящих от основной сети (более детально с данной темой можно ознакомиться по ссылкам: Хабр и Мануал).
В нашем случае задачей является классифицировать 99 классов лобовых стёкол автомобилей, но, для начала, начнём с чего-нибудь попроще. Для того, чтобы ознакомиться с данной тематикой, возьмём базу данных MNIST из рукописных цифр и построим сеть из нейронных слоёв глубокого обучения MATLAB и пользовательского слоя аффинной трансформации изображения (ознакомиться со списком всех имеющихся слоёв и их функционалом можно по ссылке).
Для того, чтобы реализовать возможности dlarray, нам необходимо вручную прописать аффинную трансформацию изображения так как функции MATLAB, реализующие данную возможность, не поддерживают структуры dlarray. Далее представлена написанная нами функция трансформации, весь проект доступен по ссылке.


Также важно уточнить, какие конкретно изменения накладываются на изображения разными числами матрицы преобразования. Первая строка накладывает трансформации по оси Y, а вторая по Х. Параметры выполняют изменение размера (приближение, отдаление), поворот и смещение изображения. Более детально матрица трансформации описана в таблице.
Теперь, когда мы разобрались с теоретической составляющей, перейдём к реализации сети с использованием STN. На рисунках ниже представлены структура построенной сети и результаты обучения для базы данных MNIST.
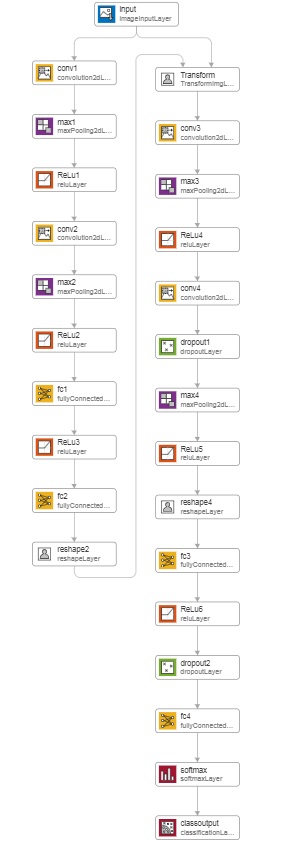 Структура сети.
Структура сети. 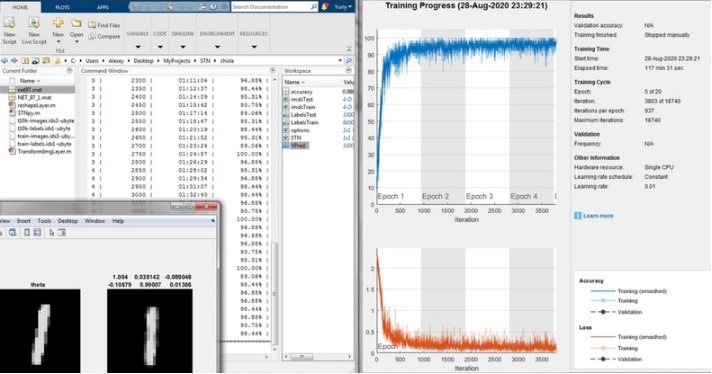 Результаты обучения.
Результаты обучения.
Опираясь на результаты обучения, а именно на то, как сеть трансформирует изображение и на то, какой процент угадывания она демонстрирует, можно сделать вывод, что данный вариант сети полностью функционален.
Теперь, когда мы получили достойный результат на базе данных MNIST, можно переходить к имеющимся у нас лобовым стёклам.
