mb_internal_encoding
(PHP 4 >= 4.0.6, PHP 5, PHP 7, PHP 8)
mb_internal_encoding — Установка/получение внутренней кодировки скрипта
Описание
Установка/получение внутренней кодировки скрипта.
Список параметров
Возвращаемые значения
Если аргумент encoding задан, то Возвращает true в случае успешного выполнения или false в случае возникновения ошибки. В этом случае не меняется кодировка символов для многобайтных регулярных выражений. Если аргумент encoding опущен, будет возвращено имя текущей внутренней кодировки.
Список изменений
Примеры
Пример #1 Пример использования mb_internal_encoding()
/* Установка внутренней кодировки в UTF-8 */
mb_internal_encoding ( «UTF-8» );
/* Вывод на экран текущей внутренней кодировки */
echo mb_internal_encoding ();
?>
Смотрите также
User Contributed Notes 7 notes
Especially when writing PHP scripts for use on different servers, it is a very good idea to explicitly set the internal encoding somewhere on top of every document served, e.g.
This, in combination with mysql-statement «SET NAMES ‘utf8′», will save a lot of debugging trouble.
Also, use the multi-byte string functions instead of the ones you may be used to, e.g. mb_strlen() instead of strlen(), etc.
header ( ‘Content-Type: text/html; charset=UTF-8’ );
mb_internal_encoding ( ‘UTF-8’ );
mb_http_output ( ‘UTF-8’ );
mb_http_input ( ‘UTF-8’ );
mb_regex_encoding ( ‘UTF-8’ );
Be aware that the strings in your source files must match the encoding you specify by mb_internal_encoding. It appears the Parser loads raw bytes from the file and refers to its internal encoding to determine their actual encoding.
To demonstrate, the following outputs as espected when the /source/ file is Latin-1 encoded:
( «iso-8859-1» );
mb_http_output ( «UTF-8» );
ob_start ( «mb_output_handler» );
Now, a typical use of mb_internal_encoding is shown as follows. Make the change to «utf-8» but leave the /source/ file encoding unchanged:
( «UTF-8» );
mb_http_output ( «UTF-8» );
ob_start ( «mb_output_handler» );
The output will just show the
tag and no text.
Save the file as UTF-8 encoding and then the results will be as expected.
PHP Кодировка страницы

Здравствуй уважаемый читатель блога LifeExample, кодировка веб страницы это очень интересный зверь, и за частую хищный для начинающих веб мастеров. Я уверен в том, что все новички сталкиваются с проблемой правильного отображения текста на страницах своего сайта. Ты дорогой читатель, наверное встречал в сети интернета ресурсы, на страницах которых отображался не читаемый текст, а кракозябры.
Кракозябрами в среде программирования веб сайтов принято называть символы не соответствующие тем, которые должны быть выведены на страницу. Например, на созданной вами странице должно отображаться приветствие: «Здравствуй читатель моего блога!», а на деле получаете непонятный набор закорючек «Р—РґСЂР°РІСЃС‚РІСѓР№ читатеРСЊ моего Р±РРѕРіР°!» – вот такие закорючки и есть злые КРАКОЗЯБРЫ.
В данной статье мы разберем эту проблему с ног до головы, чтобы больше не возвращаться к танцам с бубном вокруг нечитаемого текста.
И так, чтобы понять откуда появляются подобного рода иероглифы, нам нужно познакомиться с понятием кодировка страницы. Любой текст на компьютере представляется в виде набора байтов, в каждом из этих байтов определенным кодом — закодирован только один единственный символ. Так вот для того чтобы правильно расшифровать или раскодировать набор байтов и представить его в понятном человеку виде, браузеру нужно провести соответствие с одной из кодовых таблиц. Базовой кодировкой является ASCII кодировка, она содержит в себе коды 128 символов латинского алфавита и спец символов вроде скобок и решеток. Именно из ASCII появились первые русскосимвольные кодировки CP866 и KOI8-R, а из них вышла известная сегодняшним вебмастерам кодировка windows-1251. Не смотря на то, что все эти кодировки призваны для отображения русского текста, они все отличаются друг от друга кодами для одинаковых символов. Если текст писался в кодировке CP866, а браузер пытается раскодировать ее с помощью таблицы кодов windows-1251, то в результате мы получим не читаемые слова. Такое часто происходит при отправке сообщений через почтовый сервер.
Приведенные здесь названия кодировок далеко не все что существуют и используются в разных случаях, их намного больше чем вы думаете. С таким обилием кодовых таблиц образовалась проблема совместимости кодировок, и веб мастерам пришлось вставть на борьду с универсализацией кода, что занимало много времени и нервов. На сегодняшний день изобретена панацея для данной проблемы в виде универсальной кодировки utf-8, со временем она вытесняет используемые ранее кодовые таблицы символов, и сейчас уже не для кого не встает вопрос о том в какой кодировке лучше сохранять данные.
Много было сказано относительно эволюции кодировок, и постановке самой задачи, пришло время поговорить о практических моментах.
Существует четыре места на кухне программирования сайта, которые требуют соблюдения единого стандатра кодирования текста.
Во всех этих составляющих сайта, должна использоваться единая кодировка, какая – решать вам, но я рекомендую utf-8, всетаки она универсальная)
И так теперь подробнее рассмотрим, что нужно сделать для того, чтобы привести к одной кодировке всеперечисленые составляющие.
Кодировки скриптов (шаг 1)
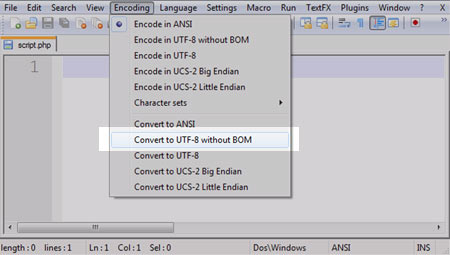
Выбираем именно Convert to UTF-8 without BOM, а не просто Convert to UTF‑8. Приставка without BOM означает то что в первых двух байтах файла будет зашифрована специальная информация о параметре кодировки, в скриптах нам не нужна никакая лишняя информация. В большенстве случаев сохранение с BOM не окажется криминальным, но когданить один из скриптов откажется правильно работать и одной из причин может отазаться именно информация заключенная в первых байтах файла.
Кодировка таблиц MySQL. (шаг 2)
Для того, чтобы узнать какие кодировки используются в ваше MySQL базе, воспользуемся интерфейсом phpMyAdmin. В разделе SQL напишем запрос:
Выглядеть это должно вот так:
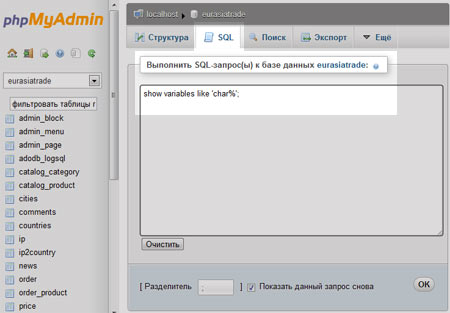
Жмем ОК и получаем информацию о кодировках таблицы
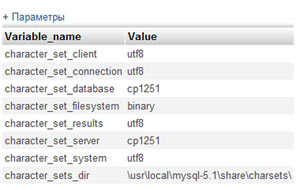
Значения на против character_set_client и character_set_results должны совпадать, так как эти параметры отвечают за кодировку, в которой данные поступают в базу и за кодировку в которой данные берутся из базы.
Если они у вас различаются, то нужно в PHP коде в ручную установить нужную кодировку. Делается это вот такой строчкой:
После этого три переменные character_set_client, character_set_connection и character_set_results примут значение utf8.
Подробнее о том как с помощью PHP работать с базой данных можно прочесть в статье PHP работа с базой данных (Часть 1-3).
