Практическое руководство: предсказать отток клиентов
Дата публикации Jan 15, 2019

Прежде чем мы начнем, давайте кратко напомним, что такое отток на самом деле: «Отток» определяет количество клиентов, которые отписались или аннулировали свой контракт на обслуживание. Клиенты, отворачивающиеся от ваших услуг или продуктов, не приносят удовольствия любому бизнесу. Очень дорого отыграть их, когда они проиграли, даже не думая, что они не сделают все от них зависящее, если не будут удовлетворены.Узнайте все об основах оттока клиентов в одной из моих предыдущих статей, Теперь давайте начнем!
Как мы прогнозируем отток клиентов?

Инструменты, которые мы используем

Чтобы предсказать, изменится ли клиент или нет, мы работаем с Python и его удивительными библиотеками с открытым исходным кодом. Прежде всего мы используем Jupyter Notebook, приложение с открытым исходным кодом для живого программирования, которое позволяет нам рассказать историю с помощью кода. Кроме того, мы импортируемПанды, который помещает наши данные в простую в использовании структуру для анализа данных и преобразования данных. Чтобы сделать исследование данных более понятным, мы используемplotlyвизуализировать некоторые из наших идей. Наконец сscikit учитьсямы разделим наш набор данных и обучим нашу прогнозную модель.
Набор данных
Одним из наиболее ценных активов компании являются данные. Поскольку данные редко публикуются, мы берем доступный набор данных, который вы можете найти наIBMsвеб-сайт, а также на других страницах, таких какKaggle: Набор данных клиентов Telcom. Набор необработанных данных содержит более 7000 записей. Все записи имеют несколько функций и, конечно, столбец с указанием, изменился ли клиент.
Чтобы лучше понять данные, мы сначала загрузим их в панды и исследуем их с помощью некоторых очень простых команд.
Исследование и выбор функций
Этот раздел довольно короткий, так как вы можете узнать больше об общих исследованиях данных в лучших руководствах. Тем не менее, чтобы получить первоначальное представление и узнать, какую историю вы можете рассказать с помощью данных, исследование данных имеет определенный смысл. Используя функции python data.head (5) и «data.shape», мы получаем общий обзор набора данных.

Подробно мы рассмотрим целевую особенность, фактический «отток». Поэтому мы строим его соответственно и видим, что 26,5% от общего объема оттока клиентов Это важно знать, поэтому в наших данных об обучении мы имеем одинаковую долю клиентов с постоянным числом клиентов и клиентов с нулевым уровнем

Подготовка данных и разработка функций
Помните, что чем лучше мы подготовим наши данные для модели машинного обучения, тем лучше будет наш прогноз. У нас может быть самый продвинутый алгоритм, но если наши тренировочные данные отстой, наш результат тоже будет отстой. По этой причине ученые-данные тратят так много времени на подготовку данных. А так как предварительная обработка данных занимает много времени, но здесь это не главное, мы проведем несколько примерных преобразований.
3. Преобразование числовых признаков из объекта
Из нашего исследования данных (в данном случае «data.dtypes ()») мы видим, что столбцы MonthlyCharges и TotalCharges являются числами, но на самом деле в формате объекта. Почему это плохо? Наша модель машинного обучения может работать только с фактическими числовыми данными. Поэтому с помощью функции «to_numeric» мы можем изменить формат и подготовить данные для нашей модели машинного обучения.

Кроме того, мы могли бы использовать функцию «get_dummies ()» для всех категориальных переменных в наборе данных. Это мощная функция, но может быть неприятно иметь так много дополнительных столбцов.
Логистическая регрессия и тестирование моделей
Логистическая регрессия является одним из наиболее часто используемых алгоритмов машинного обучения, и в основном используется, когда зависимая переменная (здесь отток 1 или отток 0) является категориальной. Независимые переменные, напротив, могут быть категориальными или числовыми. Обратите внимание, что, конечно, имеет смысл детально понять теорию, лежащую в основе модели, но в этом случае наша цель состоит в том, чтобы использовать прогнозы, которые мы не пройдем через эту статью.
