проклятие размерности машинное обучение
Проклятие размерности
Материал из MachineLearning.
До указанного срока статья не должна редактироваться другими участниками проекта MachineLearning.ru. По его окончании любой участник вправе исправить данную статью по своему усмотрению и удалить данное предупреждение, выводимое с помощью шаблона <<Задание>>.
См. также методические указания по использованию Ресурса MachineLearning.ru в учебном процессе.
Проклятие размерности — проблема, связанная с экспоненциальным возрастанием количества данных из-за увеличения размерности пространства. Термин «проклятие размерности» был введен Ричардом Беллманом в 1961 году.
Проблема «проклятия размерности» часто возникает в машинном обучении, например, при применении метода ближайших соседей и метода парзеновского окна.
Содержание
Проблемы
«Проклятие размерности» особенно явно проявляется при работе со сложными системами, которые описываются большим числом параметров.
Это влечет за собой следующие трудности:
Пример
Рассмотрим единичный интервал [0,1]. 100 равномерно разбросанных точек будет достаточно, чтобы покрыть этот интервал с частотой не менее 0,01.
Теперь рассмотрим 10-мерный куб. Для достижения той же степени покрытия потребуется уже 10 20 точек. То есть, по сравнению с одномерным пространством, требуется в 10 18 раз больше точек.
Поэтому, например, использование переборных алгоритмов становится неэффективным при возрастании размерности системы.
Способы устранения «проклятия размерности»
Основная идея при решении проблемы — понизить размерность пространства, а именно спроецировать данные на подпространство меньшей размерности.
На этой идее, например, основан метод главных компонент.
Обучение нейронных сетей: проклятие размерности

Представьте, что вы альпинист на вершине горы и наступает ночь. Вам нужно добраться до лагеря, что внизу скалы, но в свете тусклого фонарика вы можете видеть лишь на несколько метров. Так как же спуститься вниз? Одна из стратегий — оглядеться и понять, какой склон наиболее крутой, но не слишком, и сделать шаг туда. Повторить данный процесс много раз и постепенно вы доберетесь до подножья горы. Если вы застрянете в долине, это немного замедлит вас.
Обучение нейронной сети — это поиск наилучшего набора весов для максимизации точности предсказания.
Нейронные сети могут быть использованы и без четкого понимания, как именно они обучаются, так же как вы используете фонарик без четкого понимания, как работает микросхема внутри него. Современные библиотеки машинного обучения значительно автоматизируют процесс обучения нейронных сетей. Хотя обычно хочется пропустить математическую часть и поскорее приступить к практике, все же стоит внимательно прочитать об этом, так как это конвертируется в значительное преимущество при перенастройке и конфигурации сетей. Более того обучение нейросетей было описано много лет назад, но только сейчас оно стало доступным, став новой вехой в развитии DS.
Цель статьи — дать интуитивное понимание о том, как работают нейросети. Больше визуала, меньше уравнений. Поговорим о том, почему обучение нейросетей представляет сложность.
Обучение глубокой нейронной сети
Веса в скрытых слоях сильно зависимы. Чтобы понять почему, взгляните на картинку ниже, небольшое изменение веса в первом слое, окажет значительное влияние на дальнейшее распространение.
 Глубокая нейронная сеть (DNN)
Глубокая нейронная сеть (DNN)
Именно поэтому мы не можем получить идеальный набор весов просто подгоняя по одному. Мы должны найти комбинацию весов сразу. Но как это сделать?
Давайте начнем с самого наивного метода: случайный перебор. Установим веса случайным образом и подсчитаем результаты. Повторить много раз, сохранить все результаты, выбрать наиболее точные. На первый взгляд это кажется не таким уж плохим подходом. И действительно, компьютеры уже очень мощные, может быть мы можем получить решение брутфорсом? Для небольших нейронок (
N-мерное пространство — одинокое место
Если наша стратегия наугад найти веса, то логично задаться вопросом, сколько нужно сделать попыток для получения приемлемого набора весов. Интуитивно мы ожидаем, что сделав достаточно попыток мы покроем все пространство и найдем идеальный набор весов. Без априорных знаний веса могут быть в любой точке пространства, поэтому имеет смысл рассматривать как можно больше разных весов из пространства.
Чтобы проиллюстрировать это, давайте рассмотрим несколько простых однослойных нейросетей: с тремя и с двумя нейронами.

 Пространства 10х10(слева) и 10х10х10(справа) точек
Пространства 10х10(слева) и 10х10х10(справа) точек
В первом случае нужно найти всего два веса. Как много попыток нужно сделать, чтобы угадать идеальный набор? Один из подходов — представить двумерное пространство возможных весов и до изнеможения искать нужную комбинацию при некотором разбиении. Возможно, мы можем разбить каждую ось на 10 частей. Тогда попыток всего будет 10^2 = 100. Не так уж и плохо, но давайте сделаем разбиение более мелким, чтобы подобрать веса корректнее, например на 100 частей. Тогда уже комбинаций может быть 10,000. Достаточно маленькое число, компьютер сможет обработать его меньше, чем за секунду.
Так, а что же со второй сетью? Теперь нам нужно подобрать уже 3 веса и, следовательно, работать в трехмерном пространстве. Проделаем такие же операции 10*10*10 = 1000 вариантов и 100*100*100 = 1,000,000 вариантов соответственно при разных вариантах разбиения. Миллион вариантов — не так уж и страшно, но рост пугающий. И что же произойдет, когда мы перейдем к реальным сеткам?
Проклятие размерности
Что же будет, когад мы попробуем классифицировать цифры из датасета MNIST? Cеть будет содержать 784 входных нейронов, 15 нейронов в 1 скрытом слое и 10 выходных нейронов. Итого 784*15 + 15*10 = 11910 весов. Получается, чтобы угадать, нужно сделать 10^11910 попыток… Это 1 почти с 12,000 нулями. Для сравнения атомов в видимой Вселенной всего 10^80. Никакой суперкомпьютер не справится с таким перебором. И эта простая сетка даже близко не сравнится с самыми современными, где десятки и тысячи миллионов весов!
В машинном обучении данная проблема носит название “проклятие размерности”. Каждое измерение, которое мы добавляем, экспоненциально увеличивает количество требуемых для обобщения образцов. Проклятие размерности чаще всего применяется к наборам данных: чем больше столбцов или переменных, тем экспоненциально больше выборок в этом датасете нам нужно проанализировать. В нашем случае мы говорим о весах, а не о входных данных, но принцип остается неизменным — многомерное пространство огромно!
Очевидно, что для решения этой проблемы должно быть более элегантное решение, чем случайные догадки. Но об этом — в следующих статьях.
Проклятие размерности
Дата публикации Jul 20, 2019
Вы когда-нибудь рассказывали кому-то историю или пытались найти длинное объяснение чего-то сложного, когда другой человек смотрит на вас и спрашивает: «Какой смысл?»
Во-первых, твой друг такой грубый!
В этом суть уменьшения размерности.Когда мы сталкиваемся с кучей данных, мы можем использовать алгоритмы уменьшения размерности, чтобы данные «достигли цели».
Когда данные имеют большой размер и почему это может быть проблемой?
Проклятие размерности звучит как что-то прямо из пиратского фильма, нона самом деле это означает, что ваши данные имеют слишком много функций.
Фраза, приписываемая Ричарду Беллману, была придумана, чтобы выразить сложность использования грубой силы (a.k.a. grid search) для оптимизации функции со слишком большим количеством входных переменных. Представьте себе, что вы выполняете оптимизацию в Excel Solver, где есть 100 000 возможных входных переменных, или, другими словами, 100 000 потенциальных рычагов, которые можно потянуть (почти наверняка, это приведет к краху вашего Excel).
В современном мире больших данных это также может относиться к ряду других потенциальных проблем, которые возникают, когда ваши данные имеют огромное количество измерений:
Пункт 2 является важным, поэтому давайте рассмотрим пример, чтобы понять, почему это происходит.
Простой пример проклятия больших размеров данных
Представьте, что наш набор данных состоит из следующих 8 конфет.

Мы можем кластеризовать по цвету так:

Хорошо, благодаря нашей кластеризации мы знаем, что если мы будем есть красноватые конфеты, они будут пряными; и если мы будем есть голубоватую конфету, она будет сладкой.

Но что, если наши данные являются многомерными, как в следующей таблице?

Теперь вместо двух категорий цветов у нас есть 8. Как алгоритм кластеризации, вероятно, интерпретирует это? Было бы посмотреть на каждую конфету и сделать следующие выводы:
Уменьшение размерности для спасения
Ниже приведен стилизованный пример того, как работает уменьшение размерности. Это не предназначено для объяснения конкретного алгоритма, это простой пример, демонстрирующий некоторые принципы, которым следуют алгоритмы уменьшения размерности.

Затем алгоритм оценивает и переписывает все остальные функции с точки зрения подверженности этим скрытым функциям, как показано в таблице выше.

