Steal time что это
Хотя бы не жаль времени, затраченного на беглое прочтение.
Хотя мысль я понял. ИМХО лучше так:
«Из-за обработки прерывания на гипервизоре для виртуалки это
выглядит как отправленный запрос(К HDD например), она готова к исполнению и ждёт процессора, но
процессорного времени ей не дают ГОРАЗДО ДОЛЬШЕ ЧЕМ ПРИ РАБОТЕ С РЕАЛЬНЫМ ЖЕЛЕЗОМ. ГИПЕРВИЗОР МОЖЕТ УЧИТЫВАТЬ ЭТУ РАЗНИЦУ как украденое время.»
А может и не учитывать, зависит от реализации драйвера. И реальный оверхэд в случае паравиртуальных драйверов может быть минимален и может быть не заметен. А в случае эмуляции реального железа, действительно может быть большим.
А тут ты драйвер позвал, опачки. вся система потеряла несколько тиков таймера, и не может понять, куда.
причем тут обработка прерываний?
> отношение к этой теме и к тому, о чём я написал.
то что ты написал, не имеет никакого отношения к реальности.
>в драйверах реального железа нет и не может быть ситуаций когда управление надолго занято драйвером, чего ты так и не понял.
Перегруженность хоста это один из случаев. Бывает что недобросовестность поставщика тут не при чём, а так задуманно.
Нередко сталкиваемся с высоким steal у AWS. Когда виртуалка систематически потребляет больше процессора чем было расчитанно и съедает доступные CPU credits, ей начинают ограничивать циклы. Изнутри выглядит как подтормаживание, не катастрофическое, и высокий прохент steal. Мониторингом на steal специально не смотрим, т.к. ползёт вверх Load Average и на него прилетает алерт. С другой стороны, механизм CPU credits хорошо защищяет от «шумных соседей» (noisy nighbors) и можно расчитывать на тот ресурс который проплачен. Если знать в чём дело и куда смотреть, то удобно.
Как мы помогли cybersport.ru справиться с The International 10
Наш клиент cybersport.ru — один из самых популярных информационно-новостных порталов про киберспорт в СНГ. По данным Similarweb, в октябре 2021 года у сайта было 16,5 млн посещений.
Обычно нагрузка на cybersport.ru даже во время значимых событий не превышает 400 RPS (requests per second). Так было до недавнего времени, точнее — до The International 10. Турнир вернулся после годичного перерыва из-за пандемии, что подогрело интерес к нему. Ажиотажа добавило и успешное выступление российских команд. В итоге во время турнира нагрузка достигала небывалых для сайта 2300 RPS.

Серверы и сайт выдержали в основном за счет оперативного масштабирования ресурсов. И в этом, конечно, нет ничего необычного — рядовая задача для инженеров эксплуатации. Однако, чтобы всё четко отработало во время The International 10, нашей команде пришлось провести подготовительные работы, в том числе кубернетизацию инфраструктуры cybersport.ru.
В этом посте расскажем:
зачем cybersport.ru нужно было переезжать в Kubernetes и о сопутствующих трудностях;
почему пришлось сменить IaaS-провайдера;
почему было сложно во время The International 10, и как мы с этим справились;
почему автоматическое масштабирование ресурсов — не лучший выход для cybersport.ru (и вообще, для веб-ресурсов с таким же характером нагрузки).
Переезд в Kubernetes
Сайт cybersport.ru — часть киберспортивного холдинга ESforce, в который также входит самая титулованная киберспортивная команда России Virtus.pro. «Флант» уже более 3 лет поддерживает инфраструктуру ESforce.
 Игрок Virtus.pro Тимур «buster» Тулепов (CS:GO)
Игрок Virtus.pro Тимур «buster» Тулепов (CS:GO)
До того, как мы подключились к проектам ESforce, инфраструктура всех проектов, включая cybersport.ru, была развернута на облачных серверах одного из ведущих западных провайдеров. Простейший CI/CD был организован на базе Ansible и управлялся через Ansible Tower. Разработчикам не хватало гибкости инфраструктуры, она была плохо адаптирована к cloud native-среде. Поэтому мы предложили перенести все важные сервисы в Kubernetes, настроить CI/CD и организовать review-окружения.
При миграции в K8s наши SRE-/DevOps-инженеры тесно взаимодействовали с разработчиками ESforce. Всё прошло без больших задержек и серьезных проблем. Небольшие трудности возникали только во время построения CI/CD-процесса, но они оперативно решались.
