PHP: как удалить все непечатаемые символы в строке?
Я полагаю, что мне нужно удалить символы 0-31 и 127,
есть ли функция или часть кода, чтобы сделать это эффективно.
16 ответов
7 бит ASCII?
если ваша Тардис только что приземлилась в 1963 году, и вы просто хотите 7-битные печатные символы ASCII, вы можете вырвать все из 0-31 и 127-255 с помощью этого:
он соответствует чему-либо в диапазоне 0-31, 127-255 и удаляет его.
8 бит расширенный ASCII?
Ах, добро пожаловать в 21 век. Если у вас есть строка в кодировке UTF-8, то /u модификатор может использоваться в регулярном выражении
это просто удаляет 0-31 и 127. Это работает в ASCII и UTF-8, потому что оба разделяют тот же диапазон набора управления (как отмечено mgutt ниже). Строго говоря, это будет работать без /u модификатор. Но она облегчает жизнь, если вы хотите удалить другие символы.
если вы имеете дело с Unicode, есть потенциально много непечатающих элементов, но давайте рассмотрим простой один: ПРОСТРАНСТВО БЕЗ ПЕРЕРЫВА (U+00A0)
добавление: как насчет str_replace?
preg_replace довольно эффективен, но если вы делаете эту операцию много, вы можете создать массив символов, которые хотите удалить, и использовать str_replace, как отмечено mgutt ниже, например
интуитивно кажется, что это будет быстро, но это не всегда так, вы должны обязательно проверить, если это спасет вас что-нибудь. Я сделал несколько тестов по различным длинам строк с помощью случайные данные, и этот шаблон появился с использованием php 7.0.12
сами тайминги предназначены для 10000 итераций, но что более интересно, это относительные различия. До 512 символов, я видел еще всегда выигрывают. В диапазоне 1-8kb str_replace имел маргинальное ребро.
Я думал, что это интересный результат, так это здесь. главное не принять этот результат и использовать его, чтобы решить, какой метод использовать, но для сравнения с ваши собственные данные, а затем решить.
многие другие ответы здесь не учитывают символы юникода (например, öäüßîîûηыეமிᚉ ⠛ ). В этом случае вы можете использовать следующее:
есть странный класс символов в диапазоне \x80-\x9F (чуть выше 7-битного диапазона ASCII символов), которые технически управляют символами, но со временем были неправильно использованы для печати символов. Если у вас нет никаких проблем с этим, то вы можете использовать:
если вы хотите также ленточный канал, возврат каретки, вкладки, неразрывные пробелы и мягкие дефисы, вы можете использовать:
обратите внимание, что вы должны используйте одинарные кавычки для приведенных выше примеров.
если вы хотите удалить все, кроме основных символов ASCII для печати (все символы примера выше будут удалены), вы можете использовать:
вы можете использовать классы символов
начиная с PHP 5.2, у нас также есть доступ к filter_var, о котором я не видел никаких упоминаний, поэтому думал, что выброшу его там. Чтобы использовать filter_var для удаления непечатаемых символов 127, вы можете сделать:
фильтр ASCII символов ниже 32
фильтр ASCII символов выше 127
вы также можете html-кодировать низкие символы (новая строка, вкладка и т. д.) во время зачистки высокий:
есть также варианты для зачистки HTML, дезинфекции электронной почты и URL-адресов и т. д. Таким образом, много вариантов для дезинфекции (удаление данных) и даже проверки (возврат false, если он недействителен, а не молча зачистки).
однако по-прежнему существует проблема, что FILTER_FLAG_STRIP_LOW будет удалять новую строку и возврат каретки, которые для textarea являются полностью допустимыми символами. поэтому некоторые ответы регулярных выражений, я думаю, все еще необходимы время от времени, например, после просмотра этого потока, я планирую сделать это для textarea:
Это кажется более читаемым, чем ряд регулярных выражений, которые были удалены числовой диапазон.