Шаг 1. Давайте импортируем модель, которую мы хотим использовать из sci-kit learn
Шаг 2. Делаем экземпляр модели
Шаг 3. Проводится ли обучение модели на основе набора обучающих данных и сохраняется ли информация, извлеченная из данных?
С обученной моделью мы можем теперь предсказать, изменился ли клиент для нашего тестового набора данных. Результаты сохраняются в «gnition_test », а затем измеряется и распечатывается оценка точности.

Результаты показывают, что в 80% случаев наша модель предсказывала правильный результат для нашей проблемы бинарной классификации. Это считается очень хорошим для первого запуска, особенно когда мы смотрим, какое влияние оказывает каждая переменная и имеет ли это смысл. Таким образом, с конечной целью сократить отток и своевременно предпринять правильные предупреждающие действия, мы хотим знать, какие независимые переменные больше всего влияют на наш прогнозируемый результат. Поэтому мы устанавливаем коэффициенты в нашей модели на ноль и смотрим вес каждой переменной.

Можно заметить, что некоторые переменные имеют положительное отношение к нашей предсказанной переменной, а некоторые имеют отрицательное отношение. Положительное значение оказывает положительное влияние на нашу прогнозируемую переменную. Хорошим примером является «Контракт-месяц-месяц»: положительное отношение к оттоку означает, что наличие такого типа контракта также увеличивает вероятность оттока клиента. С другой стороны, «Контракт_Два года» находится в крайне негативном отношении к прогнозируемой переменной, а это означает, что клиенты с таким типом контракта вряд ли будут набирать деньги. Но мы также видим, что некоторые переменные не имеют смысла в первом пункте. «Fiber_Optic» находится на верхней позиции с точки зрения положительного влияния на отток. Хотя мы ожидаем, что это заставит клиента остаться, поскольку он предоставляет ему быстрый интернет, наша модель говорит о другом. Здесь важно копать глубже и получить некоторый контекст для данных.
Посмотрите на их профиль, определите характеристики и проанализируйте прошлые взаимодействия с вашим продуктом, а затем просто поговорите с ними. Попросите обратную связь, расскажите о последних разработках, которые могут быть интересны, или ознакомьте их с новыми функциями продукта. Подходите к клиентам, которые, скорее всего, произойдут, но убедитесь, что вы предлагаете подходящие вещи, которые могут соответствовать их индивидуальным потребностям. Это создаст ощущение понимания и привязывает их к вам и вашему бизнесу.
Предсказание оттока пользователей с помощью метода RFM
Представьте: телефонный звонок в три часа ночи, вы берете трубку и слышите крик о том, что больше никто не пользуется вашим продуктом. Страшно? В жизни, конечно, все не так, но если не уделять должное внимание проблеме оттока пользователей, можно оказаться в похожей ситуации.
Мы уже подробно рассказали, что такое отток: углубились в теорию и показали, как превратить нейросеть в цифрового оракула. Специалисты студии Plarium Krasnodar знают еще один способ предсказания. О нем мы и поговорим.

Это не тот RFM, что нам нужен
RFM — это метод, который используется для сегментации клиентов и анализа их поведения. На основе полученных данных можно создать программу лояльности для каждой группы, построить распределение пользователей и спрогнозировать, когда они вернутся за покупками.
История разработки RFM началась в 1987 году, когда была опубликована статья Counting Your Customers: Who Are They and What Will They Do Next. В ней описывался метод анализа, основанный на распределении Парето (двухпараметрическое семейство абсолютно непрерывных распределений).
Модель называлась Pareto/NBD и учитывала лишь историю покупок пользователей. В классической трактовке работа этого метода строилась на пяти столпах, или приближениях:
В статье 2003 года «Counting Your Customers» the Easy Way: An Alternative to the Pareto/NBD Model была опубликована идея реализации более совершенной модели. Помимо истории покупок, в ней использовались еще два параметра: частота и давность. Главным ее отличием от Pareto/NBD было то, как определяется момент ухода покупателя.