Первое различие между входными данными — это то, что числа — это изображения в градиенте серого, а стёкла — изображения формата RGB, следовательно, нам необходимо изменить слой трансформации, добавив цикл. Будем применять отдельно трансформацию к каждому из слоёв изображения. Также для упрощения обучения добавим в слой трансформации веса, на которые будем домножать матрицу трансформации, и установим эти веса в 2, за исключением весов смещения изображения, их установим в 0, для того чтобы сеть училась, в первую очередь, поворачивать и изменять масштаб изображения. Также, если взять данные веса меньше, то сеть дольше будет перестраивать веса STN в поисках полезной информации, так как полезная информация у нас находится по краям изображения, а не в центре, в отличие от сети с числами. Далее нам необходимо заменить часть классификатора, так как он является слишком слабым для наших входных данных. Чтобы не изменять структуру самого STN, мы приведём изображение к виду, похожему на числа, добавив слой нормализации и dropout для уменьшения объёма входных данных в STN.
Сравнивая данные на входе у сети с числами и стёклами, можно увидеть, что на стёклах диапазон значений варьируется от [0;255], а в числах от [0;1], а также в числах большая часть матрицы — это нули. Примеры данных на входе показаны ниже.
Данные на входе у сети с числами.  Данные на входе у сети со стёклами.
Данные на входе у сети со стёклами.
Опираясь на вышеприведённые данные, нормализация будет выполняться по принципу деления входных данных на 255 и обнуления всех значений меньше 0.3 и больше 0.75, а также от трёхмерного изображения мы оставим только одно измерение. На изображении ниже видно, что подаётся на входе и что остаётся после слоя нормализации.
 Вход и выход слоя нормализации.
Вход и выход слоя нормализации.
Также в связи с тем, что у нас не так много данных для тестирования и обучения сети, мы искусственно увеличим их объём за счёт аффинной трансформации, а именно поворота изображения на случайный градус в пределах [-10;10] и прибавления случайного числа к матрице изображения для изменения цветовой палитры в пределах [-50; 50]. В функции чтения мы воспользуемся стандартными функциями MATLAB, так как в ней нам не требуется оперировать dlarray структурами. Ниже представлена используемая функция чтения входных изображений.
Ниже представлены структура сети с внесёнными изменениями и результаты обучения этой сети.
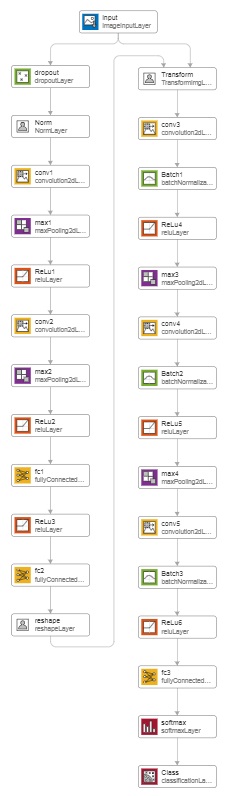 Структура сети.
Структура сети.  Результаты обучения.
Результаты обучения.
Как мы видим, сеть выделила полезные признаки, а именно центральную часть изображения, за счёт этого, уже к концу первой эпохи достигла процента угадывания выше 90. Так как по краям изображения одинаковые, сеть обучилась на классификацию отличных признаков, и за счёт этого она увеличивает центральную часть, вынося левые и правые грани за границу изображения подаваемого на классификатор. При этом сеть поворачивает все изображения так, чтобы они не отличались по углу наклона, за счёт чего классификатору не требуется настраивать веса под разные углы наклона изображения, тем самым увеличивается точность классификации.
Для сравнения, возьмём и протестируем сеть без использования STN, оставив только имеющийся у нас классификатор. Ниже представлены результаты обучения этой сети.
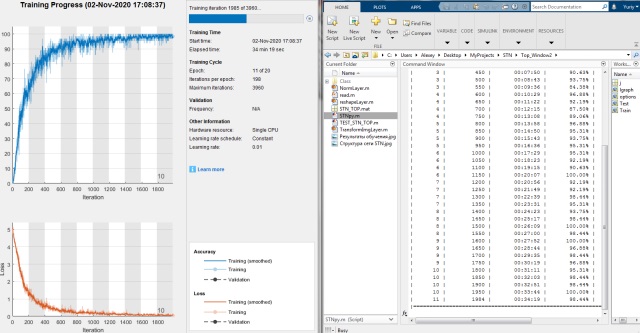 Результаты обучения.