Невидимые символы, скрывающие веб-шелл в зловредном коде на PHP

Вскоре мы обнаружили такую же схему использования и во вредоносных программах на PHP. В статье мы расскажем о том, что обнаружил аналитик вредоносного ПО Лиам СмитSmith, работая недавно над сайтом, содержащим множество загружаемых хакерами бэкдоров и веб-шеллов.
Подозрительный файл license.php
Один из найденных Лиамом файлов выглядел немного странно: system/license.php.
Как можно понять из названия, он содержит текст лицензионного соглашения, а именно GNU General Public License version 3.
Этот текст лицензии расположен внутри многострочного комментария PHP. Однако в строке 134 мы видим разрыв между двумя комментариями, содержащий исполняемый код на PHP.

Код на PHP внутри license.php
Сокрытие зловредного кода между блоками комментариев — это распространённый способ обфускации, используемый хакерами.
Анализ видимого зловредного кода
Чтобы понять, что конкретно делает зловредный код, мы проанализировали каждую конструкцию.
После этой последней точки с запятой визуально ничего не видно. Чтобы понять, что выполняется оставшейся частью файла, нам нужно проанализировать следующий раздел операторов зловреда.
Декодер разделителей
Тем не менее, мы получили отчёты о том, что по какой-то причине эти файлы с пустым именем всё равно можно найти на скомпрометированных сайтах.
Раскрытие сокрытой полезной нагрузки
Теперь, когда мы знаем, что это зловредное ПО ищет символы табуляции и пробелы после последней точки с запятой, можно найти и декодировать эту скрытую полезную нагрузку.
Как оказалось, в конце последней строки файла license.php содержится почти 300 килобайт невидимых символов табуляции и пробелов. Для сравнения: видимый текст лицензии составляет всего 30 КБ.
Эти невидимые символы можно обнаружить, проверив шестнадцатеричный код последней строки или выбрав в текстовом редакторе содержимое после последней ; (со включенным переносом строк).
Последняя строка license.php в шестнадцатеричном виде
Начало невидимого содержимого, выделенное в текстовом редакторе
Хотя эта картинка, как и похожая обфускация из описанного в ноябре зловреда на JavaScript, напоминает код Морзе, в данном примере не используются символы перевода строки (line feed, 0x0A). Это означает, что невидимое содержимое не создаёт огромное количество подозрительных пустых строк в конце файлов.
Использовав алгоритм декодирования разделителей (whitespace) из кода, мы получаем 74-килобайтный файл веб-шелла, предоставляющий хакерам инструменты для работы с файлами и базами данных на сервере, сбора персональной информации, инфицирования файлов и проведения брутфорс-атак. Кроме того, он может работать как консоль сервера или анонимайзер для сокрытия реального IP-адреса злоумышленников.
Декодированный из разделителей веб-шелл
Источник происхождения алгоритма
Как часто выясняется в наших расследованиях, многие используемые в зловредном ПО хитрости и алгоритмы создаются не хакерами. Большая часть кода уже существовала ранее и просто копируется с сайтов наподобие StackOverflow.
Поиск фрагмента кода этого декодера разделителей привёл к статье 2019 года на Хабре. Автор статьи поделился своим proof of concept обфускации PHP при помощи разделителей, вдохновившись статьёй об обфускации 2011 года, в которой рассказывалось о концепции кодирования при помощи только символов табуляции и пробелов.
Автор зловреда просто взял часть с декодером разделителей из этой статьи, не внеся никаких изменений, а затем добавил код для работы с дополнительным слоем обфускации и исполнения декодированной полезной нагрузки.
Аплоудер зловредного ПО
На скомпрометированных серверах довольно редко встречается только один тип бэкдора. Обычно их несколько, и каждый из них отвечает за конкретную задачу.
Например, файл с невинным названием license.php должен оставаться невидимым в течение долгого времени, обеспечивая доступ к скомпрометированному сайту даже после обнаружения и удаления всего остального зловредного ПО.