В классической постановке предполагалось, что пользователь способен уйти в любое время, независимо от частоты и рисунка его покупок в прошлом. Новый подход основан на гипотезе, что покупатель может начать терять интерес сразу после завершения сделки.
Это упростило вычисления и привело к модели beta-geometric (BG/NBD). В ней используются три основных параметра: recency, frequency, monetary, — а также четыре дополнительных: r, α, a, b (параметры a и b добавились из бета-распределения).
RFM помогает предсказать, совершит ли клиент покупку в будущем. Специалисты Plarium Krasnodar модифицировали этот метод.
Предсказываем отток просто и со вкусом
Для расчетов нам понадобится массив данных об игровых сессиях. Он пересчитывается в матрицу, состоящую из параметров R-F-M, и еще в четыре коэффициента, которые выбираются моделью в процессе обучения.
Вычисления производятся по формуле: 
Очевидно, что для пользователей без повторных входов вероятность «жизни» будет равна единице. В 2008 году авторы статьи Computing P(alive) Using the BG/NBD Model предложили решение этой проблемы. Игровые компании могут использовать два варианта, которые дают похожие результаты.
Метод 1 — для всех пользователей вводится параметр π. Он показывает, какие игроки считаются неактивными.
Метод 2 — добавляется единица к параметру Frequency. Эта мера позволяет избежать вырождения формулы при Frequency = 0, но искусственно добавляет еще один вход в игру для каждого пользователя.
Как адаптировать метод RFM для геймдева
Предположим, что у нас есть новый пользователь. Он только что вошел в игру. Параметр F = 1 (либо 0, в зависимости от расчетов), так как первый вход не считается, а повторных у игрока еще не было.
Пользователь играет три дня. Параметры меняются: F учитывает только ежедневные входы, поэтому его значение равно 2, а показатели М и R равны 3. Используя эти данные, мы получаем вероятность «жизни», приближенную к единице.
На следующий день пользователь не заходит в игру. Параметр М обновляется, а F и R остаются прежними. Подставляя все значения в формулу, мы видим, что показатель вероятности стал ниже.
Если в течение недели пользователь не играет, то показатель М вновь обновляется и вероятность «жизни» падает еще больше. 
График активного пользователя выглядит иначе. Вероятность «жизни» будет уменьшаться в зависимости от его истории. Если он ежедневно заходил в игру и внезапно перестал, то значение показателя упадет намного быстрее, чем если бы он играл раз в два дня. 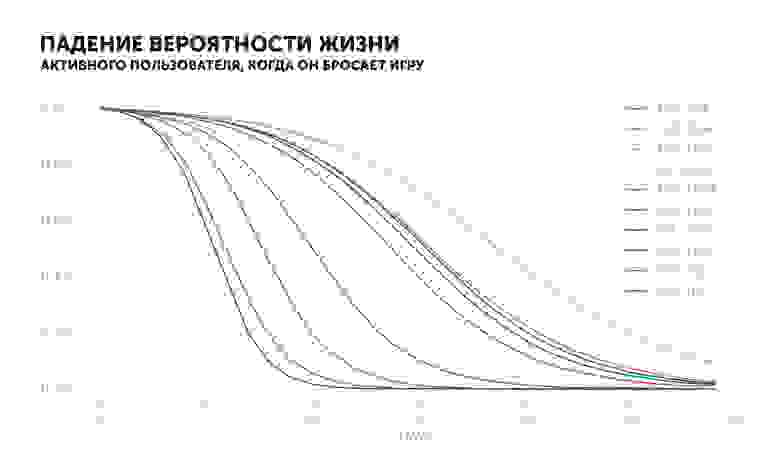
Весомые плюсы и неочевидные минусы RFM
Главное достоинство этого метода — простота:
Минусы у RFM тоже есть. Во-первых, это не самый точный метод. Он работает хорошо, но при расчетах не используется ряд параметров. Например, многие пользователи, начинающие терять интерес, по привычке заходят в игру. То есть среднее количество игровых сессий в сутки падает, а частота повторных входов не изменяется.