Чехарда с провайдерами
Переезд в Kubernetes состоялся еще в облаке зарубежного поставщика, но от него в итоге пришлось отказаться. Основные причины:
конфликт Telegram и Роскомнадзора: когда РКН стал блокировать пулы адресов, — включая те, что принадлежат провайдеру, — под угрозой оказались и сайты ESforce;
требования 152-ФЗ: российские веб-проекты должны хранить данные на территории РФ;
дороговизна по сравнению с ценами на российские облака.
Этап 1. Переезд в российское облако
Благодаря унифицированной и кубернетизированной инфраструктуре, миграция к одному из российских провайдеров прошла легко и быстро. Однако впоследствии мы столкнулись с проблемой, которой не было у западного провайдера: CPU steal time.
Если кратко, CPU steal time — задержка, которая вызвана перегруженностью гипервизоров при оверселлинге CPU. Виртуальные машины (ВМ) начинают конкурировать за выделение ресурсов; та ВМ, которая недополучает ресурсы, начинает сильно замедляться. Это в свою очередь приводит к проблемам в работе ОС и приложений.
Ниже — архивный график с данными нашей системы мониторинга. На нем видно, насколько высоким был уровень CPU steal time:
Проблема привела к тому, что инфраструктура стала нестабильной, постоянно сбоила; снизился SLA. Посыпались новые неприятности — даже такие, с которыми мы раньше не сталкивались. В такой обстановке не могло быть и речи об оптимизации инфраструктуры и кода, поскольку сложно было определить первопричину сбоев в работе приложения.
Этап 2. Переезд на «железные» серверы
В 2019 году не все российские облачные поставщики гарантировали отсутствие CPU steal time. Поэтому мы решили переехать к другому провайдеру, на «железные» серверы.
После переезда, в ходе оптимизации инфраструктуры и приложения, обнаружился ряд узких мест.
1. Redis. Изучив данные APM-системы (Application Performance Monitoring), мы выявили некорректное взаимодействие приложения и Redis. Количество подключений к сервису достигало 1,2 млн запросов в минуту; объем Set/Get-операций был слишком высок. В итоге Redis отвечал долго, сайты работали медленно.
Ниже — графики с результатами нагрузочного тестирования:
В некоторые моменты в Redis поступало более 1 млн запросов в минуту Время веб-транзакций доходило до 750 мс из-за медленных ответов Redis Время ответа сервера при 300+ OPS (operations per second)
Вместе с разработчикам нам удалось оперативно обнаружить причину. Оказалось, что дело в неправильно настроенном процессе кэширования, из-за которого в кэш помещались постоянно обновляемые данные.
2. Нагрузка на PostgreSQL. Приложение создавало сетевую нагрузку на Postgres в 1 Гбит/с. Это было потолком для «железных» серверов в текущей конфигурации и приводило к недоступности cybersport.ru.
Как мы решили проблему:
Перевели проект на 10 Гбит/с;
Оптимизировали запросы к БД со стороны кода.
Этап 3. Обратно в облако
Популярность cybersport.ru росла, нагрузка — тоже. Сайту требовалось больше вычислительных ресурсов, которые можно было бы оперативно наращивать. Вдобавок, за соответствие 152-ФЗ у текущего поставщика приходилось доплачивать. То есть нужен был cloud-провайдер с гарантированным ресурсом по CPU и приемлемым ценником за 152-ФЗ. И в 2021 году cybersport.ru наконец-таки обосновались в облаке российского провайдера, который удовлетворял обоим критериям.
Влияние пандемии
К моменту переезда к новому провайдеру все более или менее значимые киберспортивные мероприятия отменили. У cybersport.ru не было реальной возможности оценить отказоустойчивость инфраструктуры во время пиковых нагрузок, кроме как с помощью синтетических тестов. Но для таких веб-сервисов синтетические тесты малополезны: они далеки от поведения реальных пользователей. Тем не менее, других вариантов не было, и мы готовились к The International 10 как могли — «в теории»…
И на старте турнира возникли некоторые проблемы.
The International 10. Проверка боем
В реальных условиях не всё пошло гладко. Сперва даже относительно невысокая нагрузка — в 600 RPS — приводила к тому, что сайт падал. Основные причины:
«разумная экономия» и, как следствие, ограничение количества заказываемых ресурсов под возрастающую нагрузку;
характер самой нагрузки, ее пиковость — мы быстро упирались в доступный объем ресурсов, а пока заказывали новые, серверы «пятисотили».
Пример пиков нагрузки во время The International 10
Небольшое отступление: автомасштабирование в Kubernetes
И в идеальном случае, т. е. когда нет финансовых и технических ограничений, желательно обеспечить несколько уровней горизонтального масштабирования и резервирования приложения — на уровне Pod’ов (количества экземпляров приложения) и на уровне кластера (количества узлов).