Ницца! Из графика выше видно, что использование наших скрытых функций (красного и синего) позволило нам создать два значимых кластера. Наконец, мы можем посмотреть в каждом кластере и подсчитать, сколько конфет являются пряными, а сколько сладкими, и использовать эту частоту в качестве основы для наших прогнозов.
Таким образом, наша пряная / сладкая модель для конфет будет выглядеть примерно так:
Вывод
Сегодня мы увидели, как слишком большое количество функций может запутать определенные алгоритмы машинного обучения, такие как алгоритмы кластеризации. И мы увидели, как уменьшение размерности может помочь восстановить порядок.
В реальном мире беспорядочных, зашумленных данных и сложных отношений (в отличие от наших простых конфет) уменьшение размерности представляет собой компромисс между более надежной моделью (надеюсь!) И меньшей интерпретируемостью (В моем блоге PCA об этом более подробно говорится в разделе «Пример, чтобы связать все вместе».).
Так что помните, что, хотя у нас есть инструмент для борьбы с проклятием размерности, использование этого инструмента обходится дорого. Ура!
Больше данных науки и аналитики Похожие сообщения:
Машинное обучение вики
In the coming weeks, this wiki’s URL will be migrated to the primary fandom.com domain. Read more here
Проклятие размерности
Проклятие размерности — проблема, связанная с экспоненциальным возрастанием количества данных из-за увеличения размерности пространства. Термин «проклятие размерности» был введен Ричардом Беллманом в 1961 году.
Проблема «проклятия размерности» часто возникает в машинном обучении, например, при применении метода ближайших соседей и метода парзеновского окна.
Содержание
Проблемы [ ]
«Проклятие размерности» особенно явно проявляется при работе со сложными системами, которые описываются большим числом параметров.
Это влечет за собой следующие трудности:
Пример [ ]
Рассмотрим единичный интервал [0,1]. 100 равномерно разбросанных точек будет достаточно, чтобы покрыть этот интервал с частотой не менее 0,01.
Теперь рассмотрим 10-мерный куб. Для достижения той же степени покрытия потребуется уже 10 20 точек. То есть, по сравнению с одномерным пространством, требуется в 10 18 раз больше точек.
Поэтому, например, использование переборных алгоритмов становится неэффективным при возрастании размерности системы.
Способы устранения «проклятия размерности» [ ]
Основная идея при решении проблемы — понизить размерность пространства, а именно спроецировать данные на подпространство меньшей размерности.
На этой идее, например, основан метод главных компонент.
Также можно осуществлять отбор признаков и использовать алгоритм вычисления оценок.
Глубокое обучение, проклятие размерности и автокодировщики
Автокодировщик (autoencoder) – это впечатляющий новый подход к машинному обучению без учителя. Во многих задачах данный подход позволил превзойти методы, наработанные в процессе многолетней практики ручного отбора признаков.
Предположим, что мы работаем над проектом по обработке изображений, и нашей задачей является создание алгоритма, способного идентифицировать эмоции, выраженные на лице человека. Мы хотим, чтобы наш алгоритм принимал на входе изображение в градациях серого размером 256×256 пикселей, а на выходе давал ответ, характеризующий выражение лица. Например, если передать алгоритму следующее изображение, мы ожидаем, что он классифицирует выражение лица, как «веселое».

Изображение веселого человека.
В целом, это вроде бы хороший подход, но прежде, чем мы на нем остановимся, давайте подумаем, что же он на самом деле означает. Изображение в градациях серого размером 256×256 соответствует входному вектору, содержащему более 65000 измерений! Другими словами, мы пытаемся решить задачу в 65000-мерном пространстве. Это не так просто сделать даже для компьютера! Многомерные входные данные не только сложно хранить, перемещать и обрабатывать, большая размерность также порождает некоторые другие серьезные проблемы.
Размерность экспоненциально усложняет решение задачи
Мы можем продемонстрировать описанную выше взаимосвязь графически. Алгоритм равномерно делит пространство признаков на интервалы и отображает все обучающие примеры. Затем каждому интервалу мы присваиваем метку, соответствующую классу, преобладающему в этом интервале. Наконец, чтобы классифицировать любой новый пример, необходимо лишь определить интервал, в который попадает этот пример!
Для нашей демонстрационной задачи вначале мы возьмем один признак (т.е. одномерный вход) и разобьем пространство этого признака на 3 интервала:

Простая задача с одномерным входом.
Мы видим, что классы существенно накладываются друг на друга, поэтому мы добавляем второй признак, чтобы улучшить отделимость классов. Однако если количество обучающих примеров останется прежним, мы получим сильно разреженные двумерные данные. На основе этих разреженных данных очень трудно будет установить какие-либо значимые взаимосвязи, если не увеличить количество обучающих примеров. Если мы перейдем к трехмерным входным данным, ситуация ухудшится еще больше, поскольку теперь мы будем заполнять еще большее количество ячеек пространства (3 3 = 27) тем же количеством обучающих примеров. Трехмерное пространство будет почти пустое!