Во-вторых, метод не учитывает активность пользователя: сколько ресурсов он передал, атаковал ли противника, создал ли войска. Если мы возьмем всех игроков с вероятностью «жизни» равной
0,8, то в зависимости от параметров и их истории кроме активных будут и те, которые заходят раз в три дня.
В-третьих, ушедший пользователь становится «живым», когда снова запускает игру. При чем он может сделать это спустя месяц с момента последнего входа. Такие ситуации усложняют детекцию игроков с большими паузами между сессиями. В целом это не критично, хотя и вносит определенный дисбаланс, когда мы пытаемся понять, «жив» пользователь или нет.
Не лучше ли использовать нейросеть?
Лучше, но в первую очередь нужно понять, как реализовать проект: решать масштабные задачи с наскока или постепенно двигаться к цели.
RFM-анализ показывает вероятность «жизни» пользователя в момент, когда производится расчет. Мы не сможем понять, уйдет игрок через две или три недели, а нейросеть сможет. Учитывая всю инфраструктуру, создать такую комплексную систему для анализа поведения игроков с нуля гораздо сложнее. Более того, необходима baseline, с которой можно сравнить качество работы нейронной сети. Подобный подход, скорее всего, обернется финансовыми потерями, если не рассчитать силы.
Наш опыт показывает, что глобальные задачи нужно реализовывать постепенно. Создать рабочий прототип несложно, а вот собрать и обработать данные, настроить и обучить нейросеть — другое дело. Эти процессы могут растянуться на долгое время, которого всегда не хватает.
Именно поэтому мы решили сначала воспользоваться более простой моделью: провели исследования, выявили плюсы и минусы, опробовали ее в работе. Результаты нас устроили. У RFM есть недостатки, но они щедро компенсируются простотой использования. А нейронная сеть — следующий шаг к улучшению системы.
Предсказываем отток с помощью нейросети

Проблема предсказания оттока клиентов — одна из самых распространенных в практике Data Science (так теперь называется применение статистики и машинного обучения к бизнес-задачам, уже все знают?). Проблема достаточно универсальна: она актуальна для многих отраслей — телеком, банки, игры, стриминг-сервисы, ритейл и пр. Необходимость ее решения довольно легко обосновать с экономической точки зрения: есть куча статей в бизнес-журналах о том, что привлечь нового клиента в N раз дороже, чем удержать старого. И ее базовая постановка проста для понимания так, что на ее примере часто объясняют основы машинного обучения.
Для нас в Plarium-South, как и для любой игровой компании, эта проблема также актуальна. Мы прошли длинный путь через разные постановки и модели и пришли к достаточно оригинальному, на наш взгляд, решению. Все ли так просто, как кажется, как правильно определить отток и зачем тут нейросеть, расскажем под катом.
Отток? Не, не слышал.
Начнем, как полагается, с определений. Есть база клиентов, которые пользуются какими-то услугами, покупают какие-то товары, в нашем случае — играют в игры. В какой-то момент отдельные клиенты перестают пользоваться сервисом, уходят. Это и есть отток. Предполагается, что в тот момент, когда клиент подает первые признаки ухода, его еще можно переубедить: обнять, рассказать, как он важен, предложить скидку, сделать подарок. Таким образом, первоочередная задача состоит в том, чтобы правильно и своевременно предсказать, что клиент собирается уйти.
Может показаться, что возможных значений целевой переменной тут два: пациент либо жив, либо мертв. И действительно, ищем соревнования по предсказанию оттока (крэкс, пэкс, фэкс) и везде видим задачу бинарной классификации: объекты — пользователи, целевая переменная — бинарная. Здесь ярко видно отличие спортивного анализа данных от практического. В практическом анализе перед тем как решать задачу, приходится ее еще и ставить, да так, чтобы из ее решения можно было извлечь прибыль. Чем и займемся.
