предиктивное моделирование на практике pdf
Предиктивное моделирование на практике, Кун М., Джонсон К., 2019
К сожалению, на данный момент у нас невозможно бесплатно скачать полный вариант книги.
Но вы можете попробовать скачать полный вариант, купив у наших партнеров электронную книгу здесь, если она у них есть наличии в данный момент.
Также можно купить бумажную версию книги здесь.
Предиктивное моделирование на практике, Кун М., Джонсон К., 2019.
«Предиктивное моделирование на практике» охватывает все аспекты прогнозирования, начиная с ключевых этапов предварительной обработки данных, разбиения данных и основных принципов настройки модели. Все этапы моделирования рассматриваются на практических примерах из реальной жизни, в каждой главе дается подробный код на языке R. Эта книга может использоваться как введение в предиктивные модели и руководство по их применению. Читатели, не обладающие математической подготовкой, оценят интуитивно понятные объяснения конкретных методов, а внимание, уделяемое решению актуальных задач с реальными данными, поможет специалистам, желающим повысить свою квалификацию. Авторы постарались избежать сложных формул, для усвоения основного материала достаточно понимания основных статистических концепций, таких как корреляция и линейный регрессионный анализ, но для изучения углубленных тем понадобится математическая подготовка Для работы с книгой нужно иметь базовые знания о языке R.

Предисловие.
Эта книга посвящена анализу данных, при этом особое внимание в ней уделяется практике предиктивного моделирования (predictive modeling). Термин «предиктив-ное моделирование» может вызвать ассоциации с такими темами, как машинное обучение, распознавание образов и глубокий анализ данных (data mining.) Действительно, эти ассоциации уместны, а методы, которые обычно связываются с этими терминами, являются неотъемлемой частью процесса предиктивного моделирования. Однако предиктивное моделирование отнюдь не ограничивается инструментами и методами выявления закономерностей в данных. Практика предиктивного моделирования определяет такой процесс разработки модели, который бы позволил нам понять и дать численную оценку предиктивной точности модели для будущих, пока еще отсутствующих данных. Центральное место в книге занимает этот процесс в целом.
Краткое содержание.
Предисловие
ЧАСТЬ I ОБЩИЕ СТРАТЕГИИ
ЧАСТЬ II РЕГРЕССИОННЫЕ МОДЕЛИ
ЧАСТЬ III КЛАССИФИКАЦИОННЫЕ МОДЕЛИ
ЧАСТЬ IV ПРОЧИЕ ВОПРОСЫ ПРЕДИКТИВНОГО МОДЕЛИРОВАНИЯ
ПРИЛОЖЕНИЯ
По кнопкам выше и ниже «Купить бумажную книгу» и по ссылке «Купить» можно купить эту книгу с доставкой по всей России и похожие книги по самой лучшей цене в бумажном виде на сайтах официальных интернет магазинов Лабиринт, Озон, Буквоед, Читай-город, Литрес, My-shop, Book24, Books.ru.
По кнопке «Найти похожие материалы на других сайтах» можно найти похожие материалы на других сайтах.
On the buttons above and below you can buy the book in official online stores Labirint, Ozon and others. Also you can search related and similar materials on other sites.
Книга «Предиктивное моделирование на практике»
 Привет, Хаброжители! «Предиктивное моделирование на практике» охватывает все аспекты прогнозирования, начиная с ключевых этапов предварительной обработки данных, разбиения данных и основных принципов настройки модели. Все этапы моделирования рассматриваются на практических примерах из реальной жизни, в каждой главе дается подробный код на языке R.
Привет, Хаброжители! «Предиктивное моделирование на практике» охватывает все аспекты прогнозирования, начиная с ключевых этапов предварительной обработки данных, разбиения данных и основных принципов настройки модели. Все этапы моделирования рассматриваются на практических примерах из реальной жизни, в каждой главе дается подробный код на языке R.
Эта книга может использоваться как введение в предиктивные модели и руководство по их применению. Читатели, не обладающие математической подготовкой, оценят интуитивно понятные объяснения конкретных методов, а внимание, уделяемое решению актуальных задач с реальными данными, поможет специалистам, желающим повысить свою квалификацию.
Авторы постарались избежать сложных формул, для усвоения основного материала достаточно понимания основных статистических концепций, таких как корреляция и линейный регрессионный анализ, но для изучения углубленных тем понадобится математическая подготовка.
Отрывок. 7.5. Вычисления
В этом разделе будут использоваться функции из пакетов R caret, earth, kernlab и nnet.
В R имеется немало пакетов и функций для создания нейросетей. К их числу относятся и пакеты nnet, neural и RSNNS. Основное внимание уделяется пакету nnet, поддерживающему базовые модели нейросетей с одним уровнем скрытых переменных, снижение весов, и характеризующемуся сравнительно простым синтаксисом. RSNNS поддерживает широкий спектр нейросетей. Отметим, что у Бергмейра и Бенитеса (Bergmeir and Benitez, 2012) есть краткое описание различных пакетов нейросетей в R. Там же приводится учебное руководство по RSNNS.
Нейросети
Для апрроксимации регрессионной модели функция nnet может получать как формулу модели, так и матричный интерфейс. Для регрессии линейная связь между скрытыми переменными и прогнозом используется с параметром linout = TRUE. Простейший вызов функции нейросети будет иметь вид:
Этот вызов создает одну модель с пятью скрытыми переменными. Предполагается, что данные в предикторах были стандартизированы по одной шкале.
Для усреднения моделей используется функция avNNet из пакета caret, имеющая тот же синтаксис:
Новые точки данных обрабатываются командой
Чтобы воспроизвести представленный ранее метод выбора количества скрытых переменных и величины снижения весов посредством повторной выборки, применим функцию train с параметром method = «nnet» или method = «avNNet», сначала удалив предикторы (с тем, чтобы максимальная абсолютная парная корреляция между предикторами не превышала 0,75):
Многомерные адаптивные регрессионные сплайны
Модели MARS содержатся в нескольких пакетах, но самая обширная реализация находится в пакете earth. Модель MARS, использующая номинальную фазу прямого прохода и усечения, может вызываться следующим образом:
Поскольку эта модель во внутренней реализации использует метод GCV для выбора модели, ее устройство несколько отличается от модели, описанной ранее в этой главе. Метод summary генерирует более обширный вывод:
В этом выводе h(·) — шарнирная функция. В приведенных результатах составляющая h(MolWeight-5.77508) равна нулю при значении молекулярной массы меньше 5,77508 (как в верхней части рис. 7.3). Отраженная шарнирная функция имеет вид h(5.77508 — MolWeight).
Функция plotmo из пакета earth может использоваться для построения диаграмм, сходных с изображенными на рис. 7.5. Для настройки модели с использованием внешней повторной выборки можно воспользоваться train. В следующем коде воспроизведены результаты, отображенные на рис. 7.4:
Для оценки важности каждого предиктора в модели MARS используются две функции: evimp из пакета earth и varImp из пакета caret (при этом вторая вызывает первую):
Эти результаты масштабируются в интервале от 0 до 100, отличаясь от приведенных в табл. 7.1 (представленная в табл. 7.1 модель не прошла полный процесс роста и усечения). Отметим, что переменные, следующие за несколькими первыми из них, менее значимы для модели.
SVM, метод опорных векторов
Реализации моделей SVM содержатся в нескольких пакетах R. У Чанга и Лина (Chang and Lin, 2011) функция svm из пакета e1071 использует интерфейс к библиотеке LIBSVM для регрессии. Более полная реализация моделей SVM для регрессии по Карацоглу (Karatzoglou et al., 2004) содержится в пакете kernlab, включающем и функцию ksvm для регрессионных моделей и большого количества ядерных функций. По умолчанию используется радиальная базисная функция. Если значения стоимости и ядерных параметров известны, то аппроксимация модели может быть выполнена следующим образом:
Для оценки σ применен автоматизированный анализ. Так как y является числовым вектором, функция заведомо аппроксимирует регрессионную модель (вместо классификационной модели). Можно использовать и другие ядерные функции, включая полиномиальные (kernel = «polydot») и линейные (kernel = «vanilladot»).
Если значения неизвестны, то их можно оценить посредством повторной выборки. В train значения «svmRadial», «svmLinear» или «svmPoly» параметра method выбирают разные ядерные функции:
Аргумент tuneLength использует по умолчанию 14 значений стоимости 
Оценка σ по умолчанию выполняется посредством автоматического анализа.
Подобъект finalModel содержит модель, созданную функцией ksvm:
В качестве опорных векторов модель использует 625 точек данных тренировочного набора (то есть 66 % тренировочного набора).
Пакет kernlab содержит реализацию модели RVM для регрессии в функции rvm. Ее синтаксис очень похож на представленный в примере для ksvm.
Метод KNN
Функция knnreg из пакета caret аппроксимирует регрессионную модель KNN; функция train настраивает модель по K:
Об авторах:
Макс Кун — руководитель отдела статистических неклинических исследований и разработки Pfizer Global. Он работает с предиктивными моделями более 15 лет и является автором нескольких специализированных пакетов для языка R. Предиктивное моделирование на практике охватывает все аспекты прогнозирования, начиная с ключевых этапов предварительной обработки данных, разбиения данных и основных принципов
настройки модели. Все этапы моделирования рассматриваются на практических примерах
из реальной жизни, в каждой главе дается подробный код на языке R.
Кьелл Джонсон — более десяти лет работает в области статистики и предиктивного моделирования для фармацевтических исследований. Является соучредителем Arbor Analytics – компании, специализирующейся на предиктивном моделировании; ранее возглавлял отдел статистических исследований и разработки в Pfizer Global. Его научная работа посвящена применению и разработке статистической методологии и алгоритмов обучения.
Для Хаброжителей скидка 25% по купону — Applied Predictive Modeling
По факту оплаты бумажной версии книги на e-mail высылается электронная книга.
Книга «Предиктивное моделирование на практике»
 Привет, Хаброжители! «Предиктивное моделирование на практике» охватывает все аспекты прогнозирования, начиная с ключевых этапов предварительной обработки данных, разбиения данных и основных принципов настройки модели. Все этапы моделирования рассматриваются на практических примерах из реальной жизни, в каждой главе дается подробный код на языке R.
Привет, Хаброжители! «Предиктивное моделирование на практике» охватывает все аспекты прогнозирования, начиная с ключевых этапов предварительной обработки данных, разбиения данных и основных принципов настройки модели. Все этапы моделирования рассматриваются на практических примерах из реальной жизни, в каждой главе дается подробный код на языке R.
Эта книга может использоваться как введение в предиктивные модели и руководство по их применению. Читатели, не обладающие математической подготовкой, оценят интуитивно понятные объяснения конкретных методов, а внимание, уделяемое решению актуальных задач с реальными данными, поможет специалистам, желающим повысить свою квалификацию.
Авторы постарались избежать сложных формул, для усвоения основного материала достаточно понимания основных статистических концепций, таких как корреляция и линейный регрессионный анализ, но для изучения углубленных тем понадобится математическая подготовка.
Отрывок. 7.5. Вычисления
В этом разделе будут использоваться функции из пакетов R caret, earth, kernlab и nnet.
В R имеется немало пакетов и функций для создания нейросетей. К их числу относятся и пакеты nnet, neural и RSNNS. Основное внимание уделяется пакету nnet, поддерживающему базовые модели нейросетей с одним уровнем скрытых переменных, снижение весов, и характеризующемуся сравнительно простым синтаксисом. RSNNS поддерживает широкий спектр нейросетей. Отметим, что у Бергмейра и Бенитеса (Bergmeir and Benitez, 2012) есть краткое описание различных пакетов нейросетей в R. Там же приводится учебное руководство по RSNNS.
Нейросети
Для апрроксимации регрессионной модели функция nnet может получать как формулу модели, так и матричный интерфейс. Для регрессии линейная связь между скрытыми переменными и прогнозом используется с параметром linout = TRUE. Простейший вызов функции нейросети будет иметь вид:
Этот вызов создает одну модель с пятью скрытыми переменными. Предполагается, что данные в предикторах были стандартизированы по одной шкале.