Файлы или код, которые злоумышленники изначально внедряют на сервер, чтобы инфицировать сайт — это другой тип бэкдора. Обычно он располагается в мелком файле в скомпрометированном окружении; такие бэкдоры позволяют злоумышленникам или исполнять произвольный код, или создавать определённые файлы. Они не должны быть особо скрытными или сильно обфусцированными — чтобы замести следы, хакеры часто удаляют их после применения.
Аплоудер зловредного ПО, создающий фальшивые файлы license.php
Заключение
Хотя сокрытие зловредного содержимого от невооружённого глаза кажется хорошей идеей, использованная в этом коде обфускация разделителями далека от идеала. Она содержит легко обнаруживаемый фрагмент PHP и его удаление приводит к невозможности использования невидимой полезной нагрузки. Ещё один недостаток такого подхода — огромный размер файла. Зловред увеличил размер файла в десять раз, из-за чего он стал гораздо более подозрительным.
Техники обфускации стандартно используются хакерами для сокрытия кода и утаивания зловредного поведения. Существуют сотни известных типов обфускации, а злоумышленники всегда ищут новые способы защиты от обнаружения.
К счастью для администраторов сайтов, для удаления зловредного ПО им необязательно декодировать его и чётко понимать принцип его работы. Для обнаружения нежелательных модификаций файлов достаточно простого ПО контроля целостности.
Если при изучении изменений вы не уверены, являются ли они зловредными, то самым безопасным будет откатиться к чистой версии — ведь у вас ведь есть резервная копия?
На правах рекламы
Серверы для разработчиков и не только! Недорогие VDS на базе новейших процессоров AMD EPYC и хранилища на основе NVMe дисков от Intel для размещения проектов любой сложности, создавайте собственную конфигурацию сервера в пару кликов!
Как с помощью PHP удалить символ – все способы реализации
Дата публикации: 2017-05-19

От автора: может, слов не выкинешь из песни. Но вот в PHP удалить символ проще простого. Сегодня этим и займемся.
Функциональный подход
Имеется в виду использование встроенных в ядро языка функций. Сначала используем str_replace(). Она принимает три аргумента: символ замены, заменяемый символ и исходную строку. Пример:

Бесплатный курс по PHP программированию
Освойте курс и узнайте, как создать динамичный сайт на PHP и MySQL с полного нуля, используя модель MVC
В курсе 39 уроков | 15 часов видео | исходники для каждого урока
Но это не единственная функция для изъятия «нежелательного» элемента из строки. Вот еще одна:

Здесь для удаления определенных частей текста применяем функцию substr(). В качестве параметров передаем ей первоначальную строку, положение, с которого нужно отсечь строку, и положение последнего знака возвращаемой подстроки.
Использование данной функции оправдано, если знаете очередность символа, который нужно изъять.
Вот еще одна функция, помогающая в решении проблемы. strstr() возвращает часть строки до или после переданного ей символа. Как от него избавиться:

Для этого в параметрах функции указываем true и получаем левую часть строки от символа, но уже без него.
Регулярки, потому что регулярно
Как всегда, господа, «на второе» у нас регулярные выражения. Их использование крайне удобно для решения некоторых «неудобных» ситуаций. К примеру, если нужно избавиться от повторяющихся знаков:
Здесь применяется функция для работы с регулярками preg_replace(). В переданной ей строке она ищет заданный символ и меняет его на другой. В приведенном выше примере таким образом мы избавились от нулей в тексте.
Бесплатный курс по PHP программированию
Освойте курс и узнайте, как создать динамичный сайт на PHP и MySQL с полного нуля, используя модель MVC
В курсе 39 уроков | 15 часов видео | исходники для каждого урока

Разработка веб-приложения на PHP
Создайте веб-приложение на PHP на примере приема платежей на сайте
Как убрать все управляющие символы из строки — история одной бурной оптимизации
 Получилось так, что мне довелось оптимизировать код кластерной задачи, которая входила в состав Большого Кластерного Алгоритма и занималась весьма простой вещью: входной поток из n полей нужно было в зависимости от содержимого полей переразложить в выходной поток из m полей и почти успокоиться. Почти — потому что внутри полей были строчки произвольного вида, которые нужно было «очистить» — провести простейшую, казалось бы, операцию удаления всех управляющих символов из строки.
