обучение с подкреплением машинное обучение
Введение в обучение с подкреплением для начинающих
Обучение с подкреплением в – это способ машинного обучения, при котором система обучается, взаимодействуя с некоторой средой.
В последние годы мы наблюдаем прогресс в исследованиях в данной области. Например DeepMind, Deep Q learning в 2014, победа чемпиона мира в Go с помощью алгоритма AlphaGo в 2016, OpenAl и PPO в 2017

В этой статье мы сфокусируемся на изучении различных архитектур, которые активно используются вместе с обучением с подкреплением в наши дни для решения различного рода проблем, а именно Q-learning, Deep Q-learning, Policy Gradients, Actor Critic и PPO.
Из этой статьи, вы узнаете:
Очень важно освоить все эти элементы, прежде чем погружаться в реализацию системы глубинного обучения с подкреплением.
Идея обучения с подкреплением заключается в том, что система будет учиться в среде, взаимодействовать с ней и получать вознаграждение за выполнение действий. 
Представьте, что вы ребенок в гостиной. Вы увидели камин и захотели подойти к нему. 
Тут тепло, вы хорошо себя чувствуете. Вы понимаете, что огонь – это хорошо. 
Но потом вы пытаетесь дотронуться до огня и обжигаете руку. Только что вы осознали, что огонь – это хорошо, но только тогда, когда находитесь на достаточном расстоянии, потому что он производит тепло. Если подойти слишком близко к нему, вы обожжетесь.
Вот как люди учатся через взаимодействие. Обучение с подкреплением – это просто вычислительный подход к обучению на основе действий.
Как выглядит обучение с подкреплением

Давайте в качестве примера представим, что система учится играть в Super Mario Bros. Процесс обучения с подкреплением может быть смоделирован как цикл, который работает следующим образом:
Этот цикл ОП выводит последовательность состояний, действий и вознаграждений.
Цель системы – максимизировать ожидаемое вознаграждение.
Главная идея гипотезы вознаграждения
Почему целью системы является максимизация ожидаемого вознаграждения?
Обучение с подкреплением основано на идее гипотезы вознаграждения. Все цели можно описать максимизацией ожидаемого вознаграждения.
Вознаграждение на каждом временном шаге (t) может быть записано как:
Что эквивалентно: 
Однако на самом деле мы не можем просто добавить такие награды. Награды, которые приходят раньше (в начале игры), более вероятны, так как они более предсказуемы, чем будущие вознаграждения.

Допустим, ваш герой – это маленькая мышь, а противник – кошка. Цель игры состоит в том, чтобы съесть максимальное количество сыра, прежде чем быть съеденным кошкой.
Как мы можем видеть на изображении, скорее всего мышь будет есть сыр рядом с собой, нежели сыр, расположенный ближе к кошке (т.к. чем ближе мы к кошке, тем она опаснее).
Как следствие, ценность награды рядом с кошкой, даже если она больше обычного (больше сыра), будет снижена. Мы не уверены, что сможем его съесть.
Перерасчет награды, мы делаем таким способом:
Мы определяем ставку дисконтирования gamma. Она должна быть в пределах от 0 до 1.
Ожидаемые вознаграждения можно рассчитать по формуле: 
Другими словами, каждая награда будет уценена с помощью gamma к показателю времени (t). По мере того, как шаг времени увеличивается, кошка становится ближе к нам, поэтому будущее вознаграждение все менее и менее вероятно.
Эпизодические или непрерывные задачи
У нас может быть два типа задач: эпизодические и непрерывные.
Эпизодические задачи
В этом случае у нас есть начальная и конечная точка. Это создает эпизод: список состояний, действий, наград и будущих состояний.
Например в Super Mario Bros, эпизод начинается с запуска нового Марио и заканчивается, когда вы убиты или достигли конца уровня.

Непрерывные задачи
Это задачи, которые продолжаются вечно. В этом случае система должна научиться выбирать оптимальные действия и одновременно взаимодействовать со средой.
Как пример можно привести систему, которая автоматически торгует акциями. Для этой задачи нет начальной точки и состояния терминала. Что касается нашей задачи, то герой будет бежать, пока мы не решим остановить его. 
Борьба методов: Монте-Карло против Временной разницы
Существует два основных метода обучения:
Монте-Карло
Когда эпизод заканчивается, система смотрит на накопленное вознаграждение, чтобы понять насколько хорошо он выполнил свою задачу. В методе Монте-Карло награды получают только в конце игры.
Затем, мы начинаем новую игру с новыми знаниями. С каждым разом система проходит этот уровень все лучше и лучше.
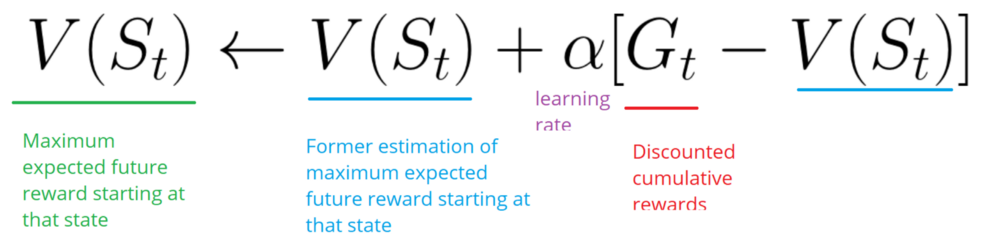
Возьмем эту картинку как пример:
Временная разница: обучение на каждом временном шаге
Этот метод не будет ждать конца эпизода, чтобы обновить максимально возможное вознаграждение. Он будет обновлять V в зависимости от полученного опыта.
Метод вызывает TD (0) или One step TD (обновление функции value после любого отдельного шага). 
Он будет только ждать следующего временного шага, чтобы обновить значения. В момент времени t+1 обновляются все значения, а именно вознаграждение меняется на Rt+1, а текущую оценка на V(St+1).
Разведка или эксплуатация?
Прежде чем рассматривать различные стратегии решения проблем обучения с подкреплением, мы должны охватить еще одну очень важную тему: компромисс между разведкой и эксплуатацией.
Помните, что цель нашей системы заключается в максимизации ожидаемого совокупного вознаграждения. Однако мы можем попасть в ловушку.

В этой игре, наша мышь может иметь бесконечное количество маленьких кусков сыра (+1). Однако на вершине лабиринта есть гигантский кусок сыра (+1000).
Но, если мы сосредоточимся только на вознаграждении, наша система никогда не достигнет того самого большого куска сыра. Вместо этого она будет использовать только ближайший источник вознаграждений, даже если этот источник мал (эксплуатация).
Но если наша система проведет небольшое исследование, она найдет большую награду.
Это то, что мы называем компромиссом между разведкой и эксплуатацией. Мы должны определить правило, которое поможет справиться с этим компромиссом.
Три подхода к обучению с подкреплением
Теперь, когда мы определили основные элементы обучения с подкреплением, давайте перейдем к трем подходам для решения проблем, связанных с этим обучением.
На основе значений
В обучении с подкреплением на основе значений целью является оптимизация функции V(s).
Функция value – это функция, которая сообщает нам максимальное ожидаемое вознаграждение, которое получит система.
Значение каждой позиции – это общая сумма вознаграждения, которую система может накопить в будущем, начиная с этой позиции.
Система будет использовать эту функцию значений для выбора состояния на каждом шаге. Она принимает состояние с наибольшим значением.

На основе политики
В обучении с подкреплением на основе политики мы хотим напрямую оптимизировать функцию политики π (s) без использования функции значения.
Политика – это то, что определяет поведение системы в данный момент времени.
Это позволяет нам сопоставить каждую позицию с наилучшим действием.
Существует два типа политики:

Как можно заметить, политика прямо указывает на лучшие действия для каждого шага.
На основе модели
В подходе на основании модели мы моделируем среду. Это означает, что мы создаем модель поведения среды.
Проблема каждой среды заключается в том, что понадобятся различные представления данной модели. Вот почему мы особо не будем раскрывать эту тему.
В этой статье было довольно много информации. Убедитесь, что действительно поняли весь материал, прежде чем продолжить изучение. Важно освоить эти элементы перед тем как начать самую интересную часть: создание ИИ, который играет в видеоигры.
Машинное обучение с подкреплением через соревновательные нейронные сети
В классической игре «крестики-нолики» существует возможность представить все вероятные ходы — и никогда не проигрывать. Эту возможность я использовал как метрику своего обучения нейронной сети игре.
Обучение с подкреплением будет полезным для задач с принятием неоднозначного решения, осложнённого из-за множества вариантов выбора действия с различными исходами для каждого.
Конечно крестики-нолики не похожи на сложную игру, чтобы обучать их подкреплением. Однако, она хорошо подходит для освоения методики обучения через соревновательные сети, которая позволит улучшить качество и сократить время на обучение сети.
Далее я опишу общий алгоритм обучения с подкреплением через соревновательные сети в контексте игры крестики-нолики с демонстрацией обученной сети делать “осмысленные” ходы, то есть играть.
Также можно ввести предобученную модель из GitHub по нажатию на соответствующую кнопку, чтобы сразу начать испытывать нейронную сеть.
Первые шаги в обучении нейронных сетей
Помимо того, что нейрон имеет функцию активации, которая вносит поправки в результирующее решение нейронной сети, можно также сказать, что нейроны — это память сети.
Каждый слой увеличивает время на обучение из-за распространения обратной ошибки по слоям “вверх”, и сигнал при этом постепенно затухает, прежде чем дойдёт до “верхних” слоёв, которые начинают путь принятия решения.
После нескольких вариантов настроек сети я пришёл в выводу, что для простой игры с полем 3х3 будет достаточно использовать однослойную сеть с 128 нейронами.
Памяти у сети не должно быть слишком много, это может привести к переобучению — полному запоминанию всех вариантов исхода игры.
Сила нейронных сетей в выразительности аппроксимации решения на основе входных данных в условиях ограниченности памяти.
Общие правила поощрения агентов
Для относительного прогноза нейронной сетью, каждая ячейка имеет динамическую награду в зависимости от её значимости для агента на текущий момент.
На выходе нейронная сеть прогнозирует индекс ячейки, куда будет ходить агент.
Соревновательное обучение нейронных сетей
На соревновании агенты будут обучаться в условиях конкуренции, что приведёт к новым исходам игры и улучшит качество обучения для новых ситуаций.
Для каждого агента выделено собственное поле, чтобы тренироваться ходить в свободную ячейку и выстраивать победные комбинации ходов.
Агенты играют 9 игр у себя, далее переходят для 1 игры на соревновательное поле, где игра ведётся до победного с ограничением в 9 ходов, затем всё повторяется заново.
По окончании каждой игры обе сети обучаются на новом опыте соперничества на общем игровом поле.
Предотвращение победы соперника
Сеть нужно обучить соперничать за победу на поле, т.е. поощрять за успешные предотвращения победы соперника, увеличивая награду ячейки.
Еще одной метрикой обучения нейронных сетей являются показатели побед в соревнованиях. Если отрыв побед одного игрока слишком большой, то вероятно сеть обучается неправильно, и причиной тому неверные награды за действия агентов, либо не учтены ещё какие-либо действия и их награды. Наилучшим результатом обучения можно считать ситуацию, когда сети будут идти почти на равных, побеждая и проигрывая примерно одинаковое количество раз.
Соревновательное обучение с человеком
Реализация обучения нейронной сети игре с человеком мало отличается от соревнований между агентами. Единственное серьёзное отличие состоит в том, что человек изначально играет разумно. Партия с таким соперником создаёт дополнительные ситуации для агента, что благоприятно скажется на его игровом опыте и, соответственно, на обучении.
Завершение
Нейронная сеть обучилась играть в крестики-нолики только после введения соревновательного алгоритма, что позволило ей научиться делать ходы в ответ на ходы соперника, хоть и не идеально, как планировалось изначально.
В целом, считаю проект успешно завершённым — цель достигнута.
Введение в различные алгоритмы обучения с подкреплением (Q-Learning, SARSA, DQN, DDPG)
(Q-learning, SARSA, DQN, DDPG)
Обучение с подкреплением (RL далее ОП) относится к разновидности метода машинного обучения, при котором агент получает отложенное вознаграждение на следующем временном шаге, чтобы оценить свое предыдущее действие. Он в основном использовался в играх (например, Atari, Mario), с производительностью на уровне или даже превосходящей людей. В последнее время, когда алгоритм развивается в комбинации с нейронными сетями, он способен решать более сложные задачи.
В силу того, что существует большое количество алгоритмов ОП, не представляется возможным сравнить их все между собой. Поэтому в этой статье будут кратко рассмотрены лишь некоторые, хорошо известные алгоритмы.
1. Обучение с подкреплением
Типичное ОП состоит из двух компонентов, Агента и Окружения.

Окружение – это среда или объект, на который воздействует Агент (например игра), в то время как Агент представляет собой алгоритм ОП. Процесс начинается с того, что Окружение отправляет свое начальное состояние (state = s) Агенту, который затем, на основании своих значений, предпринимает действие (action = a ) в ответ на это состояние. После чего Окружение отправляет Агенту новое состояние (state’ = s’) и награду (reward = r) Агент обновит свои знания наградой, возвращенной окружением, за последнее действие и цикл повторится. Цикл повторяется до тех пор, пока Окружение не отправит признак конца эпизода.
Большинство алгоритмов ОП следуют этому шаблону. В следящем параграфе я кратко расскажу о некоторых терминах, используемых в ОП, чтобы облегчить наше обсуждение в следующем разделе.
Определения:
1. Action (A, a): все возможные команды, которые агент может передать в Окружение (среду)
2. State (S,s): текущее состояние возвращаемое Окружением
3. Rewrd (R,r): мгновенная награда возвращаемое Окружением, как оценка последнего действия
5. Value (V) или Estimate (E) : ожидаемая итоговая (награда) со скидкой, в отличии от мгновенной награды R, является функцией политики Eπ(s) и определяется, как ожидаемая итоговая награда Политики в текущем состоянии s. (Встречается в литературе два варианта Value – значение, Estimate – оценка, что в контексте предпочтительней использовать E – оценка. Прим. переводчика)
6. Q-value (Q): оценка Q аналогична оценки V, за исключением того, что она принимает дополнительный параметр a (текущее действие). Qπ(s, a) является итоговой оценкой политики π от состояния s и действия a
 * MCTS (Монте-Карло тайм степ модель), on-policy (алгоритм, где Агент включен в политику, т.е. обучается на основе действий, производных от текущей политики), off-policy (Агент обучается на основе действий, полученных от другой политики
* MCTS (Монте-Карло тайм степ модель), on-policy (алгоритм, где Агент включен в политику, т.е. обучается на основе действий, производных от текущей политики), off-policy (Агент обучается на основе действий, полученных от другой политики
Безмодельные алгоритмы против алгоритмов базирующихся на моделях
С другой стороны, безмодельные алгоритмы опираются на метод проб и ошибок для обновления своих знаний. В результате им не требуется место для хранения комбинаций состояние / действие и их оценок.
2. Разбор Алгоритмов
2.1. Q-learning
Q-learning это не связанный с политикой без модельный алгоритм ОП, основанный на хорошо известном уравнении Беллмана:
Мы можем переписать это уравнение в форме Q-value:
Оптимальное значение Q, обозначенное как Q*, может быть выражено как:
Цель состоит в том, чтобы максимизировать Q-значение. Прежде чем углубиться в метод оптимизации Q-value, я хотел бы обсудить два метода обновления значений, которые тесно связаны с Q-learning.
Итерация политики
Итерация политики представляет собой цикл между оценкой политики и ее улучшением.

Оценка политики оценивает значения функции V с помощью «жадной политики» полученной в результате последнего улучшения политики. С другой стороны, улучшение политики обновляет политику, генерирующую действия (action – a), что максимизирует значения V для каждого состояния (окружения). Уравнения обновления основаны на уравнении Беллмана. Итерации продолжаются до схождения.
Итерация Оценок (V)
Итерация оценок содержит только один компонент, который обновляет функцию оценки значений V, на основе Оптимального уравнения Беллмана.
После того, как итерация сходится, оптимальная политика напрямую выводится путем применения функции максимального аргумента для всех состояний.
Обратите внимание, что эти два метода требуют знания вероятности перехода p, что указывает на то, что это алгоритм на основе модели. Однако, как я упоминал ранее, алгоритм, основанный на модели, страдает проблемой масштабируемости. Так как же Q-Learning решает эту проблему?
Здесь a (альфа) скорость обучения (т.е. как быстро мы приближаемся к цели) Идея Q-learning во многом основана на итерациях оценок (v). Однако уравнение обновления заменяется приведенной выше формулой. В результате нам больше не нужно думать о вероятности перехода (p).
Обратите внимание, что следующее действие a’ выбирается для максимизации Q-значения следующих состояний вместо того, чтобы следовать текущей политике. В результате Q-learning относится к категории вне политики (off-Policy).
2.2. State-Action-Reward-State-Action (SARSA)
SARSA очень напоминает Q-learning. Ключевое отличие SARSA от Q-learning заключается в том, что это алгоритм с политикой (on-policy). Это означает, что SARSA оценивает значения Q на основе действий, выполняемых текущей политикой, а не жадной политикой.
Уравнения ниже показывают разницу между рассчетом значений Q
Где действие at+1 – это действие выполняемое в следующем состоянии st+1 в соответствии с текущей политикой.
Они выглядят в основном одинаково, за исключением того, что в Q- learning мы обновляем нашу Q-функцию, предполагая, что мы предпринимаем действие a, которое максимизирует нашу Q-функцию в следующем состоянии Q (st + 1, a).
В SARSA мы используем ту же политику (например, epsilon-greedy), которая сгенерировала предыдущее действие a, чтобы сгенерировать следующее действие, a + 1, которое мы запускаем через нашу Q-функцию для обновлений, Q (st + 1, at+1). (Вот почему алгоритм получил название SARSA, State-Action-Reward-State-Action).
В Q-learning у нас нет ограничений на то, как выбирается следующее действие a, у нас есть только оптимистичный взгляд на то, что все последующие выборы действий a в каждом состоянии s будут оптимальными, поэтому мы выбираем действие a, чтобы максимизировать оценку Q (st+1, a). Это означает, что с помощью Q-learning мы можем генерировать данные политикой с любым поведением (обученной, необученной, случайной и даже плохой), при наличии достаточной выборки мы получим оптимальные значения Q
2.3. Deep Q Network (DQN)
аваВ 2013 году DeepMind применил DQN к игре Atari, как показано на рисунке выше. Входными данными является необработанное изображение текущей игровой ситуации. Оно проходит через несколько сверхточных слоев, а затем через полно связный слой. Результатом является Q-значение для каждого действия, которое может предпринять агент.
Вопрос сводится к следующему: как мы обучаем сеть?
Ответ заключается в том, что мы обучаем сеть на основе уравнения обновления Q-learning. Напомним, что целевое значение Q для Q-learning:
φ эквивалентно состоянию s, в то время как θ обозначает параметры в нейронной сети, что не входит в область нашего обсуждения. Таким образом, функция потерь для сети определяется как квадрат ошибки между целевым значением Q и выходным значением Q из сети.
Еще два метода также важны для обучения DQN:
1. Воспроизведение опыта: поскольку обучающие батчи в типичной настройке ОП(RL) сильно коррелированы и менее эффективны для обработки данных, это приведет к более сложной конвергенции для сети. Одним из способов решения проблемы выборки батчей является воспроизведение опыта. По сути, батчи переходов сохраняются, а затем случайным образом выбираются из «пула переходов» для обновления знаний.
2. Отдельная целевая сеть: целевая сеть Q имеет ту же структуру, что и сеть, которая оценивает значение. Каждый шаг C, в соответствии с приведенным выше псевдокодом, целевая сеть принимает значения основной сети. Таким образом, колебания становятся менее сильными, что приводит к более стабильным тренировкам.
2.4. Deep Deterministic Policy Gradient (DDPG)
Хотя DQN добилась огромных успехов в задачах более высокой размерности, таких как игра Atari, пространство действий по-прежнему остается дискретным. Однако для многих задач, представляющих интерес, особенно для задач физического контроля, пространство действий непрерывно. Если вы слишком дискретизируете пространство действия, вы получите слишком большой объем. Например, предположим, что степень свободной случайной системы равна 10. Для каждой степени вы делите пространство на 4 части. У вас будет 4¹⁰ = 1048576 действий. Чрезвычайно сложно получить схождение для такого большого пространства действий, а это еще не предел.
Критик используется для оценки функции политики Актора в соответствии с ошибкой временной разницы (TD)
Здесь u обозначает политику Актора. Знакомо? Да! Это похоже на уравнение обновления Q-learning. TD-learning – это способ научиться предсказывать значение в зависимости от будущих значений данного состояния. Q-learning это особый тип TD-learning для получения Q значений
DDPG также заимствует идеи воспроизведения опыта и отдельной целевой сети от DQN. Другой проблемой для DDPG является то, что он редко выполняет поиск действий. Решением для этого является добавление шума в пространство параметров или пространство действий (action).
Слева шум добавлен к действиям, справа к параметрам
Утверждается, что добавление шума в пространство параметров лучше, чем в пространство действий, согласно статье написанной на OpenAI.