Все модели машинного обучения за 5 минут
Mar 6, 2020 · 5 min read


Фундаментальная сегментация моделей машинного обучения
Все модели машинного обучения разделяются на обучение с учителем (supervised) и без учителя (unsupervised). В первую категорию входят регрессионная и классификационная модели. Рассмотрим значения этих терминов и входящие в эти категории модели.
Обучение с учителем
Представляет собой изучение функции, которая преобразует входные данные в выходные на основе примеров пар ввода-вывода.
Например, из набора данных с двумя переменными: возраст (входные данные) и рост (выходные данные), можно реализовать модель обучения для прогнозирования роста человека на основе его возраста.

Пример обучения с учителем
Повторюсь, обучение с учителем подразделяется на две подкатегории: регрессия и классификация.
Регрессия
В регре с сионных моделях вывод является непрерывным. Ниже приведены некоторые из наиболее распространенных типов регрессионных моделей.
Линейная регрессия

Пример линейной регрессии
Задача линейной регрессии заключается в нахождении линии, которая наилучшим образом соответствует данным. Расширения линейной регрессии включают множественную линейную регрессию (например, поиск наиболее подходящей плоскости) и полиномиальную регрессию (например, поиск наиболее подходящей кривой).
Дерево решений
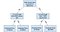
Изображение из Kaggle
Дерево решений — популярная модель, используемая в исследовании операций, стратегическом планировании и машинном обучении. Каждый прямоугольник выше называется узлом. Чем больше узлов, тем более точным будет дерево решений. Последние узлы, в которых принимается решение, называются листьями дерева. Деревья решений интуитивны и просты в создании, однако не предоставляют точные результаты.
Случайный лес
Случайный лес — это техника ансамбля методов, основанная на деревьях решений. Случайные леса включают создание нескольких деревьев решений с использованием первоначальных наборов данных и случайный выбор поднабора переменных на каждом этапе. Затем модель выбирает моду (значение, которое встречается чаще других) из всех прогнозов каждого дерева решений. Какой в этом смысл? Модель “победы большинства” снижает риск ошибки отдельного дерева.

Например, у нас есть одно дерево решений (третье), которое предсказывает 0. Однако если полагаться на моду всех 4 деревьев, прогнозируемое значение будет равно 1. В этом заключается преимущество случайных лесов.
Нейронная сеть

Визуальное представление нейронной сети
Нейронная сеть — это многослойная модель, устроенная по системе человеческого мозга. Как и нейроны в нашем мозге, круги выше представляют узлы. Синим обозначен слой входных данных, черным — скрытые слои, а зеленым — слой выходных данных. Каждый узел в скрытых слоях представляет функцию, через которую проходят входные данные, приводящие к выходу в зеленых кругах.
Классификация
В классификационных моделях вывод является дискретным. Ниже приведены некоторые из наиболее распространенных типов классификационных моделей.
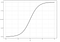
Логистическая регрессия
Логистическая регрессия аналогична линейной регрессии, но используется для моделирования вероятности ограниченного числа результатов, обычно двух. Логистическое уравнение создается таким образом, что выходные значения могут находиться только между 0 и 1:
Метод опорных векторов
Метод опорных векторов — это классификационный метод обучения с учителем, довольно сложный, но достаточно интуитивный на базовом уровне.
Предположим, что существует два класса данных. Метод опорных векторов находит гиперплоскость или границу между двумя классами данных, которая максимизирует разницу между двумя классами. Есть множество плоскостей, которые могут разделить два класса, но только одна из них максимизирует разницу или расстояние между классами.

Наивный Байес
Наивный Байес — еще один популярный классификатор, используемый в науке о данных. Его идея лежит в основе теоремы Байеса:

Несмотря на ряд нереалистичных предположений, сделанных в отношении наивного Байеса (отсюда и название “наивный”), он не только доказал свою эффективность в большинстве случаев, но и относительно прост в построении.
Обучение без учителя

В отличие от обучения с учителем, обучение без учителя используется для того, чтобы сделать выводы и найти шаблоны из входных данных без отсылок на помеченные результаты. Два основных метода, используемых в обучении без учителя, включают кластеризацию и снижение размерности.
Кластеризация