Для усреднения моделей используется функция avNNet из пакета caret, имеющая тот же синтаксис:
Новые точки данных обрабатываются командой
Чтобы воспроизвести представленный ранее метод выбора количества скрытых переменных и величины снижения весов посредством повторной выборки, применим функцию train с параметром method = «nnet» или method = «avNNet», сначала удалив предикторы (с тем, чтобы максимальная абсолютная парная корреляция между предикторами не превышала 0,75):
Многомерные адаптивные регрессионные сплайны
Модели MARS содержатся в нескольких пакетах, но самая обширная реализация находится в пакете earth. Модель MARS, использующая номинальную фазу прямого прохода и усечения, может вызываться следующим образом:
Поскольку эта модель во внутренней реализации использует метод GCV для выбора модели, ее устройство несколько отличается от модели, описанной ранее в этой главе. Метод summary генерирует более обширный вывод:
В этом выводе h(·) — шарнирная функция. В приведенных результатах составляющая h(MolWeight-5.77508) равна нулю при значении молекулярной массы меньше 5,77508 (как в верхней части рис. 7.3). Отраженная шарнирная функция имеет вид h(5.77508 — MolWeight).
Функция plotmo из пакета earth может использоваться для построения диаграмм, сходных с изображенными на рис. 7.5. Для настройки модели с использованием внешней повторной выборки можно воспользоваться train. В следующем коде воспроизведены результаты, отображенные на рис. 7.4:
Для оценки важности каждого предиктора в модели MARS используются две функции: evimp из пакета earth и varImp из пакета caret (при этом вторая вызывает первую):
Эти результаты масштабируются в интервале от 0 до 100, отличаясь от приведенных в табл. 7.1 (представленная в табл. 7.1 модель не прошла полный процесс роста и усечения). Отметим, что переменные, следующие за несколькими первыми из них, менее значимы для модели.
SVM, метод опорных векторов
Реализации моделей SVM содержатся в нескольких пакетах R. У Чанга и Лина (Chang and Lin, 2011) функция svm из пакета e1071 использует интерфейс к библиотеке LIBSVM для регрессии. Более полная реализация моделей SVM для регрессии по Карацоглу (Karatzoglou et al., 2004) содержится в пакете kernlab, включающем и функцию ksvm для регрессионных моделей и большого количества ядерных функций. По умолчанию используется радиальная базисная функция. Если значения стоимости и ядерных параметров известны, то аппроксимация модели может быть выполнена следующим образом:
Для оценки σ применен автоматизированный анализ. Так как y является числовым вектором, функция заведомо аппроксимирует регрессионную модель (вместо классификационной модели). Можно использовать и другие ядерные функции, включая полиномиальные (kernel = «polydot») и линейные (kernel = «vanilladot»).
Если значения неизвестны, то их можно оценить посредством повторной выборки. В train значения «svmRadial», «svmLinear» или «svmPoly» параметра method выбирают разные ядерные функции:
Аргумент tuneLength использует по умолчанию 14 значений стоимости 
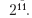 Оценка σ по умолчанию выполняется посредством автоматического анализа.
Оценка σ по умолчанию выполняется посредством автоматического анализа.
Подобъект finalModel содержит модель, созданную функцией ksvm:
В качестве опорных векторов модель использует 625 точек данных тренировочного набора (то есть 66 % тренировочного набора).
Пакет kernlab содержит реализацию модели RVM для регрессии в функции rvm. Ее синтаксис очень похож на представленный в примере для ksvm.
Метод KNN
Функция knnreg из пакета caret аппроксимирует регрессионную модель KNN; функция train настраивает модель по K:
Об авторах:
Макс Кун — руководитель отдела статистических неклинических исследований и разработки Pfizer Global. Он работает с предиктивными моделями более 15 лет и является автором нескольких специализированных пакетов для языка R. Предиктивное моделирование на практике охватывает все аспекты прогнозирования, начиная с ключевых этапов предварительной обработки данных, разбиения данных и основных принципов
настройки модели. Все этапы моделирования рассматриваются на практических примерах
из реальной жизни, в каждой главе дается подробный код на языке R.