Отток оттоку рознь
При более близком рассмотрении мы узнаем, что можно выделить два типа оттока — договорный (contractual) и недоговорный (non-contractual). В первом случае клиент явным образом говорит, что он устал и он уходит. Зачастую это сопровождается формальными действиями по прекращению контракта и т. п. В этом случае, действительно, можно четко определить, когда человек является твоим клиентом, когда нет. В недоговорном случае клиент ничего не говорит, никак не уведомляет и просто перестает пользоваться вашим сервисом, услугой, играть в вашу игру и покупать ваши товары. И, как вы уже догадались, второй случай гораздо более распространен.
То есть вы имеете в CRM / базе данных некую активность пользователей (покупки, заходы на сайт, звонки в сотовой сети), которая в какой-то момент уменьшается. Заметьте, не обязательно прекращается, но существенно изменяет интенсивность.
Всех под одну гребенку
Изобразим дни визитов трех гипотетических клиентов синими крестиками на оси времени. Первая мысль — зафиксировать некий период (тут он называется Target definition). Определенную активность в течение этого периода будем считать проявлением жизни, а отсутствие таковой — уходом. Тогда в качестве входных данных для модели предсказания оттока можно взять данные за период до рассматриваемого (Input data).
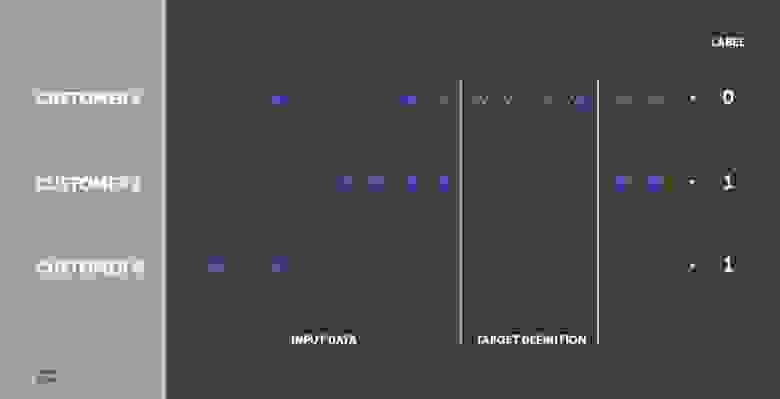
Можно также предусмотрительно оставить между двумя этими периодами некий буфер, например 1–2 недели, с целью научиться предсказывать отток заранее, чтобы успеть совершить некие действия по вразумлению удержанию клиента.
Что плохого в таком подходе? Непонятно, как правильно задать параметры. Какой период взять для определения целевой переменной. Для одного клиента трехдневное отсутствие — это безусловный уход, для другого — стандартное поведение. Вы скажете: “Давайте возьмем большой промежуток — месяц, год, два, тогда точно все попадут”. Тут может возникнуть проблема с историческими данными, т. к. не у всех они хранятся так долго. Кроме того, если мы будем строить модель на данных годичной давности, она может не подходить для текущей ситуации. И, к тому же, чтобы проверить результат работы нашей модели на актуальных данных, придется ждать год. Можно ли не уходить глубоко в историю, а еще лучше вообще обойтись без уравниловки?
Вероятность 50/50 — либо ушел, либо нет
Если мы знаем историю заходов пользователя: как он в среднем себя вел до этого и как давно отсутствует сейчас, — нельзя ли подобрать правильные статистические распределения и посчитать вероятность того, что пользователь жив в данный момент? Можно, и уже было сделано в модели Pareto/NBD еще в 1987 году, где время до ухода описывалось распределением Парето (смесь экспонент с гамма-весами), а распределение визитов/покупок — отрицательным биномиальным. В 2003 возникла идея вместо распределения Парето использовать бета-геометрическое и появилась модель BG/NBD, которая работает быстрее и зачастую без потери качества. Обе модели достойны внимания, и есть хорошие реализации обеих на Python и R. На вход эти модели принимают только три значения по каждому пользователю: количество визитов/покупок, возраст клиента (время, прошедшее с первой покупки до текущего момента) и время, прошедшее с последней покупки. При таком бедном наборе входных данных модели работают очень достойно, что говорит о том, что рановато пока забывать теорвер, его вполне еще можно применять — в промежутках между тем, как «стакать xgboost-ы».