Кластеризация — это техника обучения без учителя, которая включает в себя группирование или кластеризацию точек данных. Чаще всего она используется для сегментации потребителей, выявления мошенничества и классификации документов.
Распространенные методы кластеризации включают кластеризацию с помощью k-средних, иерархическую кластеризацию, сдвиг среднего значения и кластеризацию на основе плотности. У каждого из них есть свой способ поиска кластеров, однако все они предназначены для достижения одного результата.
Понижение размерности
Снижение размерности — это процесс уменьшения числа рассматриваемых случайных переменных путем получения набора главных переменных. Проще говоря, это процесс уменьшения размера набора признаков (уменьшение количества признаков). Большинство методов снижения размерности могут быть классифицированы как отбор или извлечение признаков.
Популярный метод понижения размерности называется методом главных компонент (PCA). Он представляет собой проецирование многомерных данных (например, 3 измерения) в меньшее пространство (например, 2 измерения). Это приводит к уменьшению размерности данных (2 измерения вместо 3) при сохранении всех исходных переменных в модели.
5 алгоритмов регрессии в машинном обучении, о которых вам следует знать

Источник: Vecteezy
Да, линейная регрессия не единственная
Быстренько назовите пять алгоритмов машинного обучения.
Вряд ли вы назовете много алгоритмов регрессии. В конце концов, единственным широко распространенным алгоритмом регрессии является линейная регрессия, главным образом из-за ее простоты. Однако линейная регрессия часто неприменима к реальным данным из-за слишком ограниченных возможностей и ограниченной свободы маневра. Ее часто используют только в качестве базовой модели для оценки и сравнения с новыми подходами в исследованиях.
Команда Mail.ru Cloud Solutions перевела статью, автор которой описывает 5 алгоритмов регрессии. Их стоит иметь в своем наборе инструментов наряду с популярными алгоритмами классификации, такими как SVM, дерево решений и нейронные сети.
1. Нейросетевая регрессия
Теория
Нейронные сети невероятно мощные, но их обычно используют для классификации. Сигналы проходят через слои нейронов и обобщаются в один из нескольких классов. Однако их можно очень быстро адаптировать в регрессионные модели, если изменить последнюю функцию активации.
Каждый нейрон передает значения из предыдущей связи через функцию активации, служащую цели обобщения и нелинейности. Обычно активационная функция — это что-то вроде сигмоиды или функции ReLU (выпрямленный линейный блок).
Источник. Свободное изображение
Но, заменив последнюю функцию активации (выходной нейрон) линейной функцией активации, выходной сигнал можно отобразить на множество значений, выходящих за пределы фиксированных классов. Таким образом, на выходе будет не вероятность отнесения входного сигнала к какому-либо одному классу, а непрерывное значение, на котором фиксирует свои наблюдения нейронная сеть. В этом смысле можно сказать, что нейронная сеть как бы дополняет линейную регрессию.
Нейросетевая регрессия имеет преимущество нелинейности (в дополнение к сложности), которую можно ввести с сигмоидной и другими нелинейными функциями активации ранее в нейронной сети. Однако чрезмерное использование ReLU в качестве функции активации может означать, что модель имеет тенденцию избегать вывода отрицательных значений, поскольку ReLU игнорирует относительные различия между отрицательными значениями.
Это можно решить либо ограничением использования ReLU и добавлением большего количества отрицательных значений соответствующих функций активации, либо нормализацией данных до строго положительного диапазона перед обучением.
Реализация
Используя Keras, построим структуру искусственной нейронной сети, хотя то же самое можно было бы сделать со сверточной нейронной сетью или другой сетью, если последний слой является либо плотным слоем с линейной активацией, либо просто слоем с линейной активацией. (Обратите внимание, что импорты Keras не указаны для экономии места).
model = Sequential()
model.add(Dense(100, input_dim=3, activation=’sigmoid’))
model.add(ReLU(alpha=1.0))
model.add(Dense(50, activation=’sigmoid’))
model.add(ReLU(alpha=1.0))
model.add(Dense(25, activation=’softmax’))
#IMPORTANT PART
model.add(Dense(1, activation=’linear’))
Проблема нейронных сетей всегда заключалась в их высокой дисперсии и склонности к переобучению. В приведенном выше примере кода много источников нелинейности, таких как SoftMax или sigmoid.
Если ваша нейронная сеть хорошо справляется с обучающими данными с чисто линейной структурой, возможно, лучше использовать регрессию с усеченным деревом решений, которая эмулирует линейную и высокодисперсную нейронную сеть, но позволяет дата-сайентисту лучше контролировать глубину, ширину и другие атрибуты для контроля переобучения.