Кьелл Джонсон — более десяти лет работает в области статистики и предиктивного моделирования для фармацевтических исследований. Является соучредителем Arbor Analytics – компании, специализирующейся на предиктивном моделировании; ранее возглавлял отдел статистических исследований и разработки в Pfizer Global. Его научная работа посвящена применению и разработке статистической методологии и алгоритмов обучения.
Для Хаброжителей скидка 25% по купону — Applied Predictive Modeling
По факту оплаты бумажной версии книги на e-mail высылается электронная книга.
Предиктивная аналитика данных — моделирование и валидация
Представляю вашему вниманию перевод главы из книги Hands-On Data Science with Anaconda
«Предиктивная аналитика данных — моделирование и валидация»
Наша основная цель в проведении различных анализов данных — это поиск шаблонов, чтобы предсказать, что может произойти в будущем. Для фондового рынка исследователи и специалисты проводят различные тесты, чтобы понять рыночные механизмы. В этом случае можно задать много вопросов. Каким будет уровень рыночного индекса в ближайшие пять лет? Каков будет следующий ценовой диапазон IBM? Будет ли волатильность рынка увеличиваться или уменьшаться в будущем? Каким может быть влияние, если правительства изменят свою налоговую политику? Какова потенциальная прибыль и убытки, если одна страна начнет торговую войну с другой? Как мы прогнозируем поведение потребителя, анализируя некоторые связанные переменные? Можем ли мы предсказать вероятность того, что студент-выпускник успешно закончит учебу? Можем ли мы найти связь между определенным поведением одного конкретного заболевания?
Поэтому мы рассмотрим следующие темы:
Понимание предиктивного анализа данных
У людей может быть много вопросов касательно будущих событий.
Полезные наборы данных
Одним из лучших источников данных является UCI Machine Learning Repository. Зайдя на сайт мы увидим следующий список:
Например, если выбрать первый набор данных (Abalone), мы увидим следующее. Для экономии места отображается только верхняя часть:
Отсюда пользователи могут загрузить набор данных и найти определения переменных. Следующий код может быть использован для загрузки набора данных:
Соответствующий вывод показан здесь:
Из предыдущего вывода мы знаем, что в наборе данных имеется 427 наблюдения (набора данных). Для каждого из них у нас есть 7 связанных функций, таких как Name, Data_Types, Default_Task, Attribute_Types, N_Instances (количество экземпляров), N_Attributes (количество атрибутов) и Year. Переменная, называемая Default_Task, может быть интерпретирована как основное использование каждого набора данных. Например, первый набор данных, называемый Abalone, может быть использован для Classification. Функция unique() может быть использована для поиска всех возможных Default_Task, показанных здесь:
R пакет AppliedPredictiveModeling
Этот пакет включает в себя множество полезных наборов данных, которые могут использоваться для этой главы и других. Самый простой способ найти эти наборы данных — с помощью функции help(), показанной здесь:
Здесь мы покажем несколько примеров загрузки этих наборов данных. Чтобы загрузить один набор данных, мы используем функцию data(). Для первого набора данных, называемого abalone, у нас есть следующий код:
Вывод выглядит следующим образом:
Иногда, большой набор данных включает в себя несколько суб-наборов данных:
Для загрузки каждого набора данных, мы могли бы использовать функции dim(), head(), tail() и summary().
Аналитика временных рядов
Временные ряды можно определить как набор значений, полученных в последовательные моменты времени, часто с равными интервалами между ними. Существуют разные периоды, такие как годовой, ежеквартальный, ежемесячный, еженедельный и ежедневный. Для временных рядов ВВП (валовой внутренний продукт) мы обычно используем квартальные или годовые. Для котировок — годовые, ежемесячные и суточные частоты. Используя следующий код, мы можем получить данные ВВП США как ежеквартально, так и за годовой период:
Однако у нас есть много вопросов для анализа временных рядов. Например, с точки зрения макроэкономики мы имеем деловые или экономические циклы. Отрасли или компании могут иметь сезонность. Например, используя сельскохозяйственную промышленность, фермеры будут тратить больше в весенние и осенние сезоны и меньше на зиму. Для розничной торговли у них был бы огромный приток денег в конце года.