Кодировка самой HTML страницы. (Шаг 3)
Теперь данные взятые с базы и данные обрабатываемые в php скрипте, будут совпадать по кодировке, и выводиться в понятном для человека тексте. Но это еще не все, нужно указать кодировку в разделе для мета тегов:
Либо в cкрипте настроек php командой:
Если кодировка HTML будет задана сразу двумя способами, то приоритетным будет задание кодировки из php скрипта.
Также можно глобально задать правило кодировки HTML в файле .htaccess добавив в него строку:
Локаль используемая браузером пользователя. (Шаг 4)
Еще одна важная деталь при корректном отображении текста это установка локали:
При установки такой локали, пердставители других стран использующие другую кодовую страницу в своей операционной системе, будут видеть русский текст.
Мы рассмотрели основные моменты возникновения противоречий в кодировках веб страницы, подведем итоги. Для того чтобы ваш рускоязычный сайт был всегда доступен для чтения, необходимо прописать в PHP скрипте настроек такие строки:
Если у тебя дорогой читатель остались вопросы по данной статье о PHP кодировке страниц, то смело задавай их в комментариях.
Читайте также похожие статьи:

Чтобы не пропустить публикацию следующей статьи подписывайтесь на рассылку по E-mail или RSS ленту блога.
Определение кодировки текста в PHP — обзор существующих решений плюс еще один велосипед
Столкнулся с задачей — автоопределение кодировки страницы/текста/чего угодно. Задача не нова, и велосипедов понапридумано уже много. В статье небольшой обзор найденного в сети — плюс предложение своего, как мне кажется, достойного решения.
Если кратко — он не работает.
Давайте смотреть:
Как видим, на выходе — полная каша. Что мы делаем, когда непонятно почему так себя ведет функция? Правильно, гуглим. Нашел замечательный ответ.
Чтобы окончательно развеять все надежды на использование mb_detect_encoding(), надо залезть в исходники расширения mbstring. Итак, закатали рукава, поехали:
Постить полный текст метода не буду, чтобы не засорять статью лишними исходниками. Кому это интересно посмотрят сами. Нас истересует строка под номером 593, где собственно и происходит проверка того, подходит ли символ под кодировку:
Вот основные фильтры для однобайтовой кириллицы:
Windows-1251 (оригинальные комментарии сохранены)
ISO-8859-5 (тут вообще все весело)
Как видим, ISO-8859-5 всегда возвращает TRUE (чтобы вернуть FALSE, нужно выставить filter->flag = 1).
Когда посмотрели фильтры, все встало на свои места. CP1251 от KOI8-R не отличить никак. ISO-8859-5 вообще если есть в списке кодировок — будет всегда детектиться как верная.
В общем, fail. Оно и понятно — только по кодам символов нельзя в общем случае узнать кодировку, так как эти коды пересекаются в разных кодировках.
2. Что выдает гугл
А гугл выдает всякие убожества. Даже не буду постить сюда исходники, сами посмотрите, если захотите (уберите пробел после http://, не знаю я как показать текст не ссылкой):
http:// deer.org.ua/2009/10/06/1/
http:// php.su/forum/topic.php?forum=1&topic=1346
3. Поиск по хабру
2) на мой взгляд, очень интересное решение: habrahabr.ru/blogs/php/27378/#comment_1399654
Минусы и плюсы в комменте по ссылке. Лично я считаю, что только для детекта кодировки это решение избыточно — слишком мощно получается. Определение кодировки в нем — как побочный эффект ).
4. Собственно, мое решение
Идея возникла во время просмотра второй ссылки из прошлого раздела. Идея следующая: берем большой русский текст, замеряем частоты разных букв, по этим частотам детектим кодировку. Забегая вперед, сразу скажу — будут проблемы с большими и маленькими буквами. Поэтому выкладываю примеры частот букв (назовем это — «спектр») как с учетом регистра, так и без (во втором случае к маленькой букве добавлял еще большую с такой же частотой, а большие все удалял). В этих «спектрах» вырезаны все буквы, имеющие частоты меньше 0,001 и пробел. Вот, что у меня получилось после обработки «Войны и Мира»:
Спектры в разных кодировках (ключи массива — коды соответствующих символов в соответствующей кодировке):
Далее. Берем текст неизвестной кодировки, для каждой проверяемой кодировки находим частоту текущего символа и прибавляем к «рейтингу» этой кодировки. Кодировка с бОльшим рейтингом и есть, скорее всего, кодировка текста.
Результаты
У-упс! Полная каша. А потому что большие буквы в CP1251 обычно соответствуют маленьким в KOI8-R. А маленькие буквы используются в свою очередь намного чаще, чем большие. Вот и определяем строку капсом в CP1251 как KOI8-R.
Пробуем делать без учета регистра («спектры» case insensitive)
Как видим, верная кодировка стабильно лидирует и с регистрозависимыми «спектрами» (если строка содержит небольшое количество заглавных букв), и с регистронезависимыми. Во втором случае, с регистронезависимыми, лидирует не так уверенно, конечно, но вполне стабильно даже на маленьких строках. Можно поиграться еще с весами букв — сделать их нелинейными относительно частоты, например.
5. Заключение
В топике не расмотрена работа с UTF-8 — тут никакий принципиальной разницы нету, разве что получение кодов символов и разбиение строки на символы будет несколько длиннее/сложнее.
Эти идеи можно распространить не только на кириллические кодировки, конечно — вопрос только в «спектрах» соответствующих языков/кодировок.
P.S. Если будет очень нужно/интересно — потом выложу второй частью полностью работающую библиотеку на GitHub. Хотя я считаю, что данных в посте вполне достаточно для быстрого написания такой библиотеки и самому под свои нужды — «спектр» для русского языка выложен, его можно без труда перенести на все нужные кодировки.
UPDATED
В комментариях проскочила замечательная функция, ссылку на которую я опубликовал под графом «убожество». Может быть погорячился со словами, но уж как опубликовал, так опубликовал — редактировать такие вещи не привык. Чтобы не быть голословным, давайте разберемся, работает ли она на 100%, как об этом говорит предполагаемый автор.
1) будут ли ошибки при «нормальной» работе этой функции? Предположим, что контент у нас на 100% валидный.
ответ: да, будут.
2) определит ли она что-нибудь кроме UTF-8 и не-UTF-8?
ответ: нет, не определит.
Решение проблем неправильной кодировкой веб-страницы
При неправильной кодировке весь сайт или его часть отображаются в виде «кряпозяблов», т.е. непонятных символов, делающих текст нечитаемым. Такая ситуация может возникнуть при неверной настройке кодировки веб-сервера или при отсутствии настроек. Рассмотрим возможные варианты и способы устранения проблем
Неправильная кодировка HTML страниц
Создадим тестовый файлик:
Скопируем в него следующий HTML код, в котором отсутствует указание кодировки и посмотрим, какие проблемы могут с ним возникнуть и как их решить:
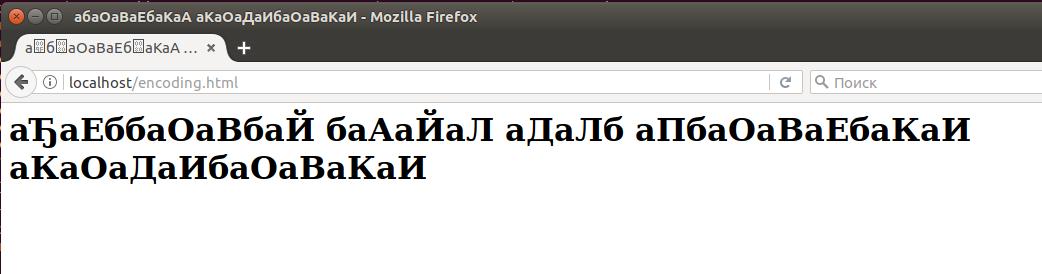
Как можно видеть, кодировка браузером определена неправильно:
Имеется несколько способов исправить эту ситуацию. Начнём с самого простого – явно указать кодировку для веб-страницы. Это делается метатегом, который должен быть расположен внутри тэга head:
Добавим эту строку к нашему тестовому файлику, чтобы получилось так:
Как мы можем убедиться на следующем скриншоте, проблема решена:
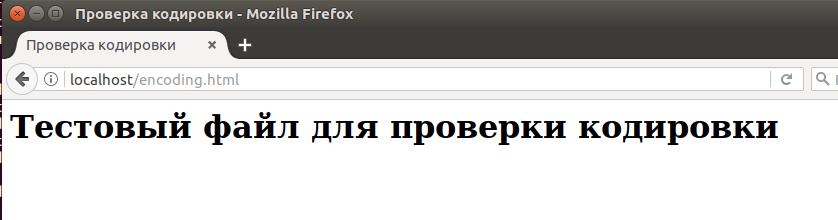
Если кодировка вашего файла отличается от UTF-8, то вместо неё поставьте windows-1251 или ту, которая соответствует кодировке веб-страницы. Чтобы научиться определять кодировку файлов, посмотрите эту инструкцию.
Это был самый простой способ исправления проблемы с кодировкой – без изменения настроек сервера.
Вернём наш тестовый файл в исходное состояние и продолжим изучение способов указания кодировки.
Если файлы .htaccess включены настройками Apache, то эти файлы можно использовать чтобы указывать кодировку отправляемых веб-сервером страниц. Чтобы включить поддержку файлов .htaccess в конфигурационном файле Apache ( /etc/apache2/apache2.conf ) найдите группу строк
После этого сервер нужно перезапустить.
Файл .htaccess должен быть размещён в той же директории, что и сайт. Мой сайт размещён в корневой директории веб-сервера. Если у вас также, то теперь в папке /var/www/html/ создайте файл .htaccess и добавьте в него директиву AddDefaultCharset после которой укажите желаемую кодировку. Примеры
Можно указать кодировку, которая будет применена только к файлам определённого формата:
Набор файлов может быть любым, например:
Следующий вариант является альтернативным и также позволяет устанавливать кодировку для файлов определённого типа, для него нужно, чтобы был включён mod_headers:
Ещё один вариант, который также можно использовать в файле .htaccess для установки кодировки UTF-8:
Если сайт на PHP, то дополнительно может понадобиться продублировать кодировку с php_value default_charset:
Как установить UTF-8 кодировку в PHP
В PHP скрипте для установки кодировки используется header, например:
Обычно вместе с кодировкой также указывают тип содержимого (в примере вариант для HTML страницы):
Ещё один вариант для RSS ленты:
Помните, что функция header должна быть вызвана перед любым выводом в браузер. В противном случае (если вывод в браузер уже был сделан), то уже были отправлены и заголовки. Очевидно, что в этом случае их уже невозможно поменять. Если в браузер было выведено сообщение об ошибке, то заголовки также уже были отправлены и использование header вызовет ошибку. Для проверки, были ли уже отправлены заголовки, используйте headers_sent.
Описанный способ работает только когда PHP скрипт полностью генерирует содержимое страницы. Статические страницы (такие как html) вы должны сохранять в кодировке utf-8. Большинство веб серверов обратят внимание на кодировку файла и добавят соответствующий заголовок. На самом деле, сохранение PHP файла в кодировке utf-8 приведёт к такому же результату.
Неправильная кодировка результатов из базы данных MySQL
Если ваш сайт состоит из статической части (шаблон) и динамической, которая формируется из данных, получаемых из базы данных, то может возникнуть ситуация, когда часть сайта имеет правильную кодировку, а другая часть сайта имеет неправильную. В этом случае бесполезно менять настройки веб-сервера – поскольку всё равно часть страницы будет иметь неправильную кодировку.
Нужно начать с определения кодировки ваших таблиц. Можно посмотреть в phpMyAdmin:

Обратите внимание на столбец «Сравнение», запись «utf8_unicode_ci» означает, что используется кодировка UTF-8.
Можно подключиться к СУБД MySQL и проверить кодировку таблиц без phpMyAdmin. Для этого:
Если вы забыли имя базы данных, то выполните команду:
Предположим, я хочу посмотреть кодировку для таблиц в базе данных information_schema
Если вы забыли имя таблиц, выполните:
Далее выполните команду, в которой имя_таблицы замените на настоящее имя таблицы:
Вы увидите примерно следующее:

Смотрите столбец Collation. В моём случае там utf8_general_ci, это, как и utf8_unicode_ci, кодировка UTF-8. Кстати, если вы не знаете в чём разница между кодировками utf8_general_ci, utf8_unicode_ci, utf8mb4_general_ci, utf8mb4_unicode_ci, а также какую кодировку выбрать для базы данных MySQL, то посмотрите эту статью.
Теперь, когда мы узнали кодировку (в моём случае это UTF-8), то при каждом подключении к СУБД MySQL нужно выполнять последовательно запросы:
В PHP это можно сделать примерно так:
Обратите внимание, что UTF8 вам нужно заменить на ту кодировку, которая используется для ваших таблиц.
Изменение кодировки файлов
Если вы решили пойти другим путём и вместо установки новой кодировки изменить кодировку ваших файлов, то посмотрите статью «Как конвертировать файлы в кодировку UTF-8 в Linux». В ней рассказано, как узнать текущую кодировку файлов и как конвертировать файлы в любую кодировку (не только UTF-8).
Как узнать, какую кодировку отправляет сервер
Если вы хотите узнать, какие настройки кодировки имеет веб-сервер (какую кодировку передаёт в заголовках), то воспользуйтесь следующей командой:
В ней вместо URL вставьте реальный адрес проверяемого сайта. Если сайт использует HTTPS, то укажите адрес сайта вместе с протоколом, например

Какую кодировку выбрать для веб-сайта
Рекомендуется выбрать кодировку UTF-8. Это более универсальная кодировка, практически, она стала стандартом. У вас не будет проблем с отображением необычных символов и букв из других алфавитов.
utf8_encode
(PHP 4, PHP 5, PHP 7, PHP 8)
utf8_encode — Кодирует строку ISO-8859-1 в кодировке UTF-8
Описание
Эта функция конвертирует строку string из кодировки ISO-8859-1 в UTF-8
Список параметров
Возвращаемые значения
Список изменений
| Версия | Описание |
|---|---|
| 7.2.0 | Функция была перенесена в ядро PHP, таким образом отменив требование модуля XML для использования этой функции. |
Смотрите также
User Contributed Notes 23 notes
Please note that utf8_encode only converts a string encoded in ISO-8859-1 to UTF-8. A more appropriate name for it would be «iso88591_to_utf8». If your text is not encoded in ISO-8859-1, you do not need this function. If your text is already in UTF-8, you do not need this function. In fact, applying this function to text that is not encoded in ISO-8859-1 will most likely simply garble that text.
If you need to convert text from any encoding to any other encoding, look at iconv() instead.
Here’s some code that addresses the issue that Steven describes in the previous comment;
/* This structure encodes the difference between ISO-8859-1 and Windows-1252,
as a map from the UTF-8 encoding of some ISO-8859-1 control characters to
the UTF-8 encoding of the non-control characters that Windows-1252 places
at the equivalent code points. */
Walk through nested arrays/objects and utf8 encode all strings.
If you need a function which converts a string array into a utf8 encoded string array then this function might be useful for you:
My version of utf8_encode_deep,
In case you need one that returns a value without changing the original.
I tried a lot of things, but this seems to be the final fail save method to convert any string to proper UTF-8.
If your string to be converted to utf-8 is something other than iso-8859-1 (such as iso-8859-2 (Polish/Croatian)), you should use recode_string() or iconv() instead rather than trying to devise complex str_replace statements.
If you are looking for a function to replace special characters with the hex-utf-8 value (e.g. für Webservice-Security/WSS4J compliancy) you might use this:
$textstart = «Größe»;
$utf8 =»;
$max = strlen($txt);
I was searching for a function similar to Javascript’s unescape(). In most cases it is OK to use url_decode() function but not if you’ve got UTF characters in the strings. They are converted into %uXXXX entities that url_decode() cannot handle.
I googled the net and found a function which actualy converts these entities into HTML entities (&#xxx;) that your browser can show correctly. If you’re OK with that, the function can be found here: http://pure-essence.net/stuff/code/utf8RawUrlDecode.phps
But it was not OK with me because I needed a string in my charset to make some comparations and other stuff. So I have modified the above function and in conjuction with code2utf() function mentioned in some other note here, I have managed to achieve my goal:
// Validate Unicode UTF-8 Version 4
// This function takes as reference the table 3.6 found at http://www.unicode.org/versions/Unicode4.0.0/ch03.pdf
// It also flags overlong bytes as error
This function may be useful do encode array keys and values [and checks first to see if it’s already in UTF format]:
[NOTE BY danbrown AT php DOT net: Original function written by (cmyk777 AT gmail DOT com) on 28-JAN-09.]
Avoiding use of preg_match to detect if utf8_encode is needed:
I recommend using this alternative for every language:
Don’t forget to set all your pages to «utf-8» encoding, otherwise just use HTML entities.
This function I use convert Thai font (iso-8859-11) to UTF-8. For my case, It work properly. Please try to use this function if you have a problem to convert charset iso-8859-11 to UTF-8.
$iso8859_11 = array(
«\xa1» => «\xe0\xb8\x81»,
«\xa2» => «\xe0\xb8\x82»,
«\xa3» => «\xe0\xb8\x83»,
«\xa4» => «\xe0\xb8\x84»,
«\xa5» => «\xe0\xb8\x85»,
«\xa6» => «\xe0\xb8\x86»,
«\xa7» => «\xe0\xb8\x87»,
«\xa8» => «\xe0\xb8\x88»,
«\xa9» => «\xe0\xb8\x89»,
«\xaa» => «\xe0\xb8\x8a»,
«\xab» => «\xe0\xb8\x8b»,
«\xac» => «\xe0\xb8\x8c»,
«\xad» => «\xe0\xb8\x8d»,
«\xae» => «\xe0\xb8\x8e»,
«\xaf» => «\xe0\xb8\x8f»,
«\xb0» => «\xe0\xb8\x90»,
«\xb1» => «\xe0\xb8\x91»,
«\xb2» => «\xe0\xb8\x92»,
«\xb3» => «\xe0\xb8\x93»,
«\xb4» => «\xe0\xb8\x94»,
«\xb5» => «\xe0\xb8\x95»,
«\xb6» => «\xe0\xb8\x96»,
«\xb7» => «\xe0\xb8\x97»,
«\xb8» => «\xe0\xb8\x98»,
«\xb9» => «\xe0\xb8\x99»,
«\xba» => «\xe0\xb8\x9a»,
«\xbb» => «\xe0\xb8\x9b»,
«\xbc» => «\xe0\xb8\x9c»,
«\xbd» => «\xe0\xb8\x9d»,
«\xbe» => «\xe0\xb8\x9e»,
«\xbf» => «\xe0\xb8\x9f»,
«\xc0» => «\xe0\xb8\xa0»,
«\xc1» => «\xe0\xb8\xa1»,
«\xc2» => «\xe0\xb8\xa2»,
«\xc3» => «\xe0\xb8\xa3»,
«\xc4» => «\xe0\xb8\xa4»,
«\xc5» => «\xe0\xb8\xa5»,
«\xc6» => «\xe0\xb8\xa6»,
«\xc7» => «\xe0\xb8\xa7»,
«\xc8» => «\xe0\xb8\xa8»,
«\xc9» => «\xe0\xb8\xa9»,
«\xca» => «\xe0\xb8\xaa»,
«\xcb» => «\xe0\xb8\xab»,
«\xcc» => «\xe0\xb8\xac»,
«\xcd» => «\xe0\xb8\xad»,
«\xce» => «\xe0\xb8\xae»,
«\xcf» => «\xe0\xb8\xaf»,
«\xd0» => «\xe0\xb8\xb0»,
«\xd1» => «\xe0\xb8\xb1»,
«\xd2» => «\xe0\xb8\xb2»,
«\xd3» => «\xe0\xb8\xb3»,
«\xd4» => «\xe0\xb8\xb4»,
«\xd5» => «\xe0\xb8\xb5»,
«\xd6» => «\xe0\xb8\xb6»,
«\xd7» => «\xe0\xb8\xb7»,
«\xd8» => «\xe0\xb8\xb8»,
«\xd9» => «\xe0\xb8\xb9»,
«\xda» => «\xe0\xb8\xba»,
«\xdf» => «\xe0\xb8\xbf»,
«\xe0» => «\xe0\xb9\x80»,
«\xe1» => «\xe0\xb9\x81»,
«\xe2» => «\xe0\xb9\x82»,
«\xe3» => «\xe0\xb9\x83»,
«\xe4» => «\xe0\xb9\x84»,
«\xe5» => «\xe0\xb9\x85»,
«\xe6» => «\xe0\xb9\x86»,
«\xe7» => «\xe0\xb9\x87»,
«\xe8» => «\xe0\xb9\x88»,
«\xe9» => «\xe0\xb9\x89»,
«\xea» => «\xe0\xb9\x8a»,
«\xeb» => «\xe0\xb9\x8b»,
«\xec» => «\xe0\xb9\x8c»,
«\xed» => «\xe0\xb9\x8d»,
«\xee» => «\xe0\xb9\x8e»,
«\xef» => «\xe0\xb9\x8f»,
«\xf0» => «\xe0\xb9\x90»,
«\xf1» => «\xe0\xb9\x91»,
«\xf2» => «\xe0\xb9\x92»,
«\xf3» => «\xe0\xb9\x93»,
«\xf4» => «\xe0\xb9\x94»,
«\xf5» => «\xe0\xb9\x95»,
«\xf6» => «\xe0\xb9\x96»,
«\xf7» => «\xe0\xb9\x97»,
«\xf8» => «\xe0\xb9\x98»,
«\xf9» => «\xe0\xb9\x99»,
«\xfa» => «\xe0\xb9\x9a»,
«\xfb» => «\xe0\xb9\x9b»
);
// Reads a file story.txt ascii (as typed on keyboard)
// converts it to Georgian character using utf8 encoding
// if I am correct(?) just as it should be when typed on Georgian computer
// it outputs it as an html file
//
// http://www.comweb.nl/keys_to_georgian.html
// http://www.comweb.nl/keys_to_georgian.php
// http://www.comweb.nl/story.txt
keys to unicode code
// this meta tag is needed
// note the sylfean font seems to be standard installed on Windows XP
// It supports Georgian
Re the previous post about converting GB2312 code to Unicode code which displayed the following function:
In the original function, the first latin chacter was dropped and it was not converting the first non-latin character after the latin text (everything was shifted one character too far to the right). Reversing those two lines makes it work correctly in every example I have tried.
Also, the source of the gb2312.txt file needed for this to work has changed. You can find it a couple places:
Someday they might be hardcoded into PHP.
*/
The following Perl regular expression tests if a string is well-formed Unicode UTF-8 (Broken up after each | since long lines are not permitted here. Please join as a single line, no spaces, before use.):