Получилось так, что мне довелось оптимизировать код кластерной задачи, которая входила в состав Большого Кластерного Алгоритма и занималась весьма простой вещью: входной поток из n полей нужно было в зависимости от содержимого полей переразложить в выходной поток из m полей и почти успокоиться. Почти — потому что внутри полей были строчки произвольного вида, которые нужно было «очистить» — провести простейшую, казалось бы, операцию удаления всех управляющих символов из строки.
Оказалось, что эта операция совсем не такая «простейшая», как кажется, особенно если рассматривать её в современных языках с виртуальной машиной. Чуть ниже я покажу, как можно заменить решение в одну строчку на решение в пару десятков строчек, увеличив производительность алгоритма в
Я даже знаю, откуда взялась эта строчка — быстрый поиск в Google по фразе «java strip non-printable characters» выдает именно этот вариант. Итак, задача понятна, цели понятны, программистское самолюбие задето («как же так, неужели я не смогу разогнать эту несчастную строчку»), поехали!
Делаем на скорую руку простенькую обвязку, замеряющую время работы алгоритма, изолируем его от всего остального кода, генерируем тестовую входную строчку, которую будем прогонять миллионы раз через алгоритм и замеряем производительность. Получается, что первый вариант обрабатывает 517009 строчек в секунду. Делаем несколько замеров, понимаем, что точность наших измерений и экспериментов — порядка 2-3% — т.е. грубо говоря, на последние 4 цифры можно совсем не смотреть, а на пятую цифру с конца — смотреть, но не заглядываться. Т.е. результаты где-то между 500..540 тысячами.
Нет, не дает. Всё те же 520000±3%.
Вспоминаем, что в чудесном языке Java компилятор, виртуальная машина и stdlibs зачастую живут отдельной жизнью и скорее всего такую простейшую операцию не оптимизируют — несмотря на то, что миллионы раз повторяется одно и то же регулярное выражение, оно каждый раз компилируется заново. Подглядывание в документацию на String#replaceAll эту догадку подтверждает. Пытаемся вынести эту самую компиляцию за скобки:
Внезапно, вместо одной строчки — три, а производительность выросла до 640000±3% — не в разы, но внезапно +23% мы отыграли.
Недолго думаем, можно ли сделать лучше. Пробуем, что будет, если проходить по строке вручную в цикле, анализируя символ за символом (вытаскивая их через String#codePointAt), и сохраняя в другую строку. Подсознание автоматом подсказывает, что только не в строку, а в StringBuilder или StringBuffer. В нашем случае без разницы, что использовать — у нас параллелизацию делает кластер, запуская N независимых процессов параллельно. Быстрый взгляд на документацию показывает, что рекомендуют заранее инициализировать StringBuilder с некоей capacity — числом предполагаемых символов в результате. Нет причин не верить документации, так и сделаем — нам точно известно, что в результате у нас будет явно не больше, чем было в строчке изначально.
7 строчек вместо 1, зато уже 710000±3% строчек в секунду. Это уже +37% — больше трети.
Продолжаем думать дальше. Проскакивает простенькая мысль — что будет, если убрать работу с Unicode codepoints и перейти к использованию обычных Java’овских char? Потеряем возможность смотреть на всякие суррогаты, композиты и т.п. как на целое — но с точки зрения стриппинга — ничего плохого не будет. Пробуем:
Те же 7 строчек, изменение незначительное на первый взгляд, зато производительность внезапно подскакивает до 1052000±3%! Это уже круто — это чуть больше, чем в 2 раза относительно исходного (+103%).