С увеличением размерности разреженность увеличивается экспоненциально.
Важно отметить, что эту проблему невозможно легко решить с помощью более эффективных вычислений или модернизированного оборудования! Для многих задач машинного обучения сбор обучающих примеров является наиболее трудоемким этапом. Следовательно, описанная выше закономерность вынуждает нас обращать особое внимание на размерность данных. Если мы сможем преобразовать входные данные к достаточно малому количеству измерений, нерешаемая в исходной форме задача может стать вполне решаемой!
Отбор признаков вручную

Ключевые точки, определяющие выражение лица.
Этот подход позволяет нам существенно уменьшить размерность входных данных (с 65000 до примерно 60), но здесь есть определенные ограничения! Чтобы выработать эффективную методику ручного отбора признаков, могут потребоваться годы исследований. Кроме того, во многих случаях значимые признаки не так легко выразить. Например, очень трудно отобрать признаки для обобщенного распознавания объектов, где алгоритм должен эффективно классифицировать птиц, лица, автомобили и т.д. Так каким же образом мы можем извлечь из входных данных наиболее информативные измерения? Ответ на этот вопрос дает раздел машинного обучения, называемый обучением без учителя.
Далее мы рассмотрим автокодировщик – алгоритм машинного обучения без учителя, основанный на нейронной сети, который был впервые применен Джеффри Хинтоном (Geoffrey Hinton). Мы кратко рассмотрим принцип действия автокодировщика, а также сравним его с традиционными линейными подходами, такими как метод главных компонент (principal component analysis, PCA), применяемый в области компьютерного зрения, и латентно-семантический анализ (latent semantic analysis, LSA), применяемый в области обработки естественного языка.
Краткий обзор автокодировщика

Базовая структура автокодировщика.
Двумя основными компонентами автокодировщика являются две нейронные сети, одна из которых называется кодировщиком (encoder), а другая – декодировщиком (decoder). Кодировщик используется как во время обучения, так и во время применения, тогда как декодировщик используется только во время обучения. Задачей кодировщика является формирование сжатого представления входных данных. В нашем случае мы генерируем 30-мерное представление на основе 2000-мерных входных данных. Декодировщик представляет собой отражение кодировщика и предназначен для восстановления исходных данных с максимально возможной точностью. В процессе обучения декодировщик стимулирует формирование наиболее информативного сжатого представления. Чем точнее восстановленный вход соответствует оригиналу, тем лучше сжатое представление!
Давайте сравним автокодировщик с его линейными конкурентами. Рассмотрим ряд экспериментов, выполненных Хинтоном (Hinton) и Салахутдиновым (Salakhutdinov) в 2006 году на этапе дебюта технологии. Во-первых, давайте посмотрим, насколько точно автокодировщик и PCA способны восстановить оригинальные входные данные на основе 30-мерного сжатого представления.
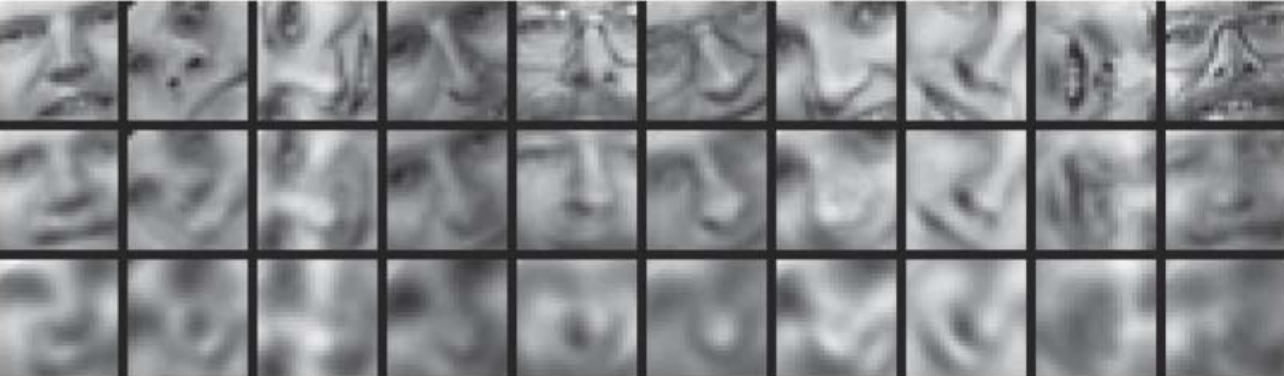
Сравнение точности восстановления исходных данных.
Верхний ряд – оригинальные входные изображения.
Средний ряд – результат восстановления с помощью автокодировщика.