Результаты обучения.
Как мы видим, сеть действительно обучается медленнее и за то же количество итераций достигает меньшей точности.
Подводя итоги, можно сделать вывод, что технология STN актуальна в современных нейронных сетях и позволяет увеличить скорость обучения и точность классификации сети.
Документация
Глубокое обучение в MATLAB
Что такое глубокое обучение?
Deep learning является ответвлением машинного обучения, которое учит компьютеры делать то, что прибывает естественно к людям: учитесь на опыте. Алгоритмы машинного обучения используют вычислительные методы, чтобы “узнать” об информации непосредственно из данных, не полагаясь на предопределенное уравнение как на модель. Глубокое обучение особенно подходит для распознавания изображений, которое важно для решения проблем, таких как распознавание лиц, обнаружение движения и много усовершенствованных технологий помощи драйвера, таких как автономное управление, обнаружение маршрута, пешеходное обнаружение и автономная парковка.
Deep Learning Toolbox™ обеспечивает простые команды MATLAB ® для создания и соединения слоев глубокой нейронной сети. Примеры и предварительно обученные сети дают возможность использовать MATLAB для глубокого обучения, даже без ведома усовершенствованных алгоритмов компьютерного зрения или нейронных сетей.
Для свободного практического введения в практические методы глубокого обучения смотрите Глубокое обучение Onramp.
| Что вы хотите сделать? | Узнать больше |
|---|---|
| Используйте обучение с переносом, чтобы подстроить сеть с вашими данными | |
| Классифицируйте изображения с предварительно обученными сетями | Предварительно обученные глубокие нейронные сети |
| Создайте новую глубокую нейронную сеть для классификации или регрессии | |
| Измените размер, вращайте или предварительно обработайте изображения для обучения или прогноза | Предварительно обработайте изображения для глубокого обучения |
| Маркируйте свои данные изображения автоматически на основе имен папок или в интерактивном режиме использования приложения | |
| Создайте нейронные сети для глубокого обучения для последовательности и данных временных рядов. | |
| Классифицируйте каждый пиксель изображения (например, дорога, автомобиль, пешеход) | Семантические основы сегментации (Computer Vision Toolbox) |
| Обнаружьте и распознайте объекты в изображениях | Глубокое обучение, семантическая сегментация и обнаружение (Computer Vision Toolbox) |
| Классифицируйте текстовые данные | Классифицируйте текстовые данные Используя глубокое обучение |
| Классифицируйте аудиоданные для распознавания речи | Распознание речевых команд с использованием глубокого обучения |
| Визуализируйте то, что показывает сети, учились | |
| Обучайтесь на центральном процессоре, графическом процессоре, нескольких графических процессорах, параллельно на вашем рабочем столе или на кластерах в облаке, и работайте с наборами данных, слишком большими, чтобы уместиться в памяти | Глубокое обучение для Больших данных на графических процессорах и параллельно |
Чтобы узнать больше об областях применения глубокого обучения, включая автоматизированное управление, смотрите Применение глубокого обучения.
Чтобы выбрать, использовать ли предварительно обученную сеть или создать новую глубокую сеть, рассмотрите сценарии в этой таблице.
| Используйте предварительно обученную сеть для изучения передачи | Создайте новую глубокую сеть | |
|---|---|---|
| Данные тренировки | Сотни к тысячам маркированных (маленьких) изображений | Тысячи к миллионам маркированных изображений |
| Вычисление | Умеренное вычисление (дополнительный графический процессор) | Вычислите интенсивный (требует графического процессора для скорости), |
| Учебное время | Секунды к минутам | Дни к неделям для настоящих проблем |
| Точность модели | Хороший, зависит от предварительно обученной модели | Высоко, но может сверхсоответствовать к небольшим наборам данных |
Для получения дополнительной информации смотрите, Выбирают Network Architecture.
Глубокое обучение использует нейронные сети, чтобы изучить полезные представления функций непосредственно от данных. Нейронные сети комбинируют несколько нелинейных слоев обработки, с помощью простых элементов, действующих параллельно и вдохновленный биологическими нервными системами. Модели глубокого обучения могут достигнуть современной точности в предметной классификации, иногда чрезмерной производительности человеческого уровня.
Вы обучаете модели с помощью большого набора маркированной сети передачи данных и архитектуры нейронной сети, которая содержит много слоев, обычно включая некоторые сверточные слои. Обучение эти модели в вычислительном отношении интенсивны и можно обычно ускорять обучение при помощи высокоэффективного графического процессора. Эта схема показывает, как сверточные нейронные сети комбинируют слои, которые автоматически узнают о функциях из многих изображений, чтобы классифицировать новые изображения.

Автоматически считайте пакеты изображений для более быстрой обработки в приложениях компьютерного зрения и машинном обучении
Импортируйте данные из наборов изображений, которые являются слишком большими, чтобы уместиться в памяти
Маркируйте свои данные изображения автоматически на основе имен папок
Попробуйте Глубокое Обучение в 10 строках КОДА MATLAB
Этот пример показывает, как использовать глубокое обучение, чтобы идентифицировать объекты на веб-камере реального времени с помощью только 10 строк кода MATLAB. Попробуйте пример, чтобы видеть, как простой это должно начать с глубоким обучением в MATLAB.
Запустите эти команды, чтобы получить загрузки в случае необходимости, соединиться с веб-камерой и получить предварительно обученную нейронную сеть.
В этом примере сеть правильно классифицирует кофейную кружку. Экспериментируйте с объектами в своей среде, насколько точный сеть.

Чтобы посмотреть ролик этого примера, смотрите Глубокое обучение в 11 Строках кода MATLAB.
Чтобы изучить, как расширить этот пример и показать множество вероятности классов, смотрите, Классифицируют Изображения Веб-камеры Используя Глубокое обучение.
Для следующих шагов в глубоком обучении можно использовать предварительно обученную сеть для других задач. Решите новые проблемы классификации на своих данных изображения с изучением передачи или выделением признаков. Для примеров смотрите, Запускают Глубокое обучение Быстрее Используя Классификаторы Изучения и Train Передачи, использующие Функции, Извлеченные от Предварительно обученных сетей. Чтобы попробовать другие предварительно обученные сети, смотрите Предварительно обученные Глубокие нейронные сети.
Запустите глубокое обучение быстрее Используя изучение передачи
Изучение передачи обычно используется в применении глубокого обучения. Можно взять предварительно обученную сеть и использовать ее в качестве отправной точки, чтобы изучить новую задачу. Подстройка сети с передачей, учащейся, намного быстрее и легче, чем обучение с нуля. Можно быстро заставить сеть изучить новую задачу с помощью меньшего числа учебных изображений. Преимущество передачи, учащейся, состоит в том, что предварительно обученная сеть уже изучила богатый набор функций, которые могут быть применены к широкому спектру других подобных задач.
Например, если вы берете сеть, обученную на тысячах или миллионах изображений, можно переобучить ее для нового обнаружения объектов только с помощью сотен изображений. Можно эффективно подстроить предварительно обученную сеть с намного меньшими наборами данных, чем исходные данные тренировки. Если вы имеете очень большой набор данных, то передаете изучение, не может быть быстрее, чем обучение новой сети.
Изучение передачи позволяет:
Передайте изученные функции предварительно обученной сети к новой проблеме
Передайте изучение, быстрее и легче, чем обучение новой сети
Уменьшайте учебное время и размер набора данных
Выполните глубокое обучение, не будучи должен изучить, как создать совершенно новую сеть
![]()
Обучите классификаторы, использующие функции, извлеченные от предварительно обученных сетей
Глубокое обучение для Больших данных на центральных процессорах, графических процессорах, параллельно, и на облаке
Нейронные сети являются по сути параллельными алгоритмами. Можно использовать в своих интересах этот параллелизм при помощи Parallel Computing Toolbox™, чтобы распределить обучение на многожильных центральных процессорах, графические блоки обработки (графические процессоры) и кластеры компьютеров с несколькими центральными процессорами и графических процессоров.
Обучение глубоких сетей чрезвычайно в вычислительном отношении интенсивно, и можно обычно ускорять обучение при помощи высокоэффективного графического процессора. Если у вас нет подходящего графического процессора, можно обучаться на одном или нескольких ядрах процессора вместо этого. Можно обучить сверточную нейронную сеть на одном графическом процессоре или центральном процессоре, или на нескольких графических процессорах или ядрах процессора, или параллельно на кластере. Используя графический процессор или параллельные опции требует Parallel Computing Toolbox.
Чтобы узнать больше об оборудовании глубокого обучения и настройках памяти, смотрите Глубокое обучение для Больших данных на графических процессорах и параллельно.
Создание и обучение нейронных сетей в системе Matlab

Рубрика: Информационные технологии
Дата публикации: 03.04.2014 2014-04-03
Статья просмотрена: 19055 раз
Библиографическое описание:
Афанасьева, М. А. Создание и обучение нейронных сетей в системе Matlab / М. А. Афанасьева. — Текст : непосредственный // Молодой ученый. — 2014. — № 4 (63). — С. 85-88. — URL: https://moluch.ru/archive/63/10102/ (дата обращения: 01.11.2021).
В данной статье решается задача разработки шаблона, который позволяет познакомиться с процессом создания и обучения, а также прогнозирования результатов нейронных сетей в системе Matlab. Конечный результат работы призван помогать студентам технических специальностей и осваивать начальный этап работы с нейросетями. Для реализации задачи используется система MatlabR2013b.
Ключевые слова:нейронная сеть, прогнозирование.
Технологии искусственных нейронных сетей являются одним из важнейших направлений современной науки. Они находят широкое применение в различных областях науки и производства. Изучению такого направлению искусственного интеллекта в курсе подготовки студентов по информатике и вычислительной технике уделяется большое внимание.
В курсе «Технологии искусственного интеллекта в управлении» Приамурского государственного университета имени Шолом-Алейхема студенты обучаются использованию рассматриваемой технологии в разнообразных средах. Поэтому была поставлена задача разработать простой шаблон, по которому можно познакомится с достоинствами и недостатками искусственных нейронных сетей и использовать его в дальнейших научных и практических работах.
Одной из существующих систем, позволяющей в достаточно простой форме реализовать нейронные сети, является Matlab, по которой имеются множество научных разработок.
Так, В. Д. Семейкин и А.В Скупченко [1] занимаются изучением и созданием нейросетевых моделей для решения телекоммуникационных задач. В. О. Андреев, Н. В. Савиных рассмотрели подход интеллектуализации технологических процессов и процессов управления на основе мягких вычислений, ядро которых составляют нечеткая логика, искусственные нейронные сети и генетические алгоритмы [2]. В своей работе М. Ю. Буриченко, О. Б. Иванцев, О. В. Букреева представили возможности использования программного пакета Matlab для построения моделей прогнозирования с помощью искусственных нейронных сетей, привели результаты построения пяти искусственных нейронных сетей, провели анализ результатов и возможности пересмотра и корректировки весов построенной искусственной нейронной сети [4]. Д. Балабио и М. Васигни в своей статье [6] описали комплект инструментов системы Matlab для создания карт Кохонена, приведя практический пример. А. Нейямадпур писал о возможности представления формата 2D в формат 3D с помощью нейронных сетей в системе Matlab [7]. Теоретические аспекты программирования нейронных сетей изложены в различных пособиях [3, 5, 7, 8].
После изучения теоретических сведений была создана лабораторная работа, в которой показывается пример построения нейронной сети, на основе данных по количеству студентов Приамурского Государственного Университета имени Шолом-Алейхема, сдавших экзамены на отлично с 2007 по 2012 года (табл.1). А также делается прогноз данных на 2013 год и сравнение его с реальными данными.