2. Регрессия дерева решений
Теория
Деревья решений в классификации и регрессии очень похожи, поскольку работают путем построения деревьев с узлами «да/нет». Однако в то время как конечные узлы классификации приводят к одному значению класса (например, 1 или 0 для задачи бинарной классификации), деревья регрессии заканчиваются значением в непрерывном режиме (например, 4593,49 или 10,98).
Иллюстрация автора
Из-за специфической и высокодисперсной природы регрессии просто как задачи машинного обучения, регрессоры дерева решений следует тщательно обрезать. Тем не менее, подход к регрессии нерегулярен — вместо того, чтобы вычислять значение в непрерывном масштабе, он приходит к заданным конечным узлам. Если регрессор обрезан слишком сильно, у него слишком мало конечных узлов, чтобы должным образом выполнить свою задачу.
Следовательно, дерево решений должно быть обрезано так, чтобы оно имело наибольшую свободу (возможные выходные значения регрессии — количество конечных узлов), но недостаточно, чтобы оно было слишком глубоким. Если его не обрезать, то и без того высокодисперсный алгоритм станет чрезмерно сложным из-за природы регрессии.
Реализация
Регрессия дерева решений может быть легко создана в sklearn :
Бонус: близкий родственник дерева решений, алгоритм random forest (алгоритм случайного леса), также может быть реализован в качестве регрессора. Регрессор случайного леса может работать лучше или не лучше, чем дерево решений в регрессии (в то время как он обычно работает лучше в классификации) из-за тонкого баланса между избыточным и недостаточным в природе алгоритмов построения дерева.
3. Регрессия LASSO
Метод регрессии лассо (LASSO, Least Absolute Shrinkage and Selection Operator) — это вариация линейной регрессии, специально адаптированная для данных, которые демонстрируют сильную мультиколлинеарность (то есть сильную корреляцию признаков друг с другом).
Она автоматизирует части выбора модели, такие как выбор переменных или исключение параметров. LASSO использует сжатие коэффициентов (shrinkage), то есть процесс, в котором значения данных приближаются к центральной точке (например среднему значению).
Иллюстрация автора. Упрощенная визуализация процесса сжатия
Процесс сжатия добавляет регрессионным моделям несколько преимуществ:
Регрессия лассо использует регуляризацию L1, то есть взвешивает ошибки по их абсолютному значению. Вместо, например, регуляризации L2, которая взвешивает ошибки по их квадрату, чтобы сильнее наказывать за более значительные ошибки.
Такая регуляризация часто приводит к более разреженным моделям с меньшим количеством коэффициентов, так как некоторые коэффициенты могут стать нулевыми и, следовательно, будут исключены из модели. Это позволяет ее интерпретировать.
Реализация
В sklearn регрессия лассо поставляется с моделью перекрестной проверки, которая выбирает наиболее эффективные из многих обученных моделей с различными фундаментальными параметрами и путями обучения, что автоматизирует задачу, которую иначе пришлось бы выполнять вручную.
4. Гребневая регрессия (ридж-регрессия)
Теория
Гребневая регрессия или ридж-регрессия очень похожа на регрессию LASSO в том, что она применяет сжатие. Оба алгоритма хорошо подходят для наборов данных с большим количеством признаков, которые не являются независимыми друг от друга (коллинеарность).
Однако самое большое различие между ними в том, что гребневая регрессия использует регуляризацию L2, то есть ни один из коэффициентов не становится нулевым, как это происходит в регрессии LASSO. Вместо этого коэффициенты всё больше приближаются к нулю, но не имеют большого стимула достичь его из-за природы регуляризации L2.
Сравнение ошибок в регрессии лассо (слева) и гребневой регрессии (справа). Поскольку гребневая регрессия использует регуляризацию L2, ее площадь напоминает круг, тогда как регуляризация лассо L1 рисует прямые линии. Свободное изображение. Источник
В лассо улучшение от ошибки 5 до ошибки 4 взвешивается так же, как улучшение от 4 до 3, а также от 3 до 2, от 2 до 1 и от 1 до 0. Следовательно, больше коэффициентов достигает нуля и устраняется больше признаков.
Однако в гребневой регрессии улучшение от ошибки 5 до ошибки 4 вычисляется как 5² − 4² = 9, тогда как улучшение от 4 до 3 взвешивается только как 7. Постепенно вознаграждение за улучшение уменьшается; следовательно, устраняется меньше признаков.
Гребневая регрессия лучше подходит в ситуации, когда мы хотим сделать приоритетными большое количество переменных, каждая из которых имеет небольшой эффект. Если в модели требуется учитывать несколько переменных, каждая из которых имеет средний или большой эффект, лучшим выбором будет лассо.