При этом потенциал для улучшений еще есть. Например, есть сезонность, промоакции, влияющие на статистику заходов, — их эти модели не учитывают. Есть другие данные об активности пользователя, которые могут говорить о близости ухода. Так, в конец разочаровавшийся в игре пользователь может попусту растратить ресурсы (не пропадать же добру), распустить войско. Данные о таком поведении могут помочь отличить реальный уход от временного отсутствия (отпуск в джунглях без интернета). Все эти данные нельзя “скормить” вероятностным моделям, описанным выше (хотя есть уважаемые люди, которые пытаются это сделать).
Вызываю нейросеть
А что если взять и построить нейросеть, на выходе которой будут параметры распределений? Про это есть магистерская диссертация выпускника Гетеборгского университета и написанный в рамках нее и прекрасно проиллюстрированный пакет на Python — WTTE-RNN.
Автор решил предсказывать время до следующего захода (time to event) с помощью распределения Вейбулла и всей мощи рекуррентных нейросетей. Кроме теоретической красоты подхода здесь есть еще и важный практический момент: при использовании рекуррентных нейросетей не нужно городить огород с построением признаков из временных рядов (агрегировать набор рядов набором функций по набору периодов и набору лагов), чтобы представить данные в виде плоской таблицы (объекты — признаки). Можно подать временные ряды на вход сети как есть. Подробнее об этом мы недавно рассказывали в ходе доклада на PiterPy. Это серьезно экономит вычислительные и временные ресурсы. Кроме рядов одного типа (например, по дням), можно также подать на вход и ряды другого типа или длины (например, почасовые за последний день), и статические характеристики пользователей (пол, страна), хоть картинку с его портретом (вдруг лысые уходят чаще?), нейросети и такое умеют.
Однако оказалось, что построенная по Вейбуллу функция потерь при обучении часто уходит в NaN. Кроме того, временем до следующего захода не так просто оперировать. Знание его не избавляет от необходимости отвечать на вопросы, какое время до захода считать слишком большим, как рассчитать пороги для каждого пользователя в отдельности и учитывая всяческую сезонность, как отсеять временные перерывы в активности и т. д.
Что же делать?
Не претендуя на однозначную правильность принятого решения, расскажем, какой путь в итоге выбрали мы в Plarium-South. Мы вернулись к бинарному таргету, рассчитали его хитрым образом, а в качестве модели взяли RNN.
Почему к бинарному?
Прогнозирование и сокращение оттока клиентов с помощью машинного обучения
Эта статья посвящена применению машинного обучения для предотвращения оттока клиентов. На примере одного клиента мы покажем, как определить потребность, проблему, найти решение и ключевые преимущества.
Есть и некоторые другие косвенные результаты, связанные с оттоком клиентов. Ушедшие клиенты начинают новые отношения с конкурентами компании. Иногда они могут даже попытаться забрать с собой других постоянных клиентов.
В одной из недавних исследовательских заметок PWC был сделан вывод о том, что:
«Финансовые учреждения потеряют 24% выручки в ближайшие 3-5 лет, в основном из-за оттока клиентов в новые финтех-компании.»
По причинам, упомянутым выше и многим другим, сокращение оттока клиентов является ключевой бизнес-стратегией для большинства компаний. Даже если сокращение оттока клиентов не является стратегической целью компании, это определенно в их интересах, чтобы сохранить каждого клиента.
Итак, теперь, когда мы понимаем, что такое отток клиентов и почему он должен быть решен в срочном порядке, давайте рассмотрим различные подходы, которые компании используют сегодня для решения этой проблемы.