Чтобы манипулировать временными рядами, мы могли бы использовать множество полезных функций, включенных в пакет R, называемый timeSeries. В примере мы возьмем среднесуточные данные с еженедельной частотой:
Мы могли бы также использовать функцию head(), чтобы увидеть несколько наблюдений:
Прогнозирование будущих событий
Есть много методов, которые мы могли бы использовать при попытке предсказать будущее, таких как скользящее среднее, регрессия, авторегрессия и т. п. Во-первых, давайте начнем с простейшего для скользящего среднего:
В предыдущем коде значение по умолчанию для количества периодов равно 10. Мы могли бы использовать набор данных, называемый MSFT, включенный в пакет R, называемый timeSeries (см. Следующий код):
В ручном режиме мы находим, что среднее из первых трех значений x совпадает с третьим значением y. В каком-то смысле мы могли бы использовать скользящее среднее для прогнозирования будущего.
В следующем примере мы покажем, как оценить ожидаемую доходность рынка в следующем году. Здесь мы используем индекс S&P500 и историческое среднегодовое значение в качестве наших ожидаемых значений. Первые несколько команд используются для загрузки связанного набора данных под названием .sp500monthly. Целью программы является оценка среднегодового среднего и 90-процентного доверительного интервала:
Как видно из результатов, историческая среднегодовая доходность для S&P500 составляет 9%. Но мы не можем заявить, что доходность индекса в следующем году будет равна 9%, т.к. она может быть от 5% до 13%, а это огромные колебания.
Сезонность
В следующем примере мы покажем использование автокорреляции. Во-первых, мы загружаем R пакет под названием astsa, который выступает для прикладного статистического анализа временных рядов. Затем мы загружаем ВВП США с ежеквартальной частотой:
В вышеуказанном коде — функция diff() принимает разницу, например текущее значение минус предыдущее значение. Второе значение ввода указывает на задержку. Функция, называемая acf2(), используется для построения и печати ACF и PACF временного ряда. ACF обозначает функцию автоковариации, а PACF обозначает функцию частичной автокорреляции. Соответствующие графики показаны здесь:
Визуализация компонентов
Понятно, что концепции и наборы данных были бы намного более понятными, если бы мы могли использовать графики. Первый пример показывает колебания ВВП США за последние пять десятилетий:
Соответствующий график показан здесь:
Если бы мы использовали логарифмическую шкалу для ВВП, у нас был бы следующий код и график:
Следующий график близок к прямой линии:
R пакет – LiblineaR
Этот пакет представляет собой линейные прогностические модели, основанные на LIBLINEAR C/C++ Library. Вот один из примеров использования набора данных iris. Программа пытается предсказать, к какой категории относится растение, используя данные обучения:
Вывод следующий. BCR — это сбалансированная классификационная ставка. Для этой ставки, чем выше, тем лучше:
R пакет – eclust
Этот пакет представляет собой средо-ориентированную кластеризацию для интерпретируемых прогнозных моделей в высокоразмерных данных. Сначала давайте рассмотрим набор данных с именем simdata, который содержит смоделированные данные для пакета:
Предыдущий вывод показывает, что размерность данных равна 100 на 502. Y — это вектор непрерывного отклика, а E — двоичная переменная среды для метода ECLUST. E = 0 для неэкспонированных (n = 50) и E = 1 для экспонированных (n = 50).
Следующая программа R оценивает z-преобразование Фишера:
Определим z-преобразование Фишера. Предполагая, что у нас есть набор из n пар xi и yi, мы могли бы оценить их корреляцию, применяя следующую формулу:
Здесь p — корреляция между двумя переменными, а и являются выборочные средние для случайных величин х и у. Значение z определяется как:
ln — функция натурального логарифма, а arctanh() — обратная гиперболическая касательная функция.