Реализация
Гребневую регрессию в sklearn можно реализовать следующим образом (см. ниже). Как и для регрессии лассо, в sklearn есть реализация для перекрестной проверки выбора лучших из многих обученных моделей.
5. Регрессия ElasticNet
Теория
ElasticNet стремится объединить лучшее из гребневой регрессии и регрессии лассо, комбинируя регуляризацию L1 и L2.
Лассо и гребневая регрессия представляют собой два различных метода регуляризации. В обоих случаях λ — это ключевой фактор, который контролирует размер штрафа:
5 алгоритмов регрессии в машинном обучении, о которых вам следует знать
Источник: Vecteezy
Да, линейная регрессия не единственная
Быстренько назовите пять алгоритмов машинного обучения.
Вряд ли вы назовете много алгоритмов регрессии. В конце концов, единственным широко распространенным алгоритмом регрессии является линейная регрессия, главным образом из-за ее простоты. Однако линейная регрессия часто неприменима к реальным данным из-за слишком ограниченных возможностей и ограниченной свободы маневра. Ее часто используют только в качестве базовой модели для оценки и сравнения с новыми подходами в исследованиях.
Команда Mail.ru Cloud Solutions перевела статью, автор которой описывает 5 алгоритмов регрессии. Их стоит иметь в своем наборе инструментов наряду с популярными алгоритмами классификации, такими как SVM, дерево решений и нейронные сети.
1. Нейросетевая регрессия
Теория
Нейронные сети невероятно мощные, но их обычно используют для классификации. Сигналы проходят через слои нейронов и обобщаются в один из нескольких классов. Однако их можно очень быстро адаптировать в регрессионные модели, если изменить последнюю функцию активации.
Каждый нейрон передает значения из предыдущей связи через функцию активации, служащую цели обобщения и нелинейности. Обычно активационная функция — это что-то вроде сигмоиды или функции ReLU (выпрямленный линейный блок).
Источник. Свободное изображение
Но, заменив последнюю функцию активации (выходной нейрон) линейной функцией активации, выходной сигнал можно отобразить на множество значений, выходящих за пределы фиксированных классов. Таким образом, на выходе будет не вероятность отнесения входного сигнала к какому-либо одному классу, а непрерывное значение, на котором фиксирует свои наблюдения нейронная сеть. В этом смысле можно сказать, что нейронная сеть как бы дополняет линейную регрессию.
Нейросетевая регрессия имеет преимущество нелинейности (в дополнение к сложности), которую можно ввести с сигмоидной и другими нелинейными функциями активации ранее в нейронной сети. Однако чрезмерное использование ReLU в качестве функции активации может означать, что модель имеет тенденцию избегать вывода отрицательных значений, поскольку ReLU игнорирует относительные различия между отрицательными значениями.
Это можно решить либо ограничением использования ReLU и добавлением большего количества отрицательных значений соответствующих функций активации, либо нормализацией данных до строго положительного диапазона перед обучением.
Реализация
Используя Keras, построим структуру искусственной нейронной сети, хотя то же самое можно было бы сделать со сверточной нейронной сетью или другой сетью, если последний слой является либо плотным слоем с линейной активацией, либо просто слоем с линейной активацией. (Обратите внимание, что импорты Keras не указаны для экономии места).
model = Sequential()
model.add(Dense(100, input_dim=3, activation=’sigmoid’))
model.add(ReLU(alpha=1.0))
model.add(Dense(50, activation=’sigmoid’))
model.add(ReLU(alpha=1.0))
model.add(Dense(25, activation=’softmax’))
#IMPORTANT PART
model.add(Dense(1, activation=’linear’))
Проблема нейронных сетей всегда заключалась в их высокой дисперсии и склонности к переобучению. В приведенном выше примере кода много источников нелинейности, таких как SoftMax или sigmoid.
Если ваша нейронная сеть хорошо справляется с обучающими данными с чисто линейной структурой, возможно, лучше использовать регрессию с усеченным деревом решений, которая эмулирует линейную и высокодисперсную нейронную сеть, но позволяет дата-сайентисту лучше контролировать глубину, ширину и другие атрибуты для контроля переобучения.
2. Регрессия дерева решений
Теория
Деревья решений в классификации и регрессии очень похожи, поскольку работают путем построения деревьев с узлами «да/нет». Однако в то время как конечные узлы классификации приводят к одному значению класса (например, 1 или 0 для задачи бинарной классификации), деревья регрессии заканчиваются значением в непрерывном режиме (например, 4593,49 или 10,98).
Иллюстрация автора