Автомасштабирование Pod’ов:
выбираем метрику, на основе которой будут масштабироваться Pod’ы. В случае с PHP-приложениями ориентируемся на количество занятых php-fpm-процессов (детальнее об этом — ниже);
выбираем количество min/maxReplicas на основе предварительных нагрузочных тестов — если гипотетические уровни нагрузки еще неизвестны;
Автомасштабирование узлов:
используем standby-узлы для ситуаций с резкими и непредсказуемыми всплесками трафика. Они вроде «горячего резерва», который позволяет пережить первый наплыв пользователей и не ждать дозаказа обычных узлов при масштабировании Pod’ов;
настраиваем триггеры и алерты на желаемые значения, чтобы контролировать траты на дозаказ узлов.
Но случай с cybersport.ru был особый.
Почему мы ограничили автомасштабирование
С помощью Kubernetes-платформы Deckhouse легко настраивать гибкое автоматическое масштабирование узлов. Более того, Deckhouse сама умеет заказывать дополнительные ВМ у провайдера. Однако в случае с cybersport.ru автомасштабирование оказалось не самым оптимальным решением.
В проекте была необходимость строго соблюдать бюджет на инфраструктуру. При этом нетипичная нагрузка на сайт приходит хотя и резко, но редко и прогнозируемо. Например, во время старта значимого турнира RPS всего за несколько секунд может вырасти с 300 до 2000.
Вместе с клиентом мы решили пойти на компромисс и выработали особый подход: масштабировать инфраструктуру с помощью изменения пары параметров в манифесте. При этом в 100% случаев изменение затрат на инфраструктуру — например, дозаказ ВМ — контролирует инженер (согласуя с менеджером проекта).
Суть в том, чтобы заранее выставить оправданные и достаточные min/max-значения для HPA/CA и подготовить нужное количество standby-узлов; это занимает буквально несколько минут, весь остальной процесс — автоматический. После чего запуск новых Pod’ов происходит самостоятельно и в достаточном объеме для приходящей нагрузки. Всё остальное время количество ВМ можно держать на минимуме, не переплачивая за простаивающие ВМ. По такой схеме мы и действовали во время The International 10 — правда, в чуть более стрессовом режиме, чем планировали, поскольку недооценили нагрузки, которые предстоит принять.
Пример настройки HPA (Horizontal Pod Autoscaler)
Вот пример конфига, который отвечает за автомасштабирование Pod’ов — аналогичный тому, что мы использовали для Cybersport.ru:
Кратко — о ключевых параметрах этой конфигурации:
1. Выбираем важные метрики. Прежде всего, необходимо определиться со спецификой приложения, которое мы собираемся масштабировать. Многое зависит от того, как правильно определять его загруженность. В случае с PHP-приложением, которое работает на php-fpm, идеальная метрика — загруженность child’ов (количество idle или active). По этой метрике легко определить, сколько child’ов в запасе. Отталкиваясь от этого, решаем — увеличивать или уменьшать количество реплик.
2. Настраиваем масштабирование. Для HPA создаем специальную метрику, измеряющую процент занятых child’ов. Затем в самом манифесте HPA ссылаемся на эту метрику и выставляем желаемые пороги срабатывания ( averageValue ). В нашем случае 60% занятых процессов, приводят к появлению новых Pod’ов, чтобы снизить этот средний процент.
Важный момент. Сразу после запуска HPA необходимо забыть о ручной регулировке количества реплик через deployment scale . Если этот параметр не будет совпадать с «мнением» HPA, то вызовет ненужное создание или пересоздание Pod’ов — это может негативно сказаться на пользователях.
От 600 до 2300 RPS
Как выяснилось, 600 RPS — это не предел: нагрузка росла ежедневно и достигла пика в последний день The International — 17 октября.
То, что происходило с сайтом во время турнира, лучше всего описал Павел Вирский, тимлид команды разработки cybersport.ru (приводим фрагмент поста Павла из корпоративного Slack’а нашей DevOps-команды):

Павел Вирский, тимлид команды разработки cybersport.ru
«Закончился The International, который был большим испытанием для нашего сайта и серверов и не меньшим вызовом и для нас и для вас. Начиналось всё 8 октября, когда 600 rps укладывали сайт на лопатки. Затем рекорд побивали ещё несколько раз, но с каждым разом всё более подготовленными. И закончилось сегодня, когда при (невероятных для меня) 2300 rps сайт работал. А нагрузка в 1200-1400 стала настолько рядовой, что мы спокойно выкладывали обновления. »
Подытожим
Сейчас инфраструктура cybersport.ru оптимизирована. Единственное, что требуется для принятия нагрузки, — своевременный дозаказ ресурсов. Но это не значит, что улучшать больше нечего. Что еще можно сделать:
Разместить Redis на выделенных узлах кластера. Если во время резкого роста нагрузки Redis окажется на нагруженном узле, это может негативно повлиять на инфраструктуру: Redis будет «аффектиться» и вызывать проблемы в работе всех сайтов, которые с ним взаимодействуют. В идеале для сервиса нужно выделить отдельную группу узлов.
Увеличить количество slave-узлов для PostgreSQL. Чтобы БД не «упиралась» по скорости чтения в возможности диска, для гипотетических ситуаций можно добавить slave-узлов. По сути, основная нагрузка во время мероприятий создается операциями чтения в базу. Она достаточно легко масштабируется добавлением новых slave-узлов для репликации и перераспределении нагрузки.
Сейчас cybersport.ru такая оптимизация не нужна, и в обозримом будущем потребность в ней вряд ли не возникнет.
Главное, что благодаря Kubernetes, отлаженному CI/CD, а также четкому взаимодействию инженеров «Фланта» и разработчиков наш клиент достиг важных для себя результатов:
Инфраструктура стала надежнее: обновления можно деплоить даже под большой нагрузкой.
… и гибче: нет технических ограничений для своевременного масштабирования.
Появилась независимость от поставщика инфраструктуры: K8s-кластеры можно легко перенести в новое облако, на bare metal, куда угодно.
Приложение оптимизировано и лучше адаптировано для работы в cloud native-среде.
Параметр top st и CPU steal time
Выделение ресурсов
Диск выделяется для каждой машины жестко, как и оперативная память. Циклы CPU выделяются по другому.
Мастер сервер является физической машиной, имеющей какое-то количество ядер. Это может быть 8-12-24 или другое число. Виртуализация предполагает необходимость выделить всем VM ядра, которые те смогут использовать полностью.
Каким образом выделяются ядра определяется используемым гипервизором: KVM, Xen или другим.
Обычно ограничения для виртуальных машин задаются так, что из консоли (в top) VM можно увидеть все ядра CPU мастер сервера, использовать можно то их количество, которое выделено для машины.
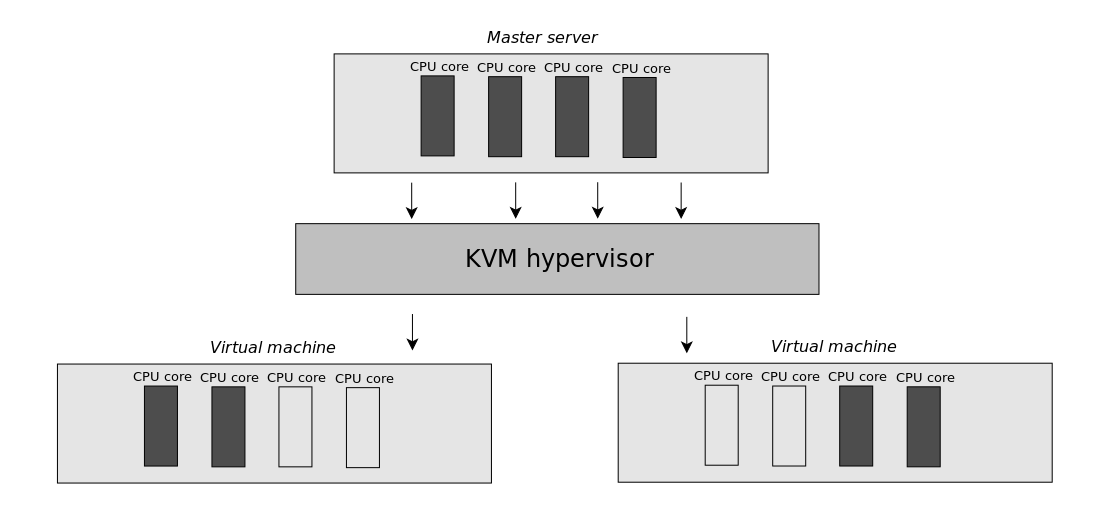
Современные версии KVM позволяют выделять ядра полностью, а не задавать ограничения. Т.е. в top VM будет отображаться только то, что фактически доступно. Пока это используется редко.
Виртуализация почти всегда происходит с Overselling-ом. Т.е. провайдеры продают больше ресурсов, чем есть в на мастер сервере рассчитывая на то, что все виртуальные машины не будут постоянно потреблять все выделяемые ресурсы.
Если на хосте запущено 10 виртуальных машин с одинаковым распределением CPU. Фактически это не означает, что каждая будет всегда получать 10%, гипервизор может варьировать пропорции.
Когда на VM множестве запускаются ресурсоемкие приложения гипервизор обнаруживает неспособность дать каждой машине столько CPU, сколько требуется. В таких случаях CPU перераспределяется.
Это означает, что если одни VM нагружают мастер сервер, другие будут недополучать ресурсы за которые их владельцы платят провайдеру.
CPU Steal Time, top st
В top st будет расти в двух случаях: если сама VM запрашивает больше ресурсов, чем есть в наличии или если их потребляют соседи по серверу и CPU не хватает.
На скриншоте ниже первый случай, полученный запуском утилиты stress с загрузкой 4 ядер CPU на VDS, которому доступно 2 ядра.
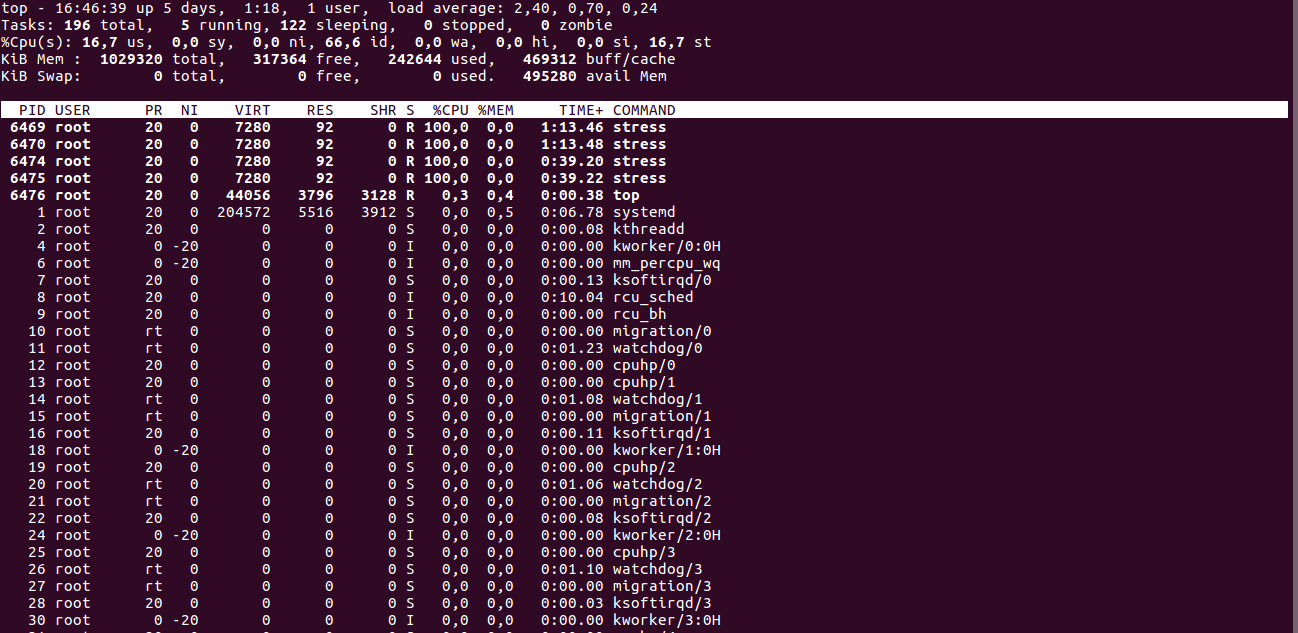
Значение st как можно увидеть — 16,7
Steal Time — циклы CPU, которые выделяются гипервизором для задач не связанных с данной VM. Фактически значение возрастает когда CPU загружен, но гипервизор решает выделить ресурсы другим процессам.
При отсутствии операций, загружающих процессор на VM, значение steal time не изменится.
Рост значения будет означать недополучение CPU
Подробную информацию по всем ядрам можно получить просмотрев файл /proc/stat, для восприятия она менее удобна, но в скриптах значение можно проверять и так
86879
9868
6326
10253
8791
7993
9135
6731
5178
5580
6484
5882
4652
Что делать если в top st растет
Значение steal time должно быть близким к нулю.
Для веб-серверов снижение количества выделяемых циклов CPU означает потерю производительности. Это снижение скорости вычисления или падение количества запросов, которое может быть обработано в единицу времени, что всегда плохо.
О проблемах свидетельствует рост в top st при неизменном потреблении процессами на виртуальной машине. Внимания заслуживают любые значения больше 5.
Отслеживать параметр особенно важно если используется кластеры из нескольких VM и каждая машина должна выполнять такие же функции, как другие за то же время.
Не придавать значения steal time можно только на физических серверах, вообще не использующих виртуализацию.
Steal: кто крадёт у виртуалок процессорное время

Привет! Хочу рассказать простым языком о механике возникновения steal внутри виртуальных машин и о некоторых неочевидных артефактах, которые нам удалось выяснить при его исследовании, в которое мне пришлось погрузиться как техдиру облачной платформы Mail.ru Cloud Solutions. Платформа работает на KVM.
CPU steal time — это время, в течение которого виртуальная машина не получает ресурсы процессора для своего выполнения. Это время считается только в гостевых операционных системах в средах виртуализации. Причины, куда деваются эти самые выделенные ресурсы, как и в жизни, весьма туманны. Но мы решили разобраться, даже поставили целый ряд экспериментов. Не то чтобы мы теперь всё знаем о steal, но кое-что интересное сейчас расскажем.
1. Что такое steal
Итак, steal — это метрика, указывающая на нехватку процессорного времени для процессов внутри виртуальной машины. Как описано в патче ядра KVM, steal — это время, в течение которого гипервизор выполняет другие процессы на хостовой ОС, хотя он поставил процесс виртуальной машины в очередь на выполнение. То есть, steal считается как разница между временем, когда процесс готов выполниться, и временем, когда процессу выделены процессорное время.
Метрику steal ядро виртуальной машины получает от гипервизора. При этом гипервизор не уточняет, какие именно другие процессы он выполняет, просто «пока занят, тебе времени уделить не могу». На KVM поддержка подсчёта steal добавлена в патчах. Ключевых моментов здесь два:
2. Что влияет на steal
2.1. Вычисление steal
По сути, steal считается примерно так же, как и обычное время утилизации процессора. Информации о том, как считается утилизация, не много. Наверное, потому что большинство считает этот вопрос очевидным. Но здесь тоже бывают подводные камни. Для ознакомления с этим процессом можно прочитать статью Brendann Gregg: вы узнаете о куче нюансов при расчете утилизации и о ситуациях, когда этот подсчёт будет ошибочным по следующим причинам:
Процесс подсчёта steal подвержен тем же самым проблемам, что и обычный подсчёт утилизации. Не сказать, что такие проблемы появляются часто, но выглядят обескураживающе.
2.2. Типы виртуализации на KVM
Вообще говоря, есть три типа виртуализации, и все они поддерживаются KVM. От типа виртуализации может зависеть механизм возникновения steal.
Трансляция. В этом случае работа операционной системы виртуальной машины с физическими устройствами гипервизора происходит примерно так:
Аппаратная виртуализация. В этом случае устройство на аппаратном уровне понимает команды из операционной системы. Это самый быстрый и хороший способ. Но, к сожалению, он поддерживается далеко не всеми физическими устройствами, гипервизорами и гостевыми операционками. На текущий момент основные устройства, которые поддерживают аппаратную виртуализацию, — это процессоры.
Паравиртуализация (paravirtualization). Самый распространённый вариант виртуализации устройств на KVM и вообще самый распространенный режим виртуализации для гостевых операционных систем. Особенность его в том, что работа с некоторыми подсистемами гипервизора (например, с сетевым или дисковым стеком) или выделение страниц памяти происходит с использованием API гипервизора, без трансляции низкоуровневых команд. Недостаток этого способа виртуализации — необходимость модификации ядра гостевой операционной системы, чтобы оно могло взаимодействовать с гипервизором с помощью этого API. Но обычно это решается за счет установки специальных драйверов на гостевую операционную систему. В KVM это API называется virtio API.
При паравиртуализации, по сравнению с трансляцией, путь до физического устройства значительно сокращается за счёт отправки команд напрямую из виртуальной машины в процесс гипервизора на хосте. Это позволяет ускорить выполнение всех инструкций внутри виртуальной машины. В KVM за это отвечает virtio API, который работает только для определенных устройств, вроде сетевого или дискового адаптера. Именно поэтому внутрь виртуальных машин ставятся virtio-драйверы.
Обратная сторона такого ускорения — не все процессы, которые выполняются внутри виртуалки, остаются внутри неё. Это создаёт некоторые спецэффекты, которые могут привести к появлению на steal. Подробное изучение этого вопроса рекомендую начать с An API for virtual I/O: virtio.
2.3. «Справедливый» шедулинг
Виртуалка на гипервизоре является, фактически, обычным процессом, который подчиняется законам шедулинга (распределения ресурсов между процессами) в ядре Linux, поэтому рассмотрим его подробнее.
В Linux используется так называемый CFS, Completely Fair Scheduler, начиная с ядра 2.6.23 ставший диспетчером по умолчанию. Чтобы разобраться с этим алгоритмом, можно почитать Linux Kernel Architecture или исходники. Суть CFS заключается в распределении процессорного времени между процессами в зависимости от длительности их выполнения. Чем больше процессорного времени требует процесс, тем меньше этого времени он получает. Это гарантирует «честное» выполнение всех процессов — чтобы один процесс не занимал все процессоры постоянно, и остальные процессы тоже могли выполняться.
Иногда такая парадигма приводит к интересным артефактам. Давние пользователи Linux наверняка помнят замирание обычного текстового редактора на десктопе во время запуска ресурсоемких приложений типа компилятора. Так получалось, потому что нересурсоемкие задачи десктопных приложений конкурировали с задачами, активно потребляющими ресурсы, такими как компилятор. CFS считает, что это нечестно, поэтому периодически останавливает текстовый редактор и даёт процессору обработать задачи компилятора. Это поправили с помощью механизма sched_autogroup, но остались многие другие особенности распределения процессорного времени между задачами. Собственно, это рассказ не про то, как всё плохо в CFS, а попытка обратить внимание на то, что «честное» распределение процессорного времени — не самая тривиальная задача.
Ещё один важный момент в шедулере — preemption. Это нужно, чтобы выгнать зажравшийся процесс с процессора и дать поработать другим. Процесс изгнания называется context switching, переключение контекста процессора. При этом сохраняется весь контекст таски: состояние стека, регистры и прочее, после чего процесс отправляется ждать, а на его место встает другой. Это дорогая операция для ОС, и используется она редко, но по сути ничего плохого в ней нет. Частое переключение контекста может говорить о проблеме в ОС, но обычно оно идет непрерывно и ни на что особенно не указывает.
Такой длинный рассказ нужен для объяснения одного факта: чем больше ресурсов процессора пытается потребить процесс в честном шедулере Linux, тем быстрее он будет остановлен, чтобы другие процессы тоже могли поработать. Правильно это или нет — сложный вопрос, который при разных нагрузках решается по-разному. В Windows до недавнего времени шедулер был ориентирован на приоритетную обработку десктопных приложений, из-за чего могли зависать фоновые процессы. В Sun Solaris было пять различных классов шедулеров. Когда запустили виртуализацию, добавили шестой, Fair share scheduler, потому что предыдущие пять работали с виртуализацией Solaris Zones неадекватно. Подробное изучение этого вопроса рекомендую начать с книг вроде Solaris Internals: Solaris 10 and OpenSolaris Kernel Architecture или Understanding the Linux Kernel.
2.4. Как мониторить steal?
Мониторить steal внутри виртуальной машины, как и любую другую процессорную метрику, просто: можно пользоваться любым средством съема метрик процессора. Главное, чтобы виртуалка была на Linux. Windows почему-то такую информацию своим пользователям не предоставляет. 🙁
Вывод команды top: детализация нагрузки на процессор, в крайней правой колонке — steal
Сложность возникает при попытке получить эту информацию с гипервизора. Можно попробовать спрогнозировать steal на хостовой машине, например, по параметру Load Average (LA) — усредненного значения количества процессов, ожидающих в очереди на выполнение. Методика подсчёта этого параметра непростая, но в целом, если пронормированный по количеству потоков процессора LA больше 1, это говорит о том, что сервер с линуксом чем-то перегружен.
Чего же ждут все эти процессы? Очевидный ответ — процессора. Но ответ не совсем правильный, потому что иногда процессор свободен, а LA зашкаливает. Вспомните, как отваливается NFS и как при этом растёт LA. Примерно так же может быть и с диском, и с другими устройством ввода/вывода. Но на самом деле, процессы могут ожидать окончания любой блокировки, как физической, связанной с устройством ввода/вывода, так и логической, например мьютекса. Туда же относятся блокировки на уровне железа (того же ответа от диска), или логики (так называемых блокировочных примитивов, куда входит куча сущностей, mutex adaptive и spin, semaphores, condition variables, rw locks, ipc locks. ).
Ещё одна особенность LA в том, что оно считается как среднее значение по операционной системе. К примеру, 100 процессов конкурируют за один файл, и тогда LA=50. Такое большое значение, казалось бы, говорит о том, что операционке плохо. Но для иного криво написанного кода это может быть нормальным состоянием, при том, что плохо только ему, а другие процессы в операционке не страдают.