Русские Блоги
Использование Matlab (11) нейронной сети
Искусственная нейронная сеть
Искусственные нейронные сети в основном используются для моделирования данных, прогнозирования, распознавания образов и оптимизации функций.
1. Основная теория
ANN (искусственная нейтральная сеть, искусственная нейронная сеть) представляет собой сложную сетевую систему, которая состоит из большого числа простых базовых элементов-нейронов, соединенных друг с другом, путем имитации обработки информации нервом мозга человека, параллельной обработки информации и нелинейного преобразования.
1. Основные математические основы сети БП
2. Панель инструментов
1. Функция создания сети БП
Возможные переменные и их значения:
| переменная | смысл |
|---|---|
| PR | R X 2 матрица, состоящая из максимального и минимального значений каждого набора входных элементов |
| Si | первый i » role=»presentation»> i Длина слоя, всего N » role=»presentation»> N слой |
| TFi | первый i » role=»presentation»> i Функция возбуждения слоя, по умолчанию «tansig» |
| BTF | Функция обучения по сети, по умолчанию «trainlm» |
| BLF | Алгоритм обучения для весов и пороговых значений, по умолчанию «Learningngdm» |
| PF | Функция производительности сети, по умолчанию «mse» |
1. Функция newcf
Эта функция используется для создания сети BP
Среди них net = newff используется для создания сети BP в диалоговом окне.
2. Функция newfftd
Эта функция используется для создания прямой сети с задержкой на вход
Среди них net = newfftd используется для создания сети BP в диалоговом окне.
2. Функция возбуждения нейрона
Функция возбуждения должна быть непрерывно дифференцируемой
1. Функции журнала
| кодовое значение | Информация возвращена |
|---|---|
| ‘deriv’ | Имя дифференциальной функции |
| ‘name’ | Полное имя функции |
| ‘output’ | Диапазон выхода |
| ‘active’ | Допустимый интервал ввода |
Алгоритм, используемый этой функцией:
2. Функция журнала
dlogsig является производной функцией logsig
Алгоритм, используемый этой функцией:
3. Функция тансиг
Алгоритм, используемый этой функцией:
4. Функция dtansig
Алгоритм, используемый этой функцией:
5. Функция purelin
Алгоритм, используемый этой функцией:
6. Функция дпурелин
Алгоритм, используемый этой функцией:
3. Функция обучения сети BP
1. Функция Learning
| кодовое значение | Информация возвращена |
|---|---|
| pnames | Вернуться к заданным параметрам обучения |
| pdefaults | Возвращает параметры обучения по умолчанию |
| needg | Если функция использует gW или gA, она возвращает 1 |
2. Функция learningngdm
Значение каждого параметра такое же, как learnngdm, а постоянная импульса mc задается параметром обучения LP, формат LP.mc = 0,8
4. Функция обучения сети BP
1. Функция trainbfg
Функция trainbfg является функцией квазиньютоновского алгоритма BP BFGS. В дополнение к сети BP эта функция может также обучать любую форму нейронной сети, требуя, чтобы ее функция возбуждения имела производные по весам и входам
| кодовое значение | Информация возвращена |
|---|---|
| pnames | Вернуться к заданным параметрам обучения |
| pdefaults | Возвращает параметры обучения по умолчанию |
При использовании этой функции для обучения сети BP, Matlab уже установил по умолчанию некоторые параметры обучения, как показано в таблице:
| Имя параметра | Значение по умолчанию | собственности |
|---|---|---|
| net.trainParam.epochs | 100 | Количество тренировок, количество тренировок, установленных вручную, не может превышать 100 |
| net.trainParam.show | 25 | Количество тренировочных шагов между дисплеями |
| net.trainParam.goal | 0 | Тренировочная цель |
| net.trainParam.time | inf | Время обучения, inf означает неограниченное время обучения |
| net.trainParam.min_grad | 1e-6 | Минимальный градиент производительности |
| net.trainParam.max_fail | 5 | Максимальное количество ошибок подтверждения |
| net.trainParam.searchFcn | ‘srchcha’ | Используется линейный путь поиска |
2. Функция traingd
Функция traingd является обучающей функцией алгоритма градиентного спуска BP
Значение, формат настройки и диапазон использования каждого параметра вышеупомянутой программы совпадают с функцией trainbfg
3. Функция traingdm
Функция traingdm является обучающей функцией алгоритма BP градиентного спуска
Значение, формат настройки и диапазон использования каждого параметра вышеупомянутой программы совпадают с функцией trainbfg
5. Производительность
1. Функция мсе
Функция mse является среднеквадратичной погрешностью
| кодовое значение | Информация возвращена |
|---|---|
| deriv | Возвращает имя производной функции |
| name | Возвращаем полное имя функции |
| pnames | Возвращает название функции обучения |
| pdefaults | Возвращает функцию обучения по умолчанию |
2. Функция мсерег
Значение каждого параметра в вышеприведенной программе совпадает со значением функции mse.