Из-за специфической и высокодисперсной природы регрессии просто как задачи машинного обучения, регрессоры дерева решений следует тщательно обрезать. Тем не менее, подход к регрессии нерегулярен — вместо того, чтобы вычислять значение в непрерывном масштабе, он приходит к заданным конечным узлам. Если регрессор обрезан слишком сильно, у него слишком мало конечных узлов, чтобы должным образом выполнить свою задачу.
Следовательно, дерево решений должно быть обрезано так, чтобы оно имело наибольшую свободу (возможные выходные значения регрессии — количество конечных узлов), но недостаточно, чтобы оно было слишком глубоким. Если его не обрезать, то и без того высокодисперсный алгоритм станет чрезмерно сложным из-за природы регрессии.
Реализация
Регрессия дерева решений может быть легко создана в sklearn :
Бонус: близкий родственник дерева решений, алгоритм random forest (алгоритм случайного леса), также может быть реализован в качестве регрессора. Регрессор случайного леса может работать лучше или не лучше, чем дерево решений в регрессии (в то время как он обычно работает лучше в классификации) из-за тонкого баланса между избыточным и недостаточным в природе алгоритмов построения дерева.
3. Регрессия LASSO
Метод регрессии лассо (LASSO, Least Absolute Shrinkage and Selection Operator) — это вариация линейной регрессии, специально адаптированная для данных, которые демонстрируют сильную мультиколлинеарность (то есть сильную корреляцию признаков друг с другом).
Она автоматизирует части выбора модели, такие как выбор переменных или исключение параметров. LASSO использует сжатие коэффициентов (shrinkage), то есть процесс, в котором значения данных приближаются к центральной точке (например среднему значению).
Иллюстрация автора. Упрощенная визуализация процесса сжатия
Процесс сжатия добавляет регрессионным моделям несколько преимуществ:
Регрессия лассо использует регуляризацию L1, то есть взвешивает ошибки по их абсолютному значению. Вместо, например, регуляризации L2, которая взвешивает ошибки по их квадрату, чтобы сильнее наказывать за более значительные ошибки.
Такая регуляризация часто приводит к более разреженным моделям с меньшим количеством коэффициентов, так как некоторые коэффициенты могут стать нулевыми и, следовательно, будут исключены из модели. Это позволяет ее интерпретировать.
Реализация
В sklearn регрессия лассо поставляется с моделью перекрестной проверки, которая выбирает наиболее эффективные из многих обученных моделей с различными фундаментальными параметрами и путями обучения, что автоматизирует задачу, которую иначе пришлось бы выполнять вручную.
4. Гребневая регрессия (ридж-регрессия)
Теория
Гребневая регрессия или ридж-регрессия очень похожа на регрессию LASSO в том, что она применяет сжатие. Оба алгоритма хорошо подходят для наборов данных с большим количеством признаков, которые не являются независимыми друг от друга (коллинеарность).
Однако самое большое различие между ними в том, что гребневая регрессия использует регуляризацию L2, то есть ни один из коэффициентов не становится нулевым, как это происходит в регрессии LASSO. Вместо этого коэффициенты всё больше приближаются к нулю, но не имеют большого стимула достичь его из-за природы регуляризации L2.
Сравнение ошибок в регрессии лассо (слева) и гребневой регрессии (справа). Поскольку гребневая регрессия использует регуляризацию L2, ее площадь напоминает круг, тогда как регуляризация лассо L1 рисует прямые линии. Свободное изображение. Источник
В лассо улучшение от ошибки 5 до ошибки 4 взвешивается так же, как улучшение от 4 до 3, а также от 3 до 2, от 2 до 1 и от 1 до 0. Следовательно, больше коэффициентов достигает нуля и устраняется больше признаков.
Однако в гребневой регрессии улучшение от ошибки 5 до ошибки 4 вычисляется как 5² − 4² = 9, тогда как улучшение от 4 до 3 взвешивается только как 7. Постепенно вознаграждение за улучшение уменьшается; следовательно, устраняется меньше признаков.
Гребневая регрессия лучше подходит в ситуации, когда мы хотим сделать приоритетными большое количество переменных, каждая из которых имеет небольшой эффект. Если в модели требуется учитывать несколько переменных, каждая из которых имеет средний или большой эффект, лучшим выбором будет лассо.
Реализация
Гребневую регрессию в sklearn можно реализовать следующим образом (см. ниже). Как и для регрессии лассо, в sklearn есть реализация для перекрестной проверки выбора лучших из многих обученных моделей.
5. Регрессия ElasticNet
Теория
ElasticNet стремится объединить лучшее из гребневой регрессии и регрессии лассо, комбинируя регуляризацию L1 и L2.
Лассо и гребневая регрессия представляют собой два различных метода регуляризации. В обоих случаях λ — это ключевой фактор, который контролирует размер штрафа: