Обучение с подкреплением на языке Python

В последней публикации уходящего года мы хотели упомянуть о Reinforcement Learning — теме, книгу на которую мы уже переводим.
Посудите сами: нашлась элементарная статья с Medium, в которой изложен контекст проблемы, описан простейший алгоритм с реализацией на Python. В статье есть несколько гифок. А мотивация, вознаграждение и выбор правильной стратегии на пути к успеху — это вещи, которые исключительно пригодятся в наступающем году каждому из нас.
Приятного чтения!
Обучение с подкреплением – это разновидность машинного обучения, при котором агент учится действовать в окружающей среде, выполняя действия и тем самым нарабатывая интуицию, после чего наблюдает результаты своих действий. В этой статье я расскажу, как понять и сформулировать задачу на обучение с подкреплением, а затем решить ее на Python.
В последнее время мы уже привыкли к тому, что компьютеры играют в игры против человека – либо как боты в многопользовательских играх, либо как соперники в играх «один на один»: скажем, в Dota2, PUB-G, Mario. Исследовательская компания Deepmind наделала шороху в новостях, когда в 2016 году их программа AlphaGo в 2016 году одолела чемпиона Южной Кореи по го. Если вы – заядлый геймер, то могли слышать о пятерке матчей Dota 2 OpenAI Five, где машины сражались против людей и в нескольких матчах одолели лучших игроков в Dota2. (Если вас интересуют подробности, здесь подробно проанализирован алгоритм и рассмотрено, как играли машины).

Последняя версия OpenAI Five берет Roshan.
Итак, начнем с центрального вопроса. Зачем нам требуется обучение с подкреплением? Используется ли оно только в играх, либо применимо в реалистичных сценариях для решения прикладных задач? Если вы впервые читаете про обучение с подкреплением, то просто не можете вообразить себе ответ на эти вопросы. Ведь обучение с подкреплением — одна из самых широко используемых и бурно развивающихся технологий в сфере искусственного интеллекта.
Вот ряд предметных областей, в которых особенно востребованы системы по обучению с подкреплением:
Итак, как же сформировался сам феномен обучения с подкреплением, когда у нас в распоряжении такое множество методов машинного и глубокого обучения? «Его изобрели Рич Саттон и Эндрю Барто, научный руководитель Рича, помогавший ему готовить PhD». Парадигма впервые оформилась в 1980-е и тогда была архаична. Впоследствии Рич верил, что у нее большое будущее, и она в конце концов получит признание.
Обучение с подкреплением поддерживает автоматизацию в той среде, где оно внедрено. Примерно также действуют и машинное, и глубокое обучение – стратегически они устроены иначе, но обе парадигмы поддерживают автоматизацию. Итак, почему же возникло обучение с подкреплением?
Оно очень напоминает естественный процесс обучения, при котором процесс/модель действует и получает обратную связь о том, как ей удается справляться с задачей: хорошо и нет.
Машинное и глубокое обучение – также варианты обучения, однако, они в большей степени заточены под выявление закономерностей в имеющихся данных. В обучении с подкреплением, с другой стороны, такой опыт приобретается методом проб и ошибок; система постепенно находит правильные варианты действий или глобальный оптимум. Серьезное дополнительное преимущество обучения с подкреплением заключается в том, что в данном случае не требуется предоставлять обширного набора учебных данных, как при обучении с учителем. Достаточно будет нескольких мелких фрагментов.
Понятие об обучении с подкреплением
Представьте, что учите ваших кошек новым фокусам; но, к сожалению, кошки не понимают человеческого языка, поэтому вы не можете взять и рассказать им, во что собираетесь с ними играть. Поэтому вы будете действовать иначе: имитировать ситуацию, а кошка в ответ будет пытаться реагировать тем или иным способом. Если кошка отреагировала так, как вы хотели, то вы наливаете ей молока. Понимаете, что будет дальше? Вновь оказавшись в аналогичной ситуации, кошка вновь выполнит желаемое вами действие, и с еще большим энтузиазмом, рассчитывая, что ее покормят еще лучше. Так происходит обучение на положительном примере; но, если пытаться «воспитывать» кошку отрицательными стимулами, например, строго смотреть на нее и хмуриться, она обычно не обучается на таких ситуациях.
Схожим образом работает и обучение с подкреплением. Мы сообщаем машине некоторый ввод и действия, а затем вознаграждаем машину в зависимости от вывода. Наша конечная цель – максимизация вознаграждения. Теперь давайте рассмотрим, как переформулировать изложенную выше проблему в терминах обучения с подкреплением.
Знакомство с терминологией обучения с подкреплением
Агент и Среда играют ключевые роли в алгоритме обучения с подкреплением. Среда – это тот мир, в котором приходится выживать Агенту. Кроме того, Агент получает от Среды подкрепляющие сигналы (вознаграждение): это число, характеризующее, насколько хорошим или плохим можно считать текущее состояние мира. Цель Агента — максимизировать совокупное вознаграждение, так называемый «выигрыш». Прежде чем написать наши первые алгоритмы на обучение с подкреплением, необходимо разобраться с нижеизложенной терминологией.
Теперь, познакомившись с терминологией обучения с подкреплением, давайте решим задачу, воспользовавшись соответствующими алгоритмами. Перед этим нужно понять, как сформулировать такую задачу, а при решении этой задачи опираться на терминологию обучения с подкреплением.
Решение задачи такси
Итак, переходим к решению задачи с применением подкрепляющих алгоритмов.
Допустим, у нас есть зона для обучения беспилотного такси, которое мы обучаем доставлять пассажиров на парковку в четыре различные точки ( R,G,Y,B ). Перед этим нужно понять и задать среду, в которой начнем программировать на Python. Если вы только начинаете осваивать Python, рекомендую вам эту статью.
Среду для решения задачи с такси можно настроить при помощи Gym от компании OpenAI – это одна из самых популярных библиотек для решения задач на обучение с подкреплением. Хорошо, прежде чем использовать gym, ее нужно установить на вашей машине, а для этого удобен менеджер пакетов Python под названием pip. Ниже приведена установочная команда.
“Имеем 4 местоположения (обозначенных разными буквами); наша задача – подхватить пассажира в одной точке и высадить его в другой. Получаем +20 очков за успешную высадку пассажира и теряем 1 очко за каждый шаг, затраченный на это. Также предусмотрен штраф 10 очков за каждую непредусмотренную посадку и высадку пассажира.” (Источник: gym.openai.com/envs/Taxi-v2)
Вот какой вывод мы увидим в нашей консоли:
Отлично, env – это сердце OpenAi Gym, представляет собой унифицированный интерфейс среды. Далее приведены методы env, которые нам весьма пригодятся:
env.reset : сбрасывает окружающую среду и возвращает случайное исходное состояние.
env.step(action) : Продвигает развитие окружающей среды на один шаг во времени.
env.step(action) : возвращает следующие переменные
В среде есть 4 точки, в которых допускается высадка пассажиров: это: R, G, Y, B или [(0,0), (0,4), (4,0), (4,3)] в координатах (по горизонтали; по вертикали), если бы можно было интерпретировать вышеуказанную среду в декартовых координатах. Если также учесть еще одно (1) состояние пассажира: внутри такси, то можно взять все комбинации локаций пассажиров и их мест назначения, чтобы подсчитать общее количество состояний в нашей среде для обучения такси: имеем четыре (4) места назначения и пять (4+1) локаций пассажиров.
Итак, в нашей среде для такси насчитывается 5×5×5×4=500 возможных состояний. Агент имеет дело с одним из 500 состояний и предпринимает действие. В нашем случае варианты действий таковы: перемещение в том или ином направлении, либо решение подобрать/высадить пассажира. Иными словами, у нас в распоряжении шесть возможных действий:
pickup, drop, north, east, south, west (Четыре последних значения – это направления, в которых может двигаться такси.)
Это пространство action space : совокупность всех действий, которые наш агент может предпринять в заданном состоянии.
Поскольку в эту матрицу записаны абсолютно все состояния, можно просмотреть заданные по умолчанию значения вознаграждений, присвоенные тому состоянию, что мы выбрали для иллюстрации:
Давайте напишем код для решения этой задачи без обучения с подкреплением.
Поскольку у нас есть P-таблица с заданными по умолчанию значениями вознаграждения для каждого состояния, можем попытаться организовать навигацию нашего такси просто на основе этой таблицы.
Создаем бесконечный цикл, проматывающийся до тех пор, пока пассажир не попадет в место назначения (один эпизод), либо, иными словами, пока показатель вознаграждения не достигнет 20. Метод env.action_space.sample() автоматически выбирает случайное действие из множества всех доступных действий. Рассмотрим, что происходит:
Задача решена, но не оптимизирована, либо этот алгоритм будет работать не во всех случаях. Нам нужен подходящий взаимодействующий агент, чтобы количество итераций, затрачиваемых машиной/алгоритмом на решение задачи оставалось минимальным. Здесь нам поможет алгоритм Q-обучения, реализацию которого мы рассмотрим в следующем разделе.
Знакомство с Q-обучением
Ниже представлен наиболее востребованный и один из самых простых алгоритмов на обучение с подкреплением. Среда вознаграждает агента за постепенное обучение и за то, что в конкретном состоянии он совершает наиболее оптимальный шаг. В реализации, рассмотренной выше, у нас была таблица вознаграждений «P», по которой будет учиться наш агент. Опираясь на таблицу вознаграждений, он выбирает следующее действие в зависимости от того, насколько оно полезно, а затем обновляет еще одну величину, именуемую Q-значением. В результате создается новая таблица, называемая Q-таблица, отображаемая на комбинацию (Состояние, Действие). Если Q-значения оказываются лучше, то мы получаем более оптимизированные вознаграждения.
Например, если такси оказывается в состоянии, где пассажир оказывается в той же точке, что и такси, исключительно вероятно, что Q-значение для действия «подобрать» выше, чем для других действий, например, «высадить пассажира» или «ехать на север».
Q-величины инициализируются со случайными значениями, и по мере того, как агент взаимодействует со средой и получает различные вознаграждения, совершая те или иные действия, Q-значения обновляются в соответствии со следующим уравнением:
Здесь возникает вопрос: как инициализировать Q-значения и как рассчитывать их. По мере выполнения действий Q-значения выполняются в данном уравнении.
Здесь Альфа и Гамма – параметры алгоритма на Q-обучение. Альфа – это темп обучения, а гамма – дисконтирующий множитель. Оба значения могут быть в диапазоне от 0 до 1 и иногда равны единице. Гамма может быть равна нулю, а альфа – не может, поскольку значение потерь при обновлении должно компенсироваться (темп обучения — положителен). Альфа-значение здесь такое же, как и при обучении с учителем. Гамма определяет, какую важность мы хотим придать вознаграждениям, ожидающим нас в перспективе.
Данный алгоритм кратко изложен ниже:
Итак, ваша модель обучена в условиях окружающей среды, и теперь умеет более точно подбирать пассажиров. А вы познакомились с феноменом обучения с подкреплением, и можете запрограммировать алгоритм для решения новой задачи.
Другие приемы обучения с подкреплением:
Введение в обучение с подкреплением: от многорукого бандита до полноценного RL агента
Привет, Хабр! Обучение с подкреплением является одним из самых перспективных направлений машинного обучения. С его помощью искусственный интеллект сегодня способен решать широчайший спектр задач: от робототехники и видеоигр до моделирования поведения покупателей и здравоохранения. В этой вводной статье мы изучим главную идею reinforcement learning и с нуля построим собственного самообучающегося бота.

Введение
Основное отличие обучения с подкреплением (reinforcement learning) от классического машинного обучения заключается в том, что искусственный интеллект обучается в процессе взаимодействия с окружающей средой, а не на исторических данных. Соединив в себе способность нейронных сетей восстанавливать сложные взаимосвязи и самообучаемость агента (системы) в reinforcement learning, машины достигли огромных успехов, победив сначала в нескольких видеоиграх Atari, а потом и чемпиона мира по игре в го.
Если вы привыкли работать с задачами обучения с учителем, то в случае reinforcement learning действует немного иная логика. Вместо того, чтобы создавать алгоритм, который обучается на наборе пар «факторы — правильный ответ», в обучении с подкреплением необходимо научить агента взаимодействовать с окружающей средой, самостоятельно генерируя эти пары. Затем на них же он будет обучаться через систему наблюдений (observations), выигрышей (reward) и действий (actions).
Очевидно, что теперь в каждый момент времени у нас нет постоянного правильного ответа, поэтому задача становится немного хитрее. В этой серии статей мы будем создавать и обучать агентов обучения с подкреплением. Начнем с самого простого варианта агента, чтобы основная идея reinforcement learning была предельно понятна, а затем перейдем к более сложным задачам.
Многорукий бандит
Самый простой пример задачи обучения с подкреплением — задача о многоруком бандите (она достаточно широко освещена на Хабре, в частности, тут и тут). В нашей постановке задачи есть n игровых автоматов, в каждом из которых фиксирована вероятность выигрыша. Тогда цель агента — найти слот-машину с наибольшим ожидаемым выигрышем и всегда выбирать именно ее. Для простоты у нас будет всего четыре игровых автомата, из которых нужно будет выбирать.
По правде говоря, эту задачу можно с натяжкой отнести к reinforcement learning, поскольку задачам из этого класса характерны следующие свойства:
В области обучения с подкреплением есть и другой подход, при котором агенты обучают value functions. Вместо того, чтобы находить оптимальное действие в текущем состоянии, агент учиться предсказывать, насколько выгодно находиться в данном состоянии и совершать данное действие. Оба подхода дают хорошие результаты, однако логика policy gradient более очевидна.
Policy Gradient
Как мы уже выяснили, в нашем случае ожидаемый выигрыш каждого из игровых автоматов не зависит от текущего состояния среды. Получается, что наша нейросеть будет состоять лишь из набора весов, каждый из которых соответствует одному игровому автомату. Эти веса и будут определять, за какую ручку нужно дернуть, чтобы получить максимальный выигрыш. К примеру, если все веса инициализировать равными 1, то агент будет одинаково оптимистичен по поводу выигрыша во всех игровых автоматах.
Для обновления весов модели мы будем использовать e-жадную линию поведения. Это значит, что в большинстве случаев агент будет выбирать действие, максимизирующее ожидаемый выигрыш, однако иногда (с вероятностью равной e) действие будет случайным. Так будет обеспечен выбор всех возможных вариантов, что позволит нейросети «узнать» больше о каждом из них.

Интуитивно понятно, что функция потерь должна принимать такие значения, чтобы веса действий, которые привели к выигрышу увеличивались, а те, которые привели к проигрышу, уменьшались. В результате веса будут обновляться, а агент будет все чаще и чаще выбирать игровой автомат с наибольшей фиксированной вероятностью выигрыша, пока, наконец, он не будет выбирать его всегда.
Реализация алгоритма
Бандиты. Сначала мы создадим наших бандитов (в быту игровой автомат называют бандитом). В нашем примере их будет 4. Функция pullBandit генерирует случайное число из стандартного нормального распределения, а затем сравнивает его со значением бандита и возвращает результат игры. Чем дальше по списку находится бандит, тем больше вероятность, что агент выиграет, выбрав именно его. Таким образом, мы хотим, чтобы наш агент научился всегда выбирать последнего бандита.
Агент. Кусок кода ниже создает нашего простого агента, который состоит из набора значений для бандитов. Каждое значение соответствует выигрышу/проигрышу в зависимости от выбора того или иного бандита. Чтобы обновлять веса агента мы используем policy gradient, то есть выбираем действия, минимизирующие функцию потерь:
Обучение агента. Мы будем обучать агента, путем выбора определенных действий и получения выигрышей/проигрышей. Используя полученные значения, мы будем знать, как именно обновить веса модели, чтобы чаще выбирать бандитов с большим ожидаемым выигрышем:
Полный Jupyter Notebook можно скачать тут.
Решение полноценной задачи обучения с подкреплением
Теперь, когда мы знаем, как создать агента, способного выбирать оптимальное решение из нескольких возможных, перейдем к рассмотрению более сложной задачи, которая и будет представлять собой пример полноценного reinforcement learning: оценивая текущее состояние системы, агент должен выбирать действия, которые максимизируют выигрыш не только сейчас, но и в будущем.
Системы, в которых может быть решена обучения с подкреплением называются Марковскими процессами принятия решений (Markov Decision Processes, MDP). Для таких систем характерны выигрыши и действия, обеспечивающие переход из одного состояния в другое, причем эти выигрыши зависят от текущего состояния системы и решения, которое принимает агент в этом состоянии. Выигрыш может быть получен с задержкой во времени.
Формально Марковский процесс принятия решений может быть определен следующим образом. MDP состоит из набора всех возможных состояний S и действий А, причем в каждый момент времени он находится в состоянии s и совершает действие a из этих наборов. Таким образом, дан кортеж (s, a) и для него определены T(s,a) — вероятность перехода в новое состояние s’ и R(s,a) — выигрыш. В итоге в любой момент времени в MDP агент находится в состоянии s, принимает решение a и в ответ получает новое состояние s’ и выигрыш r.
Для примера, даже процесс открывания двери можно представить в виде Марковского процесса принятия решений. Состоянием будет наш взгляд на дверь, а также расположение нашего тела и двери в мире. Все возможные движения тела, что мы можем сделать, и являются набором A, а выигрыш — это успешное открытие двери. Определенные действия (например, шаг в сторону двери) приближают нас к достижению цели, однако сами по себе не приносят выигрыша, так как его обеспечивает только непосредственно открывание двери. В итоге, агент должен совершать такие действия, которые рано или поздно приведут к решению задачи.
Задача стабилизации перевернутого маятника
Воспользуемся OpenAI Gym — платформой для разработки и тренировки AI ботов с помощью игр и алгоритмических испытаний и возьмем классическую задачу оттуда: задача стабилизации перевернутого маятника или Cart-Pole. В нашем случае суть задачи заключается в том, чтобы как можно дольше удерживать стержень в вертикальном положении, двигая тележку по горизонтали:
В отличии от задачи о многоруком бандите, в данной системе есть:
Таким образом, каждое действие агента будет совершено с учетом не только мгновенного выигрыша, но и всех последующих. Также теперь мы будем использовать скорректированный выигрыш в качестве оценки элемента A (advantage) в функции потерь.
Реализация алгоритма
Импортируем библиотеки и загрузим среду задачи Cart-Pole:
Агент. Сначала создадим функцию, которая будет дисконтировать все последующие выигрыши на текущий момент:
Теперь создадим нашего агента:
Обучение агента. Теперь, наконец, перейдем к обучению агента:
Полный Jupyter Notebook вы можете посмотреть тут. Увидимся в следующих статьях, где мы продолжим изучать обучение с подкреплением!
Обучение с подкреплением для самых маленьких
В данной статье разобран принцип работы метода машинного обучения«Обучение с подкреплением» на примере физической системы. Алгоритм поиска оптимальной стратегии реализован в коде на Python с помощью метода «Q-Learning».
Обучение с подкреплением — это метод машинного обучения, при котором происходит обучение модели, которая не имеет сведений о системе, но имеет возможность производить какие-либо действия в ней. Действия переводят систему в новое состояние и модель получает от системы некоторое вознаграждение. Рассмотрим работу метода на примере, показанном в видео. В описании к видео находится код для Arduino, который реализуем на Python.
Задача
С помощью метода «обучение с подкреплением» необходимо научить тележку отъезжать от стены на максимальное расстояние. Награда представлена в виде значения изменения расстояния от стены до тележки при движении. Измерение расстояния D от стены производится дальномером. Движение в данном примере возможно только при определенном смещении «привода», состоящего из двух стрел S1 и S2. Стрелы представляют собой два сервопривода с направляющими, соединенными в виде «колена». Каждый сервопривод в данном примере может поворачиваться на 6 одинаковых углов. Модель имеет возможность совершить 4 действия, которые представляют собой управление двумя сервоприводами, действие 0 и 1 поворачивают первый сервопривод на определенный угол по часовой и против часовой стрелке, действие 2 и 3 поворачивают второй сервопривод на определенный угол по часовой и против часовой стрелке. На рисунке 1 показан рабочий прототип тележки.

Рис. 1. Прототип тележки для экспериментов с машинным обучением
На рисунке 2 красным цветом выделена стрела S2, синим цветом – стрела S1, черным цветом – 2 сервопривода.

Рис. 2. Двигатель системы
Схема системы показана на рисунке 3. Расстояние до стены обозначено D, желтым показан дальномер, красным и черным выделен привод системы.

Рис. 3. Схема системы
Диапазон возможных положений для S1 и S2 показан на рисунке 4:

Рис. 4.а. Диапазон положений стрелы S1
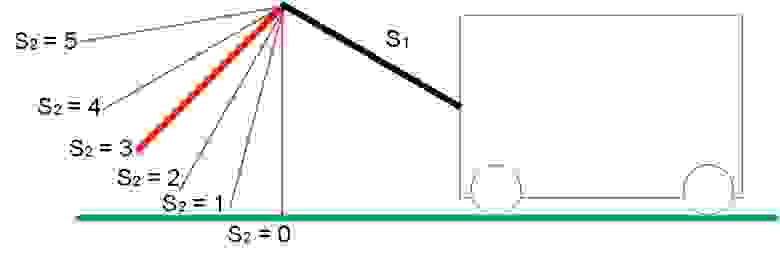
Рис. 4.б. Диапазон положений стрелы S2
Пограничные положения привода показаны на рисунке 5:
При S1 = S2 = 5 максимальная дальность от земли.
При S1 = S2 = 0 минимальная дальность до земли.

Рис. 5. Пограничные положения стрел S1 и S2
У «привода» 4 степени свободы. Действие (action) изменяет положение стрел S1 и S2 в пространстве по определённому принципу. Виды действий показаны на рисунке 6.
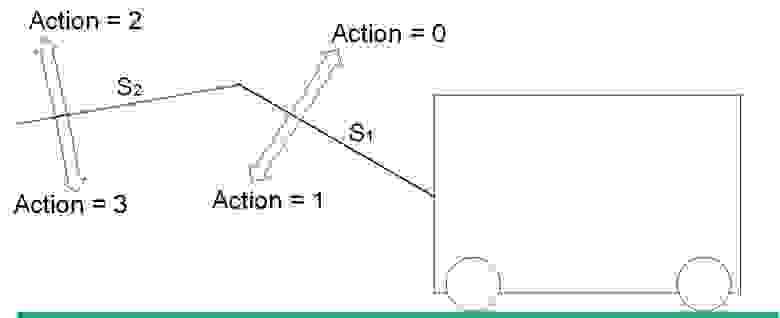
Рис. 6. Виды действий (Action) в системе
Действие 0 увеличивает значение S1. Действие 1 уменьшает значение S1.
Действие 2 увеличивает значение S2. Действие 3 уменьшает значение S2.
Движение
В нашей задаче тележка приводится в движение всего в 2х случаях:
В положении S1 =0, S2 = 1 действие 3 приводит в движение тележку от стены, система получает положительное вознаграждение, равное изменению расстояния до стены. В нашем примере вознаграждение равно 1.

Рис. 7. Движение системы с положительным вознаграждением
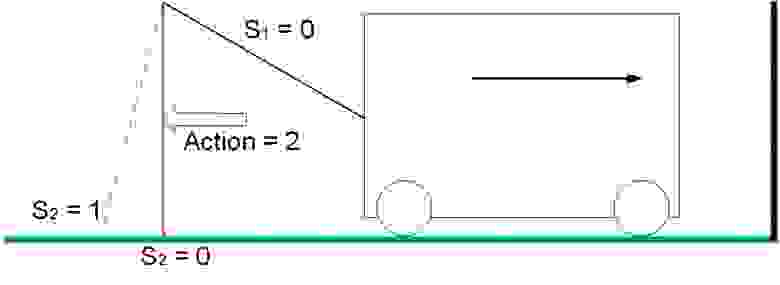
Рис. 8. Движение системы с отрицательным вознаграждением
При остальных состояниях и любых действиях «привода» система будет стоять на месте и вознаграждение будет равно 0.
Хочется отметить, что стабильным динамическим состоянием системы будет последовательность действий 0-2-1-3 из состояния S1=S2=0, в котором тележка будет двигаться в положительном направлении при минимальном количестве затраченных действий. Подняли колено – разогнули колено – опустили колено – согнули колено = тележка сдвинулась вперед, повтор. Таким образом, с помощью метода машинного обучения необходимо найти такое состояние системы, такую определенную последовательность действий, награда за которые будет получена не сразу (действия 0-2-1 – награда за которые равна 0, но которые необходимы для получения 1 за последующее действие 3).
Метод Q-Learning
Основой метода Q-Learning является матрица весов состояния системы. Матрица Q представляет собой совокупность всевозможных состояний системы и весов реакции системы на различные действия.
В данной задаче возможных комбинаций параметров системы 36 = 6^2. В каждом из 36 состояний системы возможно произвести 4 различных действия (Action = 0,1,2,3).
На рисунке 9 показано первоначальное состояние матрицы Q. Нулевая колонка содержит индекс строки, первая строка – значение S1, вторая – значение S2, последние 4 колонки равны весам при действиях равных 0, 1, 2 и 3. Каждая строка представляет собой уникальное состояние системы.
При инициализации таблицы все значения весов приравняем 10.

Рис. 9. Инициализация матрицы Q
После обучения модели (
15000 итераций) матрица Q имеет вид, показанный на рисунке 10.

Рис. 10. Матрица Q после 15000 итераций обучения
Обратите внимание, действия с весами, равными 10, невозможны в системе, поэтому значение весов не изменилось. Например, в крайнем положении при S1=S2=0 нельзя выполнить действие 1 и 3, так как это ограничение физической среды. Эти пограничные действия запрещены в нашей модели, поэтому 10тки алгоритм не использует.
Рассмотрим результат работы алгоритма:
…
Iteration: 14991, was: S1=0 S2=0, action= 0, now: S1=1 S2=0, prize: 0
Iteration: 14992, was: S1=1 S2=0, action= 2, now: S1=1 S2=1, prize: 0
Iteration: 14993, was: S1=1 S2=1, action= 1, now: S1=0 S2=1, prize: 0
Iteration: 14994, was: S1=0 S2=1, action= 3, now: S1=0 S2=0, prize: 1
Iteration: 14995, was: S1=0 S2=0, action= 0, now: S1=1 S2=0, prize: 0
Iteration: 14996, was: S1=1 S2=0, action= 2, now: S1=1 S2=1, prize: 0
Iteration: 14997, was: S1=1 S2=1, action= 1, now: S1=0 S2=1, prize: 0
Iteration: 14998, was: S1=0 S2=1, action= 3, now: S1=0 S2=0, prize: 1
Iteration: 14999, was: S1=0 S2=0, action= 0, now: S1=1 S2=0, prize: 0
Рассмотрим подробнее:
Возьмем итерацию 14991 в качестве текущего состояния.
1. Текущее состояние системы S1=S2=0, этому состоянию соответствует строка с индексом 0. Наибольшим значением является 0.617 (значения равные 10 игнорируем, описано выше), оно соответствует Action = 0. Значит, согласно матрице Q при состоянии системы S1=S2=0 мы производим действие 0. Действие 0 увеличивает значение угла поворота сервопривода S1 (S1 = 1).
2. Следующему состоянию S1=1, S2=0 соответствует строка с индексом 6. Максимальное значение веса соответствует Action = 2. Производим действие 2 – увеличение S2 (S2 = 1).
3. Следующему состоянию S1=1, S2=1 соответствует строка с индексом 7. Максимальное значение веса соответствует Action = 1. Производим действие 1 – уменьшение S1 (S1 = 0).
4. Следующему состоянию S1=0, S2=1 соответствует строка с индексом 1. Максимальное значение веса соответствует Action = 3. Производим действие 3 – уменьшение S2 (S2 = 0).
5. В итоге вернулись в состояние S1=S2=0 и заработали 1 очко вознаграждения.
На рисунке 11 показан принцип выбор оптимального действия.
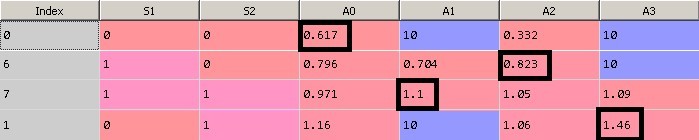
Рис. 11.а. Матрица Q

Рис. 11.б. Матрица Q
Рассмотрим подробнее процесс обучения.
Установим начальное положение колена в крайнее верхнее положение:
Инициализируем матрицу Q, заполнив начальным значением:
Вычислим параметр epsilon. Это вес «случайности» действия алгоритма в нашем расчёте. Чем больше итераций обучения прошло, тем меньше случайных значений действий будут выбраны:
Для первой итерации:
Сохраним текущее состояние:
Получим «лучшее» значение действия:
Рассмотрим функцию поподробнее.
Функция getAction() выдает значение действия, которому соответствует максимальный вес при текущем состоянии системы. Берется текущее состояние системы в матрице Q и выбирается действие, которому соответствует максимальный вес. Обратим внимание, что в этой функции реализован механизм выбора случайного действия. С увеличением числа итераций случайный выбор действия уменьшается. Это сделано, для того, чтобы алгоритм не зацикливался на первых найденных вариантах и мог пойти по другому пути, который может оказаться лучше.
В исходном начальном положении стрел возможны только два действия 1 и 3. Алгоритм выбрал действие 1.
Далее определим номер строки в матрице Q для следующего состояние системы, в которое система перейдет после выполнения действия, которое мы получили в предыдущем шаге.
В реальной физической среде после выполнения действия мы получили бы вознаграждение, если последовало движение, но так как движение тележки моделируется, необходимо ввести вспомогательные функции эмуляции реакции физической среды на действия. (setPhysicalState и getDeltaDistanceRolled() )
Выполним функции:
— моделируем реакцию среды на выбранное нами действие. Изменяем положение сервоприводов, смещаем тележку.
— Вычисляем вознаграждение – расстояние, пройденное тележкой.
После выполнения действия нам необходимо обновить коэффициент этого действия в матрице Q для соответствующего состояния системы. Логично, что, если действие привело к положительной награде, то коэффициент, в нашем алгоритме, должен уменьшиться на меньшее значение, чем при отрицательном вознаграждении.
Теперь самое интересное – для расчета веса текущего шага заглянем в будущее.
При определении оптимального действия, которое нужно совершить в текущем состоянии, мы выбираем наибольший вес в матрице Q. Так как мы знаем новое состояние системы, в которое мы перешли, то можем найти максимальное значение веса из таблицы Q для этого состояния:
В самом начале оно равно 10. И используем значение веса, еще не выполненного действия, для подсчета текущего веса.
Т.е. мы использовали значение веса следующего шага, для расчета веса шага текущего. Чем больше вес следующего шага, тем меньше мы уменьшим вес текущего (согласно формуле), и тем текущий шаг будет предпочтительнее в следующий раз.
Этот простой трюк дает хорошие результаты сходимости алгоритма.
Масштабирование алгоритма
Данный алгоритм можно расширить на большее количество степеней свободы системы (s_features), и большее количество значений, которые принимает степень свободы (s_states), но в небольших пределах. Достаточно быстро матрица Q займет всю оперативную память. Ниже пример кода построения сводной матрицы состояний и весов модели. При количестве «стрел» s_features = 5 и количестве различных положений стрелы s_states = 10 матрица Q имеет размеры (100000, 9).
Вывод
Этот простой метод показывает «чудеса» машинного обучения, когда модель ничего не зная об окружающей среде обучается и находит оптимальное состояние, при котором награда за действия максимальна, причем награда присуждается не сразу, за какое либо действие, а за последовательность действий.