Можно ли сделать еще быстрее? Можно! Посмотрим внутрь StringBuilder, внезапно увидим, что это отнюдь не какая-то дикая магия, уходящая глубоко в C-код JVM, а вполне себе решение на чистой Java. Внутри StringBuilder’а хранятся банально структуры данных, увязывающие цепочки символов через массивы char. Все эти структуры в нашем случае лежат без надобности — мы не собираемся вставлять что-то там в середину строки, раздвигать и т.п. Можно действительно все тупо сделать на массивах, практически C-way:
Строчек стало 10, зато производительность выросла еще вдвое: аж 2022000±3%! Это в 4 раза быстрее, чем оригинальный вариант с regexp’ом.
Таким образом, все банально: от многих вызовов charAt() можно уйти, заменив их одним String#getChars. Проверяем:
Очередное маленькое чудо происходит: 12 строчек, зато 2500000±3%, т.е. в 5 раз быстрее оригинала.
Как ни странно, дает аж 3100000±3% строчек в секунду, т.е. почти в 6 раз быстрее оригинала, и быстрее предыдущего лучшего варианта еще на 24%.
Основной выигрыш достигается за счет двух банальных, известных с C, но до сих пор вполне работающих конструкций: предпросчет длины строки в переменной length (экономия на вызовах String#length() — я почему-то наивно надеялся, что JVM это сделает за меня) и использование одного и того же массива oldChars одновременно для хранения и старой, и новой строчки (пользуясь тем, что из старой строчки нам всегда нужен j-тый символ, причем на момент чтения j-того символа всегда j
Как удалить лишние символы php
Помощь в написании контрольных, курсовых и дипломных работ здесь.
Как удалить лишние пробелы, переносы и экранировать символы в строке?
на вход приходит строка. нужно в любой приходящей строке удалять переносы на следующую строку.
Удалить лишние символы после парсинга
Добрый вечер! Уже киплю. Перепробовал уже с 10-ток всяких функций по работе со строками после.
Добавлено через 2 минуты
$number = str_replace(«-«,»!»,»?»,».», «», trim($_POST[‘name’]));
так не работает!
Добавлено через 46 секунд
$number = str_replace( «-«,»!»,»?»,».», «», trim($_POST[‘name’]));
Добавлено через 10 минут  прошу Ответьте
прошу Ответьте
Добавлено через 1 минуту
Я поставил на 5,6 и сработало вы не прецтавляете что это для меня огромное вам спасибо я вас обожаю и этот сайт вы самый крутой форум 
Помощь в написании контрольных, курсовых и дипломных работ здесь.
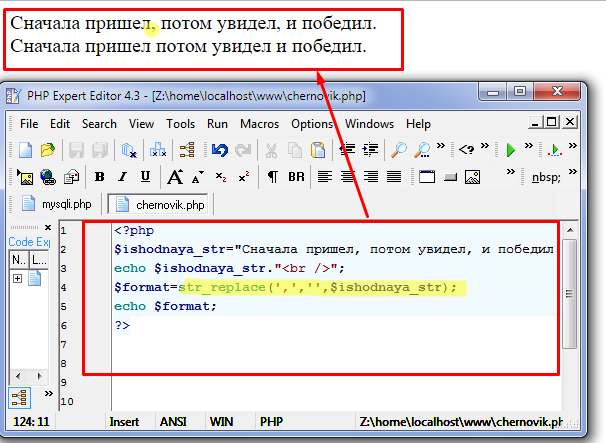
 На форме лишние символы
На форме лишние символы
Взял исходник, у «автора » работает без проблем. А у меня вид как на картинке. Да и в базу mysql не.
Лишние символы в json
Доброго времени суток! Столкнулся с проблемой одной, надеюсь поможете. Имеется php обработчик.
Лишние символы на странице
Здравствуйте! Уже несколько дней не могу решить проблему. Суть в чем: notepad++ при создании.
Добавляются лишние символы после md5
Привет форумчане. Такая проблема: Есть скрипт регистрации, в нём я принимаю логин и пароль.