Как правило, племенные знания и/или предвзятое суждение используются для выявления клиентов, которые, вероятно, могут уйти. В таких сценариях вы, скорее всего, в конечном итоге нацельтесь на клиентов, которые не будут покидать вас. Предоставление таким клиентам стимулов к удержанию добавляет ненужные эксплуатационные расходы. Кроме того, вы рискуете не достучаться до клиентов, которые могут действительно уйти. Следовательно, вы в конечном итоге теряете свой бизнес.
Теперь, когда мы понимаем, что такое отток клиентов и почему он должен быть решен в срочном порядке, давайте рассмотрим различные подходы, которые компании используют сегодня для решения этой проблемы.
Мы углубимся в тематическое исследование, в котором излагаются потребности, проблемы, решения, подходы и преимущества для решения. Данные, имена, номера и некоторые другие элементы были анонимизированы / рандомизированы для защиты конфиденциальной информации и уважения их конфиденциальности. Такой пример приводит один из калифорнийских стартапов.
Бизнес: Международный Банк.
Отрасль: Финансовые Услуги.
Потребность: крупные банки теряют клиентов из-за финтех-стартапов. Стартапы используют основанный на данных подход к приобретению, обслуживанию и удержанию клиентов. Крупные банки нуждаются в инновациях, чтобы удержать клиентов. Они должны активно обращаться к клиентам, которые могут уйти.
Проблема: ведущий многонациональный банк фокусируется на частном банковском деле. Банк столкнулся с возросшим оттоком клиентов за прошедший период из-за возросшей конкуренции на рынке. Банк обладает большим объемом клиентских данных, но не использует их эффективно.
Кроме того, банк хочет понять факторы, влияющие на отток капитала, чтобы они могли быть более активными в решении таких вопросов, а не просто реагировать постфактум. Реальная проблема и потребность заключается в том, чтобы уменьшить отток клиентов, стабилизировать бизнес и увеличить прибыль.
Решение: с помощью платформы на базе ИИ, в банке начали обнаруживать характеристики, которые вызвали отток клиентов. Эти закономерности были выявлены автоматически с помощью лежащих в их основе сложных алгоритмов машинного обучения. Кроме того, профиль оттока клиентов выявил высокодоходных клиентов в зоне риска. Проактивные кампании теперь проводятся регулярно, чтобы гарантировать, что они могут удержать таких клиентов, прежде чем они уйдут.
Подход: вот трехэтапный подход, который действительно хорошо работал для банка:
Определите и подключитесь к нужному набору данных: данные о клиентах, включая демографию, активы, кредитные баллы, жалобы, счета, срок владения и т. д.
Преобразование данных самообслуживания: были удалены неважные столбцы, отсутствующие/недействительные данные исправлены с помощью быстрых опций, данные из различных источников объединены вместе.
Автоматические аналитические данные в один клик: были обнаружены аналитические данные, которые создали профиль оттока клиентов. Были предсказаны характеристики таких клиентов и их склонность к оттоку. Эта прогностическая модель теперь используется для прогнозирования и уменьшения оттока, активно обращаясь к ним.
Интересные идеи автоматически всплывали на поверхность с помощью двигателя искусственного интеллекта.Эти открытия поразили команду многонационального банка. Вот несколько ключевых:
Как мы видели в приведенном выше примере, один из ведущих транснациональных банков смог использовать платформу на базе ИИ, чтобы понять, почему их клиенты уходят. Теперь они могут активно бороться с оттоком капитала. Обратите внимание, что все инсайты были обнаружены автоматически, не тратя 100 часов на ручное обнаружение данных или не написав ни одной строки кода.
Система использовала лежащие в ее основе алгоритмы машинного обучения для ответа на конкретные бизнес-вопросы и обнаружения скрытых инсайтов в данных.
Работники банка теперь могут четко понимать профили клиентов, которые уходят. Они могут обратиться к существующим клиентам, которые соответствуют такому профилю, и принять превентивные меры для снижения оттока.
Celado Unchurn позволяет делать аналогичный анализ внутри вашей системы с сохранением персональных данных и интегрировано в вашу CRM или ERP систему
В следующих материалах расскажем о наших внедрениях.