Функция msereg заключается в добавлении среднеквадратичной ошибки весов и порогов сети на основе функции mse, цель состоит в том, чтобы заставить сеть получать меньшие веса и пороги, тем самым заставляя отклик сети становиться более плавным
3. Меры предосторожности при формировании нейронной сети
1. Количество нейронных узлов
Количество входных и выходных узлов сети определяется размером фактической проблемы и не имеет никакого отношения к производительности сети. Расчет числа узлов L скрытого слоя очень важен и обычно может быть определен с использованием одной из следующих двух эмпирических формул
Среди них m 、 n » role=»presentation»> m 、 n Соответственно, количество входных узлов и количество выходных узлов; a » role=»presentation»> a Постоянная между 1
Количество скрытых узлов может быть получено из начального значения в соответствии с двумя вышеупомянутыми формулами, и затем число нейронов может быть окончательно определено методом ступенчатого роста или пошагового сокращения. Постепенный рост начинается с более простой сети: если результат обучения не соответствует требованиям, постепенно увеличивайте количество нейронов скрытого слоя до тех пор, пока он не станет подходящим, постепенное сокращение начинается с более сложной сети и постепенно удаляет нейроны скрытого слоя
2. Предварительная обработка данных и последующая обработка
Методы предварительной обработки, предоставляемые в MATLAB, следующие:
1. Функция premnmx
Функция нормализации premnmx
Где р R × Q » role=»presentation»> R × Q Размерная матрица ввода; pn стандартизирован R × Q » role=»presentation»> R × Q Размер входной матрицы; minp R × 1 » role=»presentation»> R × 1 Измерение содержит вектор минимального значения каждого компонента p; maxp равен R × 1 » role=»presentation»> R × 1 Размерность содержит вектор максимального значения каждого компонента p; tn нормируется S × Q » role=»presentation»> S × Q Размерная целевая матрица; мята S × 1 » role=»presentation»> S × 1 Измерение содержит каждый компонент t; maxt является S × 1 » role=»presentation»> S × 1 Размер содержит вектор максимального значения каждого компонента t
Алгоритм, используемый этой функцией:
4. Примеры
Описание проблемы
Дорожное движение в основном включает автомобильные пассажирские перевозки и автомобильные грузовые перевозки. Согласно исследованиям, объем дорожного движения в определенном районе в основном связан с количеством людей в этом районе, количеством автомобилей и площадью дорог.
Согласно данным соответствующих департаментов, число людей в регионе в 2010 и 2011 годах составило 733 900 и 755 500 человек соответственно, количество автомобилей составило 3,9635 и 40 975 000 человек соответственно, а площадь дороги составит 0,9880 и 1,0268 миллиона квадратных километров соответственно.
Пожалуйста, используйте сеть BP, чтобы прогнозировать автомобильные пассажирские и автомобильные перевозки в регионе в 2010 и 2011 годах.