Сравнение отделимости классов на основе двумерных представлений, сгенерированных с помощью PCA (слева) и автокодировщика (справа) для набора данных MNIST.
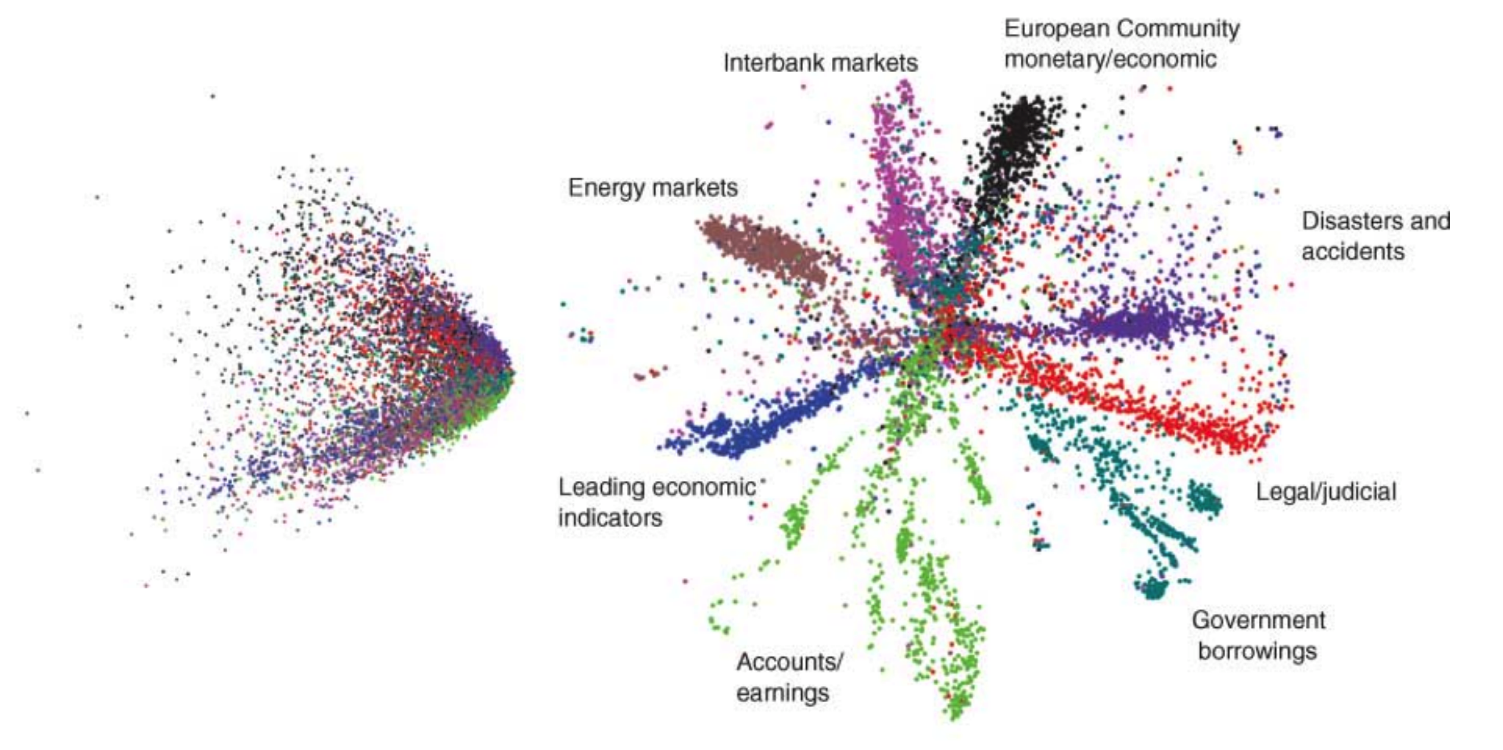
Сравнение отделимости классов на основе двумерных представлений, сгенерированных с помощью LSA (слева) и автокодировщика (справа) для набора новостных сообщений.
Заключение
Автокодировщик – это впечатляющая техника машинного обучения без учителя, во многих задачах позволившая превзойти методы ручного отбора признаков! В сегодняшней статье мы рассмотрели основы, являющиеся лишь вершиной айсберга. В следующей статье мы более подробно рассмотрим принципы работы автокодировщиков, эффективные методы их обучения и другие подходы, направленные на оптимизацию.