Выбор модели
В следующей программе мы пытаемся использовать линейные и полиномиальные модели для аппроксимации уравнения. Слегка измененный код показан здесь. Программа иллюстрирует влияние нехватки/переизбытка данных на модель:
Полученные графики показаны здесь:
Python пакет – model-catwalk
Пример можно найти здесь.
Первые несколько строк кода показаны здесь:
Соответствующий вывод показан здесь. Для экономии места представлена только верхняя часть:
Python пакет – sklearn
Поскольку sklearn — очень полезный пакет, стоит показать больше примеров использования этого пакета. Приведенный здесь пример показывает, как использовать пакет для классификации документов по темам с использованием подхода «bag-of-words».
В этом примере используется матрица scipy.sparse для хранения объектов и демонстрируются различные классификаторы, которые могут эффективно обрабатывать разреженные матрицы. В этом примере используется набор данных из 20 групп новостей. Он будет автоматически загружен, а затем кэширован. ZIP-файл содержит входные файлы и может быть загружен здесь. Код доступен здесь. Для экономии места показаны только первые несколько строк:
Соответствующий вывод показан здесь:
Для каждого метода есть три показателя: оценка, время обучения и время тестирования.
Julia пакет – QuantEcon
Возьмем для примера использование Марковских цепей:
Цель примера состоит в том, чтобы увидеть, как человек из одного экономического статуса в будущем трансформируется в другого. Во-первых, давайте посмотрим на следующий график:
Давайте посмотрим на крайний левый овал со статусом «poor». 0.9 означает, что человек с таким статусом имеет 90% шансов остаться бедным, а 10% переходит в средний класс. Он может быть представлен следующей матрицей, нули находятся там, где нет ребра между узлами:
Говорят, что два состояния, x и y, связаны друг с другом, если существуют положительные целые числа j и k, такие как:
Цепь Маркова P называется неприводимой, если все состояния связываются; то есть, если x и y сообщаются для каждого (x, y). Следующий код подтвердит это:
Следующий график представляет экстремальный случай, так как будущий статус для бедного человека будет на 100% бедным:
Следующий код также подтвердит это, так как результат будет false:
Тест Грэнджера на причинность
Тест Грэнджера на причинность используется для определения того, является ли один временной ряд фактором, и предоставляет полезную информацию для прогнозирования второго. В следующем коде набор данных с именем ChickEgg используется в качестве иллюстрации. Набор данных имеет две колонки, число цыплят и количество яиц, с отметкой времени:
Вопрос в том, можем ли мы использовать число яиц в этом году, чтобы предсказать число цыплят в следующем году?
Если это так, то количество цыплят будет причиной по Грэнджеру для количества яиц. Если это не так, мы говорим, что количество цыплят не является причиной по Грэнджеру для количества яиц. Вот соответствующий код:
В модели 1 мы пытаемся использовать лаги цыплят плюс лаги яиц, чтобы объяснить количество цыплят.
Т.к. значение P довольно мало (оно значимо при 0,01) мы говорим, что количество яиц является причиной по Грэнджеру для количества цыплят.
Следующий тест показывает, что данные о цыплятах не могут быть использованы для прогнозирования следующего периода:
В следующем примере мы проверяем доходность IBM и S&P500 с целью выяснить, что их них является причиной по Грэнджеру для другого.
Сначала мы определим функцию доходности:
Теперь функция может быть вызвана с входными значениями. Цель программы — проверить, можем ли мы использовать отставания на рынке для объяснения доходности IBM. Точно так же мы проверяем, объяснить отставания IBM доходами рынка:
Результаты показывают, что индекс S&P500 можно использовать для объяснения доходности IBM за следующий период, поскольку он статистически значим на уровне 0,1%. Следующий код будет проверять, объясняет ли отставание IBM изменение S&P500:
Результат предполагает, что в течение этого периода доходность IBM может быть использованы для объяснения индекса S&P500 следующего периода.