Из-за этого усреднения (причём не меньше, чем за минуту), определение чего-то бы то ни было по показателю LA — не самое благодарное занятие, с весьма неопределёнными результатами в конкретных случаях. Если вы попытаетесь разобраться, то обнаружите, что в статьях на Википедии и прочих доступных ресурсах описаны только самые простые кейсы, без глубокого объяснения процесса. Всех интересующихся отправляю, опять же, сюда, к Brendann Gregg — далее по ссылкам. Кому лень на английском — перевод его популярной статьи про LA.
3. Спецэффекты
Теперь остановимся на основных кейсах появления steal, с которыми мы сталкивались. Расскажу, как они вытекают из всего вышесказанного и как соотносятся с показателями на гипервизоре.
Переутилизация. Самое простое и частое: гипервизор переутилизирован. Действительно, много запущенных виртуалок, большое потребление процессора внутри них, большая конкуренция, утилизация по LA больше 1 (в нормировке по процессорным тредам). Внутри всех виртуалок всё тормозит. Steal, передаваемый с гипервизора, также растёт, надо перераспределять нагрузку или кого-то выключать. В общем, всё логично и понятно.
Паравиртуализация против одиноких инстансов. На гипервизоре одна единственная виртуалка, она потребляет небольшую его часть, но даёт большую нагрузку по вводу/выводу, например по диску. И откуда-то в ней появляется небольшой steal, до 10 % (как показывают несколько проведённых экспериментов).
Случай интересный. Steal тут появляется как раз из-за блокировок на уровне паравиртуализированных драйверов. Внутри виртуалки создаётся прерывание, обрабатывается драйвером и уходит в гипервизор. Из-за обработки прерывания на гипервизоре для виртуалки это выглядит как отправленный запрос, она готова к исполнению и ждёт процессора, но процессорного времени ей не дают. Виртуалка думает, что это время украдено.
Это происходит в момент отправки буфера, он уходит в kernel space гипервизора, и мы начинаем его ждать. Хотя, с точки зрения виртуалки, он должен сразу вернуться. Следовательно, по алгоритму расчёта steal это время считается украденным. Скорее всего, в этой ситуации могут быть и другие механизмы (например, обработка ещё каких-нибудь sys calls), но они не должны сильно отличаться.
Шедулер против высоконагруженных виртуалок. Когда одна виртуалка страдает от steal больше других, это связано как раз с шедулером. Чем сильнее процесс нагружает процессор, тем скорее шедулер его выгонит, чтобы остальные тоже могли поработать. Если виртуалка потребляет немного, она почти не увидит steal: её процесс честно сидел и ждал, надо ему давать побольше времени. Если виртуалка производит максимальную нагрузку по всем своим ядрам, её чаще выгоняют с процессора и стараются не давать много времени.
Ещё хуже, когда процессы внутри виртуалки пытаются заполучить больше процессора, потому что не справляются с обработкой данных. Тогда операционная система на гипервизоре, за счёт честной оптимизации, будет давать всё меньше процессорного времени. Этот процесс происходит лавинообразно, и steal подскакивает до небес, хотя остальные виртуалки его могут почти не замечать. И чем больше ядер, тем хуже попавшей под раздачу машине. Короче говоря, больше всего страдают высоконагруженные виртуалки со множеством ядер.
Низкий LA, но есть steal. Если LA примерно 0,7 (то есть, гипервизор, кажется недозагружен), но внутри отдельных виртуалок наблюдается steal:
4. Другие искажения
Есть ещё миллион причин для искажений честной отдачи процессорного времени на виртуалке. Например, сложности в расчёты вносят гипертрединг и NUMA. Они окончательно запутывают выбор ядра для исполнения процесса, потому что шедулер использует коэффициенты — веса, которые при переключении контекста делают подсчёт ещё сложнее.
Бывают искажения из-за технологий типа турбобуста или, наоборот, режима энергосбережения, которые при подсчёте утилизации могут искусственно повышать или понижать частоту или даже квант времени на сервере. Включение турбобуста уменьшает производительность одного процессорного треда из-за увеличения производительности другого. В этот момент информация об актуальной частоте процессора виртуальной машине не передаётся, и она считает, что её время кто-то тырит (например, она запрашивала 2 ГГц, а получила вдвое меньше).
В общем, причин искажений может быть много. В конкретной системе вы можете обнаружить что-то ещё. Начать лучше с книг, на которые я дал линки выше, и съема статистики с гипервизора утилитами типа perf, sysdig, systemtap, коих десятки.